この記事は個人ブログと同じ内容です
www.ritolab.com
サーバレスアーキテクチャ構築の第一弾です。
今回は AWS の Lambda と API Gateway を連携させて、エンドポイントを作成していきます。
サーバーレス・コンピューティング
自身でサーバーを運用せずに IaaS 等のサービスを利用して処理のロジックだけをデプロイ。必要な時にだけホストした処理を動作させる一連の仕組み。
例えば、いくつかの処理を行う API サーバを持っているとして、そのサーバは 24 時間 365 日稼働させる必要がある。
サーバレスにすれば処理のロジックをリモートにホストしておき、必要な時にだけ動作させる事ができて、自身でサーバーを運用する手間が省ける。(サーバーに関するセキュリティや可用性をその分気にしなくて良くなる)
さらには動作した時間だけの課金になるので、24 時間 365 日サーバーを稼働させるよりも(大抵は)費用が抑えられる。
サーバーレス・コンピューティングを提供している主な IaaS
余談ですが AWS では、Well-Architected Framework という指針(AWS を用いた設計のベストプラクティスなど)を出していて、その中の「パフォーマンス効率」の章でサーバーレスアーキテクチャを推奨していたりもします。
docs.aws.amazon.com
AWS Well-Architected Framework
wa.aws.amazon.com
AWS Lambda
AWS Lambda はサーバーレスコンピューティングサービスで、サーバーのプロビジョニングや管理、ワークロード対応のクラスタースケーリングロジックの作成、イベント統合の維持、ランタイムの管理を行わずにコードを実行できます。
引用元:AWS Lambda(イベント発生時にコードを実行)| AWS
AWS でサーバレスやるぞってなったらこいつですね。
aws.amazon.com
フルマネージド型サービスの Amazon API Gateway を利用すれば、デベロッパーは規模にかかわらず簡単に API の作成、公開、保守、モニタリング、保護を行えます。API は、アプリケーションがバックエンドサービスからのデータ、ビジネスロジック、機能にアクセスするための「フロントドア」として機能します。
引用元:Amazon API Gateway(規模に応じた API の作成、維持、保護)| AWS
こちらはサーバレス云々というより、API を作成できるサービスです。今回は API Gateway でステートレス API を作成して、アプリケーションからそのエンドポイントを叩こうと思います。
API Gateway で作成したエンドポイントにリクエストしたら、Lambda の処理が動く。という流れです。
aws.amazon.com
開発環境
今回の開発環境は以下になります。
ちなみに今回、AWS Lambda は Node でやります。
ホストするコードは JavaScript になるわけですが、今回はこれも terraform で管理します。
実運用だと別々での管理が望ましいと考えますが、それよりもとにかく動かしてみたい欲が先行したので今回はその辺は割愛します。
それと、tf ファイル作成していく中で functions へのパスを書いているのでディレクトリ構成を事前共有しておきます。
.
├── functions
├── src
└── terraform
- functions(Lambda にホストするコード)
- src(アプリケーション)
Lambda にホストするコード
まずは、AWS Lambda にホストするコードを作成しておきます。
functions/tf-test-node-hello-world/index.js
exports.handler = async (event) => {
return {
isBase64Encoded: false,
statusCode: 200,
headers: {},
body: JSON.stringify('Hello from Lambda!'),
};
};
「Hello from Lambda!」を返すだけの関数です。
また、API Gateway が Lambda からレスポンスを受け取る場合は形式が決まっているため、そちらに倣った形式にしています。
docs.aws.amazon.com
Lambda の構築
Lambda を構築していきます。
CloudWatch
Lambda の実行ログを CloudWatch に流すのでロググループとロールを作成します。
AWS Lambda の Amazon CloudWatch ログへのアクセス
docs.aws.amazon.com
main.tf
variable "function_name" {
type = string
default = "tf-test-node-hello-world"
}
# CloudWatch Logs for lambda
resource "aws_cloudwatch_log_group" "node_lambda_hello_world" {
name = "/aws/lambda/${var.function_name}"
}
# Lambda Role for logging CloudWatchLogs
resource "aws_iam_role" "lambda_node_logging" {
name = "${var.app_name}-lambda-role"
assume_role_policy = jsonencode({
Version : "2012-10-17",
Statement = [
{
Effect = "Allow",
Principal = {
Service = "lambda.amazonaws.com"
},
Action = "sts:AssumeRole"
}
]
})
}
resource "aws_iam_policy" "lambda_node_logging" {
name = "${var.app_name}-lambda-policy"
description = "IAM policy for logging from a lambda"
policy = jsonencode({
Version : "2012-10-17",
Statement = [
{
Action = "logs:CreateLogGroup",
Effect = "Allow",
Resource = "arn:aws:logs:${var.aws_region}:${var.aws_id}:*"
},
{
Action = [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
Effect = "Allow",
Resource = [
"${aws_cloudwatch_log_group.node_lambda_hello_world.arn}:*"
]
}
]
})
}
resource "aws_iam_role_policy_attachment" "lambda_node_logging" {
policy_arn = aws_iam_policy.lambda_node_logging.arn
role = aws_iam_role.lambda_node_logging.name
}
Lambda へのデプロイ
今回は terraform で Lambda にデプロイするコードも管理するので、ローカルで ZIP を作成するようにしておきます。
main.tf
data "archive_file" "lambda_function" {
type = "zip"
source_dir = "../functions/tf-test-node-hello-world"
output_path = "../functions/upload/tf-test-node-hello-world.zip"
}
これで terraform plan ないし terraform apply 時に ZIP が作成されます。
Lambda function の作成
最後に、メインである関数を定義します。
main.tf
resource "aws_lambda_function" "hello_world" {
filename = data.archive_file.lambda_function.output_path
function_name = var.function_name
role = aws_iam_role.lambda_node_logging.arn
handler = "index.handler"
source_code_hash = filebase64sha256(data.archive_file.lambda_function.output_path)
runtime = "nodejs14.x"
depends_on = [
aws_iam_role_policy_attachment.lambda_node_logging,
aws_cloudwatch_log_group.node_lambda_hello_world
]
}
docs.aws.amazon.com
docs.aws.amazon.com
Lambda 構築実行
ここまで書いて terraform apply を実行すると、Lambda に関数が出来上がります。
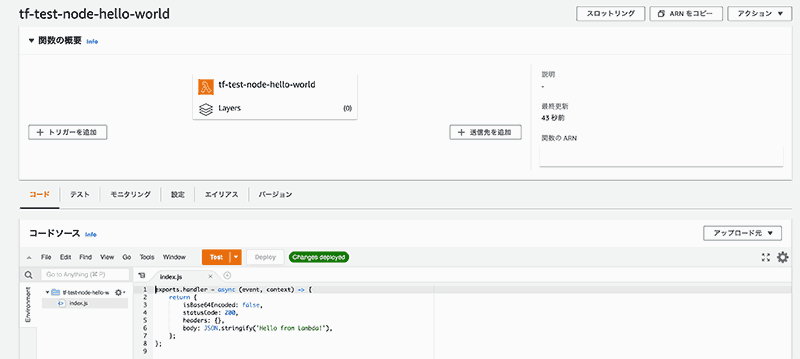
次に、作成した Lambda 関数を実行するためのインターフェースを Amazon API Gateway を使って作成していきます。
API を作成します。インターフェースの大本を作成するイメージ。
API タイプは用途によって最適なものを選択する必要があります。今回は REST API で作成します。
docs.aws.amazon.com
main.tf
# API Gateway
resource "aws_api_gateway_rest_api" "to_lambda_node" {
name = "${var.app_name}-to-lambda-node-api"
description = "REST API for lambda node test"
}
リソース作成
/hello_world のリソースを作成します。
main.tf
## for Function: hello world
### リソース作成
resource "aws_api_gateway_resource" "hello_world" {
rest_api_id = aws_api_gateway_rest_api.to_lambda_node.id
parent_id = aws_api_gateway_rest_api.to_lambda_node.root_resource_id
path_part = "hello_world"
}
メソッド作成
メソッドはリソースに対して GET や POST などの HTTP リクエストメソッドを作成します。ここでは GET で作成します。
main.tf
### メソッド設定
resource "aws_api_gateway_method" "hello_world" {
rest_api_id = aws_api_gateway_rest_api.to_lambda_node.id
resource_id = aws_api_gateway_resource.hello_world.id
http_method = "GET"
authorization = "NONE"
}
lambda 統合を設定
今回は API Gateway で作成したエンドポイントがリクエストを受け取ったら Lambda function を実行するので、API Gateway と Lambda を紐付けます。
API Gateway では Lambda との連携がスムーズにできるようにこういった設定も用意されているので紐付けが簡単に行えます。
main.tf
### lambda 統合
resource "aws_api_gateway_integration" "hello_world" {
rest_api_id = aws_api_gateway_rest_api.to_lambda_node.id
resource_id = aws_api_gateway_resource.hello_world.id
http_method = aws_api_gateway_method.hello_world.http_method
integration_http_method = "POST"
type = "AWS_PROXY"
uri = aws_lambda_function.hello_world.invoke_arn
}
ポイントとしては、integration_http_method を POST に指定している点です。
lambda への統合 method は POST で固定となっています。
aws.amazon.com
デプロイメント作成
デプロイメントを作成します。デプロイメントは、REST API 構成のスナップショットのイメージ。作成したデプロイメントを次の、ステージと紐付ける事で API が公開されます。
main.tf
### デプロイメント
resource "aws_api_gateway_deployment" "hello_world" {
rest_api_id = aws_api_gateway_rest_api.to_lambda_node.id
depends_on = [
aws_api_gateway_integration.hello_world
]
}
再度デプロイメントを行う場合の注意点
新しいリソースやメソッド作成、もしくは既存のリソースやメソッドの変更を terraform から反映する場合は、再度デプロイメントを作成する必要があります。
単純にリソースやメソッドをコード上で追加して反映しても、リソース上で追加されるだけでそれはデプロイされないからです。
そしてデプロイメントは、リソースやメソッドを追加・変更しても apply 時に変更対象とはなりません。(既に作成済みのため)
そのため AWS コンソールから手動でデプロイしてあげる必要があります。
リソースやメソッドの新規作成や変更を検知する、もしくは毎回の apply 時にデプロイメントの作成を強制する仕組みも作れますが、terraform 上での反映でデプロイメントを作成する場合は現在のものを削除した上で作り直す必要があるため、カスタムドメイン名を設定していない場合はエンドポイントのサブドメイン名が変更になってしまうので注意が必要です。
resource "aws_api_gateway_deployment" "hello_world" {
.
.
.
lifecycle {
# 変更に対応するため一度削除して作り直す
# REST API ID の変更によりエンドポイントの URI が変わるので注意
create_before_destroy = true
}
}
また、上記の設定を行わなずにデプロイメントの変更を apply した場合は以下のエラーが出力されます。
Error: error deleting API Gateway Deployment (xxxxx): BadRequestException: Active stages pointing to this deployment must be moved or deleted
どうしても仕組みが必要な場合以外はここは記述しないか false にして手動で API デプロイを行うのが良いと思います。(今回は特段必要としていないので lifecycle については記述しない(=false)で進めます。)
ステージ作成
ステージを作成します。ここでデプロイメントを参照して作成する事で API が公開されます。
main.tf
### ステージ
resource "aws_api_gateway_stage" "hello_world" {
deployment_id = aws_api_gateway_deployment.hello_world.id
rest_api_id = aws_api_gateway_rest_api.to_lambda_node.id
stage_name = var.app_name
}
API Gateway 側の設定はこれで終わりです。
Lambda へのアクセスを制限する
最後に Lambda 関数(hello_world)へのアクセス許可を API Gateway に付与します。
main.tf
resource "aws_lambda_permission" "execution_hello_world_for_api_gateway" {
statement_id = "test-AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.hello_world.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_api_gateway_rest_api.to_lambda_node.execution_arn}/*/*"
}
source_arn を本 API のみにしたので、今回作成したエンドポイントからでしかこの Lambda 関数は実行できないようになっています。
ここまで書いて terraform apply を実行すると、API Gateway が作成され、Lambda 関数にも関連付いた事が確認できます。
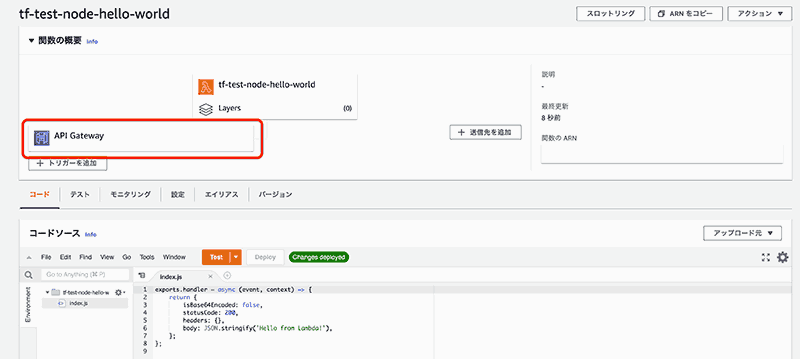
動作確認
一通りミニマムで作成したので、アプリケーションからエンドポイントを叩いてみます。
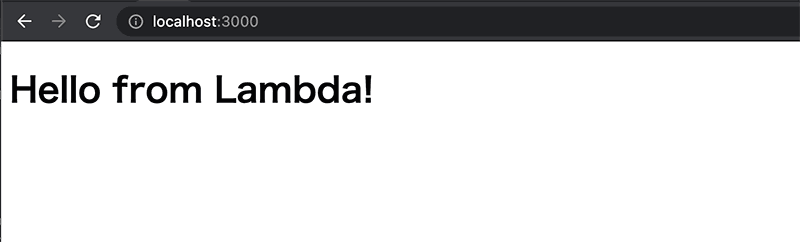
正常にレスポンスが返ってきました。これで API Gateway 経由で Lambda 関数を実行できました。
今回はここまでになります。作成したエンドポイントはデフォルトの URL であったり制限がかかっていなかったりするので、次回はエンドポイントの設定や制御を行っていこうと思います。










