この記事は個人ブログと同じ内容です
www.ritolab.com
CloudWatch Logs では、AWS のコンソールからログデータを S3 にエクスポートできます。
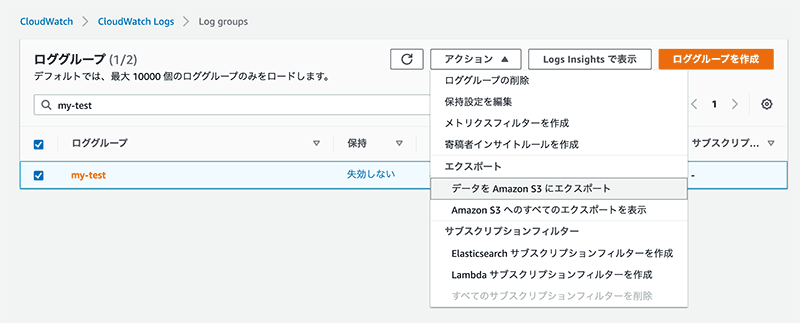
全ログデータを CloudWatch 側で保持して、ログデータを抽出する必要があった場合は都度 S3 にエクスポートして使うっていう運用ならこれで問題ないと思います。
別のケースとして、以下のような場合は、CloudWatch Logs から S3 に定期的にログを自動で配信する仕組みが欲しくなります。
- CloudWatch Logs のログデータを活用するために全てのデータを S3 にも溜めたい(データレイク的なあれ)
- CloudWatch Logs 側のログデータ保持は限定的(数カ月間だけとか)にするけど、過去全てのログデータは S3 に保管しておきたい(Glacier で氷漬けにする的なあれ)
今回は、CloudWatch Logs のログデータを自動で S3 に配信してみます。
CloudWatch Logs のログデータを S3 に配信するためには、Kinesis Data Firehose を使うとサクッといけます。
Amazon Kinesis Data Firehose
https://aws.amazon.com/jp/kinesis/data-firehose/
Amazon Kinesis Data Firehose は、ストリーミングデータをデータレイクやデータストア、分析サービスに確実にロードする最も簡単な方法を提供するサービスです。
ストリーミングデータを取り込んで変換し、Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、汎用 HTTP エンドポイント、さらに Datadog、New Relic、MongoDB、Splunk のようなサービスプロバイダーに配信できます。
流れとしては以下になります。
- CloudWatch Logs から Kinesis Data Firehose にログデータを送信
- Kinesis Data Firehose から S3 にログデータを配信
CloudWatch Logs にはサブスクリプションフィルタという機能があり、これを設定する事で Kinesis Data Firehose にログデータを送信できるようになります。
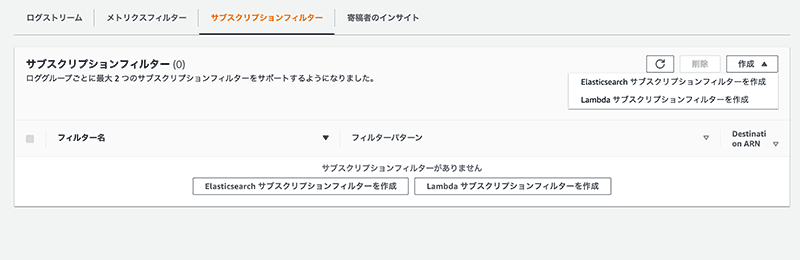
しかしながらキャプチャを見ての通り、AWS コンソールからは Elasticsearch もしくは Lambda のサブスクリプションフィルタしか作成できません。(2021年1月16日現在)
なので、Kinesis へのサブスクリプションフィルタを作成するためには AWS CLI などを使用する必要があります。
そういう理由もあり今回は AWS コンソール画面ではなく Terraform(AWS に対応したインフラオーケストレーションツール)を使って一連の仕組みを構築していこうと思います。
Terraform
https://www.terraform.io/
S3 サブスクリプションフィルタ以外は AWS コンソール画面からも作成できるので、この記事の前半はすっ飛ばせます。
ロググループと S3 バケットの作成
main.yml
resource "aws_cloudwatch_log_group" "my_test" {
name = "my-test"
}
resource "aws_s3_bucket" "cloud_watch_logs" {
bucket = "my-test-logs"
acl = "private"
}
Kinesis Data Firehose 配信ストリームの作成
まずは S3 への配信が行えるように Kinesis 用の IAM Role を作成します。
main.yml
resource "aws_iam_role" "kinesis_data_firehose_send_log_to_s3" {
name = "tf-KinesisFirehoseServiceRole-my-test"
assume_role_policy = file("aws_iam_role_kinesis_data_firehose.json")
}
resource "aws_iam_policy" "kinesis_data_firehose_send_log_to_s3" {
name = "tf-KinesisFirehoseServicePolicy-my-test"
policy = templatefile("aws_iam_policy_kinesis_data_firehose", {
aws_id = var.aws_id
region = var.region
bucket_arn = aws_s3_bucket.my_test.arn
cloudwatch_logs_arn = aws_cloudwatch_log_group.my_test.arn
})
}
resource "aws_iam_role_policy_attachment" "kinesis_data_firehose_send_log_to_s3" {
role = aws_iam_role.kinesis_data_firehose_send_log_to_s3.name
policy_arn = aws_iam_policy.kinesis_data_firehose_send_log_to_s3.arn
}
読み込んでいるポリシーのファイルはそれぞれ以下
aws_iam_role_kinesis_data_firehose.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "firehose.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"${bucket_arn}",
"${bucket_arn}/*"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"${cloudwatch_logs_arn}"
]
},
{
"Sid": "",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:GetShardIterator",
"kinesis:GetRecords",
"kinesis:ListShards"
],
"Resource": "arn:aws:kinesis:${region}:${aws_id}:stream/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:${region}:${aws_id}:key/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
],
"Condition": {
"StringEquals": {
"kms:ViaService": "kinesis.${region}.amazonaws.com"
},
"StringLike": {
"kms:EncryptionContext:aws:kinesis:arn": "arn:aws:kinesis:${region}:${aws_id}:stream/%FIREHOSE_POLICY_TEMPLATE_PLACEHOLDER%"
}
}
}
]
}
Kinesis Data Firehose 側の配信ストリームを作成します。
main.yml
resource "aws_kinesis_firehose_delivery_stream" "s3_stream" {
name = "tf-my-test-send-log-from-cwl-to-s3-stream"
destination = "extended_s3"
extended_s3_configuration {
bucket_arn = aws_s3_bucket.my_test.arn
role_arn = aws_iam_role.kinesis_data_firehose_send_log_to_s3.arn
buffer_size = 10
buffer_interval = 300
compression_format = "UNCOMPRESSED"
s3_backup_mode = "Disabled"
}
}
- destination には S3 を宛て先とするので extended_s3 を指定します
- buffer_size は MB 単位です。今回の設定の場合は、受信バッファーが 10MB に到達したら buffer_interval に関係無く S3 に配信します。
- buffer_interval は 秒単位です。今回の設定の場合は、5 分経過したら(=5分おきに)buffer_size に関係無く S3 に配信します。
- compression_format は圧縮についての設定ですが、CloudWatch Logs のサブスクリプションフィルタを介して Kinesis に送信されるログは Base64 エンコードされて gzip に圧縮されるので、ここでの圧縮は不要です。
サブスクリプションフィルタのための IAM Role 作成
CloudWatch Logs のサブスクリプションフィルタを作成するにあたり、必要なロールを作成しておきます。
main.yml
resource "aws_iam_role" "cloud_watch_logs_send_log_to_kinesis" {
name = "tf-CloudWatchLogsServiceRole-my-test-send-log-to-kinesis"
assume_role_policy = templatefile("aws_iam_role_cloud_watch_logs_send_log_to_kinesis.json", {
region = var.region
})
}
resource "aws_iam_policy" "cloud_watch_logs_send_log_to_kinesis" {
name = "tf-CloudWatchLogsServicePolicy-my-test-send-log-to-kinesis"
policy = templatefile("aws_iam_policy_cloudwatch_logs_send_log_to_kinesis.json", {
kinesis_data_firehouse_arn = aws_kinesis_firehose_delivery_stream.s3_stream.arn
})
}
resource "aws_iam_role_policy_attachment" "cloud_watch_logs_send_log_to_kinesis" {
role = aws_iam_role.cloud_watch_logs_send_log_to_kinesis.name
policy_arn = aws_iam_policy.cloud_watch_logs_send_log_to_kinesis.arn
}
読み込んでいるポリシーのファイルはそれぞれ以下
aws_iam_role_cloud_watch_logs_send_log_to_kinesis.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.${region}.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
aws_iam_policy_cloudwatch_logs_send_log_to_kinesis.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"firehose:PutRecord",
"firehose:PutRecordBatch"
],
"Resource": [
"${kinesis_data_firehouse_arn}"
]
}
]
}
ここまでサブスクリプションフィルタ設定の前の準備として Terraform での設定を書きましたが、これらは AWS コンソール画面からでも作成できます。
次の S3 サブスクリプションフィルタ作成が、前述の通り AWS CLI かその他 Terraform 等のツールで行う必要があります。
CloudWatch Logs S3 サブスクリプションフィルタの作成
S3 サブスクリプションフィルタを作成します。
main.yml
resource "aws_cloudwatch_log_subscription_filter" "s3" {
name = "tf-my-test-s3-subscription-filter"
role_arn = aws_iam_role.cloud_watch_logs_send_log_to_kinesis.arn
log_group_name = aws_cloudwatch_log_group.my_test.name
destination_arn = aws_kinesis_firehose_delivery_stream.s3_stream.arn
filter_pattern = ""
}
filter_pattern(フィルターパターン)について、ここには何も記述していないですが、この場合は全てのログイベントに一致(=全てのログが対象)します。
これを例えば、「ELB のヘルスチェックは除外したい」の場合は以下のように設定する事で kinesis への送信を行わないようにできます。
filter_pattern = "-\"ELB-HealthChecker/2.0\""
フィルターとパターンの構文
docs.aws.amazon.com
動作確認
S3 サブスクリプションフィルタを CloudWatch Logs に設定できたので、S3 を確認してみます。
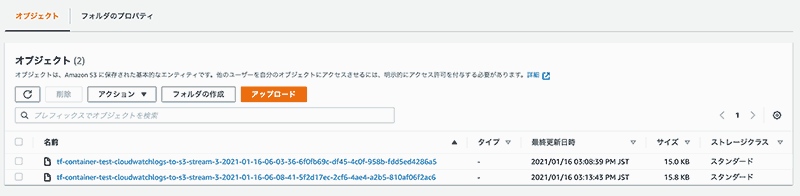
S3 にログが配信された事が確認できました。
ちなみにこれを S3 Select で見てみると
{
"messageType": "DATA_MESSAGE",
"owner": "xxxxxxxx",
"logGroup": "/my-test",
"logStream": "php/sample/4478f375fl19400daf513cb5b0cd77a9",
"subscriptionFilters": [
"tf-my-test-s3-subscription-filter"
],
"logEvents": [
{
"id": "123456789...",
"timestamp": 1610777406264,
"message": "[2021-01-16 15:10:06] local.INFO: message test. {\"type\":\"info\"} \n"
},
{
"id": "123456789...",
"timestamp": 1610777406264,
"message": "[2021-01-16 15:10:06] local.WARNING: message test. {\"type\":\"warning\"} \n"
}
]
},
{
"messageType": "DATA_MESSAGE",
"owner": "xxxxxxxx",
"logGroup": "/my-test",
"logStream": "nginx/sample/44k86375f03b410daf513p2xb0cd77a9",
"subscriptionFilters": [
"tf-my-test-s3-subscription-filter"
],
"logEvents": [
{
"id": "123456789...",
"timestamp": 1610777410150,
"message": "12.3.45.57 - - [16/Jan/2021:15:10:10 +0900] \"GET /sample/1 HTTP/1.1\" 200 17486 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36\" \"123.45.67.89\""
}
]
}
問題なく配信されてきているようですね。
コストどんな感じだろう
とはいえ、kinesis もお高いんでしょう?という気持ちになったので、CloudWatch ログデータ保存と S3 のデータ保存、そして Kinesis Data Firehose の取り込みデータ料金を見てみました。(2021/01/16時点・東京リージョン)
- CloudWatch Logs(ログデータ保存)
- S3 標準(ストレージ 〜 50TB)
- S3 Glacier(〜 50TB)
- Kinesis Data Firehose(取込データ量 最初の 500 TB/月)
aws.amazon.com
aws.amazon.com
aws.amazon.com
「ログデータはサービスが終了するまで永久に持ち続ける」とした場合に、まあふつうに考えたら Kinesis 稼働分のコストもあるので CloudWatch Logs のみを使い続けた方がコストは安いようにも思えるけど、例えば、以下のような使い方をした場合
- CloudWatch Logs
- Kinesis Data Firehose
- S3
- kinesis から配信されたログデータは 標準 に格納後、3 ヶ月後に Glacier へ移動
この構成だと、7 ヶ月後にはコストがトントンになって、8 ヶ月後には CloudWatch Logs のみで運用するよりも月額のコストが安くなった。(参考程度なのできちんとした試算は各自でお願いします)
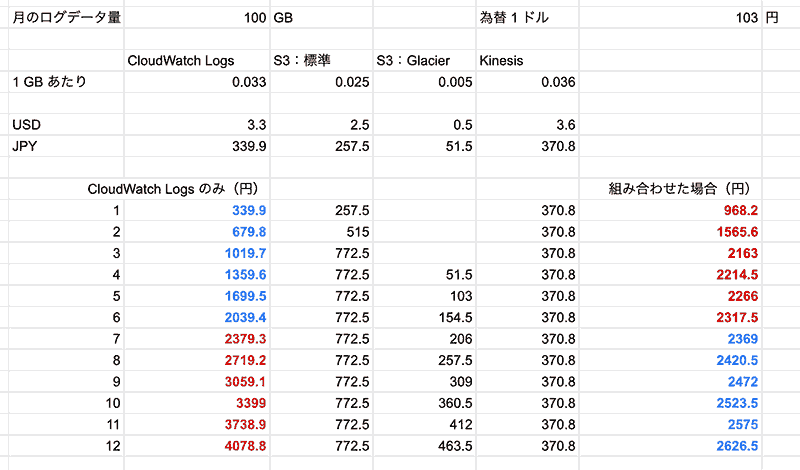
永久に持ち続けないとしても年単位では持つと思うので、そう考えてもお得かな。ログデータはサービスが動いている以上永延に溜まるし、Glacier 様々という結論に至りました。(あんまり本筋とは関係ない結論)
まとめ
AWS にログデータを溜める時には Glacier を上手く活用しましょう。
ともあれ CloudWatch Logs から S3 へログデータをそっと配信できたのでこれにて終了です。