この記事は個人ブログと同じ内容です
概要
chart.jsのデータセットの絞り込みをLegend(凡例)のクリックではなくて、chart.jsのコンポーネント外のインプットから行うサンプルを作ってみた。
まとめ
chart.js の表現を超えた凝った表現をする場合は、なかなか面倒そうだということがわかった。
(今回のサンプル以外に、やりたいことあったけど、調べてるうちに作るより、デザインや受け入れ要件と調整するほうが楽やろ!もしくはスクラッチで作ったほうが早いやんか!となったので)
本来の目的は楽することなので、それを忘れないようにしたい。
本題
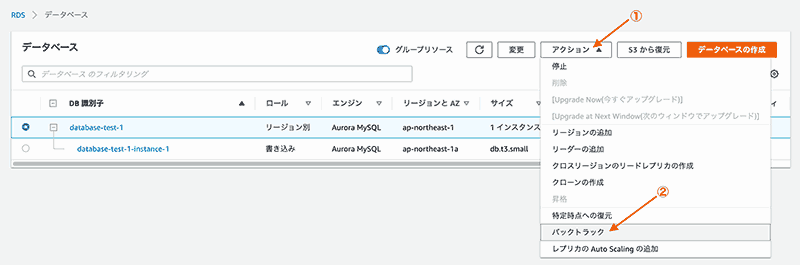
chartjsのデフォルトだと、上記のような凡例をクリックする事により表示項目を絞ることができるが、
下記のように絞り込みのUIを chartjs のコンポーネントから引き剥がしたかったため、試しに作ってみた。
おまけで、カテゴリごとに表示項目絞るみたいなこともできるようになった。
(野菜だけ表示するみたいなことができる)
コードはこちらにおいてます
https://codesandbox.io/s/chartjs-toggle-datasets-outer-input-mh0r6
外部から、Legendのフィルタ情報を渡してdatasetをフィルタすることはできなかった。
chartjs にデフォルトで用意されてるだろうと調べてみたけど、入ってなかった。
凡例からのフィルタらしきものをoptions.legend.labels.filter見つけたが、これは、凡例のラベルをフィルタするものであって、凡例のラベルをクリックしたときのdatasetのフィルタには全く関係がなかった。
https://www.chartjs.org/docs/latest/configuration/legend.html#legend-label-configuration
propsで datasets を渡す際に、 外でフィルタした状態のdatasetsを渡す方針に変更
chartjsに用意されてない昨日だとわかった & chartjsを拡張するほど力をかけたくないので、簡単そうな方法「そもそもフィルタしたdatasets渡したらええやん」にきりかえた。
(「力かけたくないなら デフォルトの凡例クリックでのフィルタでいいじゃん」には耳をふさぎます。)
できたもの
やってることは単純で、
- filter用の配列(filterItem)をdataに持つ
- filterItemはinputや、methodで変え放題
- 表示したいdataをchartのコンポーネントに渡す際に、filterItemでフィルタして渡す
https://codesandbox.io/s/chartjs-toggle-datasets-outer-input-mh0r6
<template> <div> <button @click="fillData()">Randomize</button> <hr /> <button @click="filterByCategory('vegetable')">野菜だけ</button> <button @click="filterByCategory('fruit')">果物だけ</button> <hr /> <template v-for="item in dataSetsKey"> <label :for="`check_${item.index}`" :key="item.label" :style="`color: ${item.color}; margin: 8px;`" ><input :id="`check_${item.index}`" type="checkbox" v-model="filterItem" :value="item.index" />{{ item.label }}</label > </template> <BarChart :chart-data="filteredDataCollection" :options="{ responsive: true, maintainAspectRatio: false, labeling: { display: false }, legend: { display: false, }, }" /> </div> </template> <script> import BarChart from "./components/BarChart.vue"; export default { name: "SandBox", components: { BarChart, }, data() { return { datacollection: {}, filterItem: [], }; }, created() { this.fillData(); this.filterItem = this.datacollection.datasets.map((_s, i) => i); }, computed: { filteredDataCollection() { const collection = { ...this.datacollection, datasets: this.datacollection.datasets.filter((_s, i) => { return this.filterItem.includes(i); }), }; return collection; }, dataSetsKey() { return this.datacollection.datasets.map((s, i) => ({ label: s.label, index: i, color: s.backgroundColor, })); }, }, methods: { filterByCategory(category) { this.filterItem = this.datacollection.datasets .map((s, i) => { if (s.dataCategory === category) return i; return -1; }) .filter((s) => s >= 0); }, fillData() { this.datacollection = { labels: ["1月", "2月", "3月", "4月", "5月", "6月"], datasets: [ { label: "ほうれん草", backgroundColor: "#4cc36b", dataCategory: "vegetable", data: [ this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), ], }, { label: "なす", backgroundColor: "#456dfe", dataCategory: "vegetable", data: [ this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), ], }, { label: "りんご", backgroundColor: "#f44b81", dataCategory: "fruit", data: [ this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), ], }, { label: "みかん", backgroundColor: "#f48817", dataCategory: "fruit", data: [ this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), this.getRandomInt(), ], }, ], }; }, getRandomInt() { return Math.floor(Math.random() * (50 - 5 + 1)) + 5; }, }, }; </script>
最後に
chartjsで調べたり書いてみたりしていたけど、ライブラリの表現を超える表現をする場合にはやっぱり、なかなかパワーいるなと思った。
楽したくて使ってるのに、カスタマイズ重ねて結局スクラッチのほうが楽だったねってならないように気をつけようとおもた。