こちらのブログは個人ブログと同じ内容です
Linux を CLI から操作している時に、ログや CSV などのテキストファイルなどの内容を確認するためのコマンドがいくつかありますが、less コマンドがなかなか使い勝手が良いので紹介します。
less とは
less は Unix 系のコマンドで、テキストファイルの内容を閲覧するためのコマンドです。
- less は more の機能を拡張したコマンド(見た感じは一緒)
- tail より使い勝手が良い(開いてから検索できる など)
- エディタではないので、うっかり中身を変更してしまうことがない
- メモリほとんど消費しない(実行時にファイル内容をすべて読み込まないため)
基本的な使い方
less コマンドはテキストファイルの内容を閲覧するためのコマンドなので「開く」そして「読み進める」これだけです。 とてもシンプルなので簡単です。
ファイルを開く
less <FILE_PATH>
ファイルを開いた後は、以下のキーで操作できます。
- j 一行進む
- k 一行戻る
- d 半ページ進む
- u 半ページ戻る
- f 1ページ進む
- b 1ページ戻る
- g 先頭行へ飛ぶ
- G 最終行へ飛ぶ
- <number>g 入力した行(<number>行目)へ飛ぶ
- q 終了する
検索
ファイルの中身が大量にある時など、1行ずつ見ていくと埒が明かないので探したい部分を検索にかけることができます。
ファイルを開いた後で、検索をかけると、ヒットした最初の行を先頭としてページが表示されます。
検索ワードには正規表現も記述可能です。
- 現在のページ以降を検索
-
/<search_word>
- 現在のページ以前を検索
-
?<search_word>
検索後は以下のキーでも操作できるようになります。
- n 現在地の次にヒットした行へ進む
- N 現在地の前にヒットした行へ戻る
検索にヒットしたものだけを表示させる
検索にヒットしたものだけを表示させることもできます。 & キーを入力後、検索ワードを入力します。
&<search_word>
表示を元に戻すには再度 & キーを入力し、検索ワードは入力せずに [ENTER] 押下で戻ります。
※ ファイルの大きさによってその分 CPU に負荷がかかるので注意
行番号を表示する
ファイルを開いた後で -N を入力すると、行番号を表示できます。
行番号表示前

行番号表示後

行番号を非表示にする時も同じです。もう一度 -N を入力すると非表示になります。
※ ファイルの大きさによってその分 CPU に負荷がかかるので注意
現在地情報を表示する
例えば大量の行数のあるファイルを上からなめている時に、今どの辺にいるのかがわからなくなりますが、 -M を入力すると、以下の情報が表示されるようになり、現在地が気になる場合には役に立ちます。
- 現在表示されているものが何行目から何行目までか
- 総行数
- 現在地が総行数に対してどの辺りにいるか(パーセンテージ)

行の折り返し操作
1行がコンソール画面の横幅より長い場合は折り返されますが、-S を入力すると「折り返す」「折り返さない」を切り替えられます。
折り返す(デフォルト)
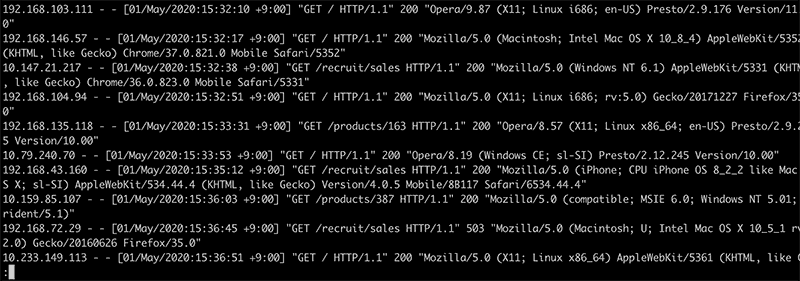
折り返さない
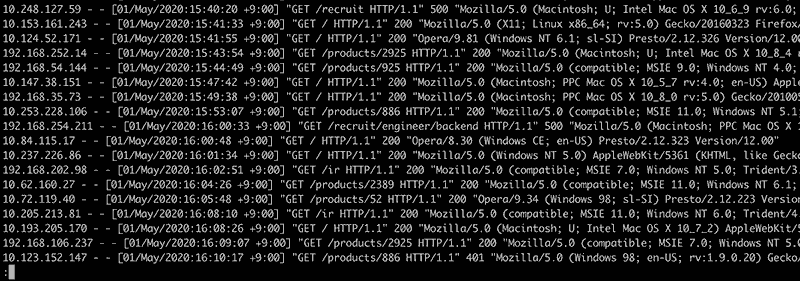
折り返さないと表示がスッキリして良いですね。ただし横スクロールはできないので、1行すべてを見なくて良い場合などで使います。
ビープー音を鳴らさない
先頭行から更に上に戻ろうとした場合や、最終行まで来た時に更に下に進もうとする場合にビープー音がなりますが、微妙にストレスなので音を止めたい時があります。
その時は -q を入力すると ON/OFF ができます。
リアルタイムでログを監視する
tail -f コマンドなどでリアルタイムにログを閲覧できますが、less コマンドでも可能です。
less では F を入力すると監視状態に入ります。

ctrl + c で監視状態が解除されるので、そこから検索したりできます。
監視状態を解除した後でも、再度 F を入力すれば監視状態になります。
閲覧自体を終了させたい場合は ctrl + c からの q で終了できます。
オプション
上記の操作は less コマンド実行時にオプションをつけて実行する事もできます。
- 行数を表示する
-
less -N <file_name>
- 指定した行から表示させる
-
# 書式
less +<line> <file_name>
# 10 行目から表示開始
less +10 access_log - 検索する文字列を指定する
-
# 書式
less +/<search_word> <file_name>
# p オプションも同じ
less -p<search_word> <file_name> - リアルタイムで入力を監視する
-
less +F <file_name>
-
tail -f <file_name> | grep -e xxx -e xxx
みたいに grep で監視できないのがちょっと残念
他のコマンドの実行結果を閲覧する
パイプを使って他のコマンドの実行結果を読むこともできます。
<some command> | less
例えば、圧縮したログを読む時などパイプで less へ渡してあげるとスムーズに確認できます。
gzip -dc xxx.gz | less
(ちなみに gz ファイルは パイプで渡さなくても less xxx.gz で読めます)
まとめ
less コマンドは、操作が直感的でわかりやすいのが良い点だと思います。
メモリ消費の部分も、試しに 100万件 1.6GB のログファイルを読んでみたけどメモリ消費はほぼありませんでした。(1画面分だけ読み込むため)
% wc access_log
10000000 190901510 1684049674 access_log
% ls -lhS
1.6G 4 29 17:46 access_log
% ps aux | grep access_log
%CPU %MEM
0.0 0.0 less access_log
ただし less コマンドに限った事ではありませんが、大きすぎるファイルを検索したり採番したりすると CPU に負荷がかかるので注意は必要です。
結構使いやすいので、試してみてください。









