この記事は個人ブログの内容がソースです。
kami-programming.com
そもそもなぜクリーンアーキテクチャーを考察するのか
DRY原則やSOLID原則などが浸透している昨今ですが、実際の開発現場のソースコードを読み込んでみると必ずしもこれらの原則に則していない場合は多いのではないでしょうか。
そして、そういった開発環境でいざコーディングをしていくと、以下のような問題に直面するのではないでしょうか。
あるバグの修正をしたのだが、同じロジックが他の場所でも書かれていたようで重複箇所のバグは依然としてバグったままだった。
あるクラスを変更したが、依存性の方向性や範囲が把握しきれておらず、変更の影響で新たなバグを生んでしまった。
ビジネスロジックの変更を迫られたが、同じロジックが重複しすぎており修正範囲を特定するだけで一苦労。
想定外の値の入力があり、バグが発生してしまった。
これらは、運用しながら仕様が変わっていくようなスタートアップ系のプロダクトでは大なり小なりどこにもで発生しうる問題です。
これらの問題の共通の原因は、ソースコードに「可変性」が欠如している事です。
今回はこういった問題を解決できる糸口を掴むべく、クリーンアーキテクチャーを考察してみたいと思います。
なぜ「可変性」が失われていくのか
新しくプロダクトを新規で作成する時はまだソースコードのサイズは小さく、ちょっとした仕様の変更ならば比較的変更の「影響範囲」も肉眼で確認できるレベルなので、それほど神経質になることは無いと思います。
しかし、幸いにもプロダクトが軌道にのり、運用期間が長くなるにつれてソースコードのサイズは肥大化していき、ある処理がソースコード全体に与えている「影響範囲」も人間の肉眼だけでは把握できなくなっていき変更コストが増大します。
また、オブジェクト指向ではClass同士に「依存関係」というものが発生しますが、この「依存関係」に縛られて凝り固まってしまっている場合、仕様変更などで機能の取替を迫られた場合の変更が困難になります。
「依存関係」とは
依存というのは、例えばクラスAの機能がクラスBの機能を前提に作られている場合などを指し、この場合は「AはBに依存をしている」と言える。
ここで、すこし具体的な例を提示します。
<?php
class UserBuyProductService
{
public function buy(int $userId, int $productId, int $amount): void
{
$stripePayment = new StripePayment();
$stripePayment->payment($userId, $amount);
}
}
class StripePayment
{
public function payment(int $userId, int $amount): void
{
}
}
上記UserBuyProductServiceは、あるユーザーが$productIdを持つ商品を購入したときの処理を表しており、この購入処理の中でStripePaymentクラスをインスタンス化してpaymentメソッドを使用することで購入処理を実現しています。
これは、UserBuyProductServiceクラスはStripePaymentに依存していると表現することができ、この様な状態を密結合と呼びます。
「密結合」の何がいけないのか
結論から申し上げますと、密結合なソースコードは可変性が低くなります。
例えば、前項のUserBuyProductServiceのケースでは決済機能としてStripeを使用していますが、これがビジネスサイドの要望でGMOPaymentGatewayに変更を迫られたようなケースを考えてみましょう。
決済機能は「UserBuyProductService」だけで使われているとは限りません。
だから、既存のソースコードの中で「StripePayment」の影響を受けている処理を全て洗い出して漏れなく「GMOPaymentGateway」の処理にリファクタリングする必要があります。
大規模で複雑なプロダクトほど、「ただ切り替えるだけ」という変更要件に多大な変更コストが発生してしまうのです。
このようなケースの問題点を冷静にみつめると、ソースコード全体が「Stripeで決済をする」という「具体」に対して依存してしまっていることが問題だと仮定することができます。
では、具体の逆説である抽象にソースコードが依存した場合のケースを考えてみましょう。
「抽象に依存」とは
ここで、抽象とはなにか?と言うことを明確に定義する必要があります。
抽象とは「抽出」して「象(かたど)る」と書きます。
つまり、抽象とは、 「ある物事から共通項を抜き出して(抽出)、規格を作る(象る)」 と言い表すことが出来きるかと思います。
この規格を定義するのに、オブジェクト指向プログラミングでは「interface」を使います。
<?php
interface Payment
{
public function payment(int $userId, $amount): void;
}
上記のように、「interface」として、決済機能の振る舞いとして必要な振る舞いを「引き数」と「戻り値」の型と共に定義します。
そして、実際に商品購入処理を行っている「UserBuyProductServie」を、このinterfaceに依存するようにします。
<?php
class UserBuyProductService
{
private $paymentManager;
public function __construct(Payment $peymentManeger)
{
$this->paymentManager = $peymentManeger;
}
public function buy(int $userId, int $productId, int $amount): void
{
$this->paymentManager->payment($userId, $amount);
}
}
class StripePayment implements Payment
{
public function payment(int $userId, int $amount): void
{
}
}
class GmoPaymentGateway implements Payment
{
public function payment(int $userId, int $amount): void
{
}
}
上記の変更点は、「UserBuyProductService」のコンストラクタで「Payment」インターフェースを経由して受け取ったインスタンスを、メンバ変数である$paymentMangerに代入し、$paymentMangerからpaymentメソッドを実行して決済を実現しています。
この様な方法を「コンストラクタインジェクション」と言いますが、ここでは「Payment型」のインスタンスであればなんでも受け取れるようになります。
そのため、Paymentインターフェースを実装した具象クラスであれば、如何なるインスタンスでも「UserBuyProductService」に外部注入することができます。
この様に、依存関係をInterfeceなどの抽象を通じて外部から注入することを「Dependency Injection」と言い、こうすることで「可変性」と「拡張性」を得ることができるのです。
また、Laravelの場合は「ServiceProvider」にて、「抽象クラス」と「具象クラス」の紐付けを設定することができます。
以下は、ServiceProviderの例
<?php
namespace App\Providers;
use Illuminate\Support\ServiceProvider;
use Packages\Application\Product\ProductCreateInteractor;
use Packages\Application\Shop\ShopCreateInteractor;
use Packages\Application\User\UserCreateInteractor;
use Packages\Domain\CommonRepository\DataStoreTransactionInterface;
use Packages\Domain\CommonRepository\UuidGeneratorInterface;
use Packages\Domain\Models\Product\ProductRepository;
use Packages\Domain\Models\Shop\ShopRepository;
use Packages\Domain\Models\User\UserRepository;
use Packages\Infrastructure\EloquentRepository\DataStoreTransactionEloquentRepository;
use Packages\Infrastructure\EloquentRepository\ProductEloquentRepository;
use Packages\Infrastructure\EloquentRepository\ShopEloquentRepository;
use Packages\Infrastructure\EloquentRepository\UserEloquentRepository;
use Packages\Infrastructure\LaravelFeatureRepository\UuidGenerateLaravelFeatureRepository;
use Packages\UseCase\Product\Create\ProductCreateUseCaseInterface;
use Packages\UseCase\Shop\Create\ShopCreateUseCaseInterface;
use Packages\UseCase\User\Create\UserCreateUseCaseInterface;
use Packages\UseCase\User\Get\UserGetUseCaseInterface;
use Packages\Application\User\UserGetInteractor;
class AppServiceProvider extends ServiceProvider
{
@return
public function register()
{
$this->app->bind(
DataStoreTransactionInterface::class,
DataStoreTransactionEloquentRepository::class
);
$this->app->bind(
UserRepository::class,
UserEloquentRepository::class
);
$this->app->bind(
ShopRepository::class,
ShopEloquentRepository::class
);
$this->app->bind(
ProductRepository::class,
ProductEloquentRepository::class
);
$this->app->bind(
UuidGeneratorInterface::class,
UuidGenerateLaravelFeatureRepository::class
);
$this->app->bind(
UserCreateUseCaseInterface::class,
UserCreateInteractor::class
);
$this->app->bind(
UserGetUseCaseInterface::class,
UserGetInteractor::class
);
$this->app->bind(
ShopCreateUseCaseInterface::class,
ShopCreateInteractor::class
);
$this->app->bind(
ProductCreateUseCaseInterface::class,
ProductCreateInteractor::class
);
}
@return
public function boot()
{
}
}
これを活用することにより、例えば、「Paymentインターフェースがコンストラクタインジェクションされる時にはGmoPaymentGatewayが自動的に具象クラスとしてインジェクションされる」といった設定を行うことができます。
この様に「抽象」に依存することによって、この先、決済機能を「Pay.jpに切り替えたいんだけど...」などという要求が発生た場合、「Payment」インターフェースを実装した「PayJp」クラスを作成し、ServiceProviderの「Payment」インターフェースに紐づく具象クラスを「PayJp」クラスに切り替えるだけで、ソースコードの全ての決済処理を「PayJp」に切り替える事ができます。
前置きが長くなりましたが、ここでようやくクリーンアーキテクチャーについて見ていこうと思います。
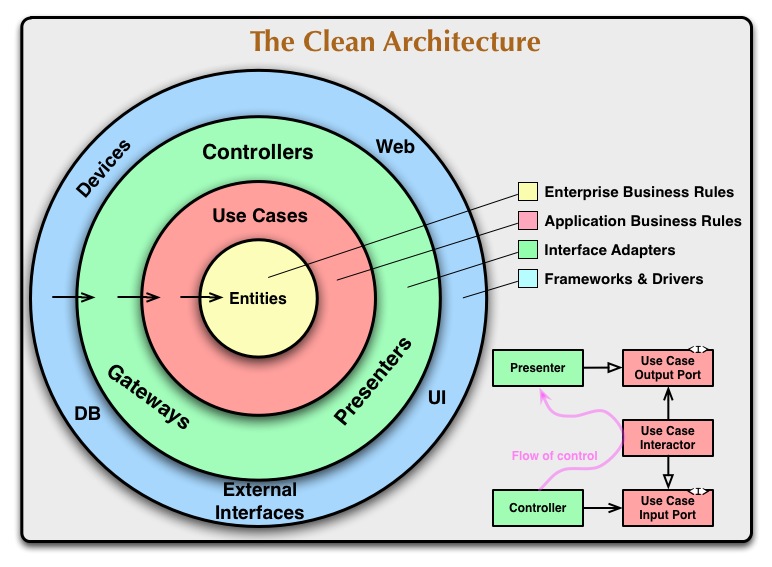
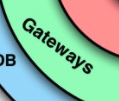
クリーンアーキテクチャーといえば、この同心円のイメージが有名ですし、本家です。
簡潔に言うならば、コードをレイヤーに分け、依存性の方向を一方向にすることで保守性を高めようとするためのガイドラインだと言えるでしょう。
同心円の図からそれぞれの意味を理解する
基礎的な考え方を理解しなければ話は進まないので、まずは同心円の図について読解していきます。
依存の方向性
この矢印はレイヤー同士の依存関係の方向性を示している。
つまり、同心円の外側の要素が、内側の要素に向かって依存をするようにし、「Entities」などの内側の要素が外側に向かって依存しないようにすることを示しています。
同心円の図によれば、clean architectureの全ての要素の依存の方向性は全て「Entities」に向けられています。
では、この「Entites」とは一体何者なのでしょうか。
Entities
同心円の最も中心にある「Entities」がこれに当たります。
「ビジネスルール」を集める場所であり、そのアプリケーションの「名詞」にあたるモデルを定義する場所です。
「ビジネスルール」とは、そのアプリケーションがシステム化(自動化)されていないとした場合でも存在するドメインルールの事。
例えば、ECショップのシステムであれば、User(出品者)、Shop(店舗)、Product(商品)などのドメイン知識が「Entity」クラスとして表現されることになります。
ECショップというものは、システム化される以前も「出品者」と「店舗」と「商品」といった実体は存在し、ビジネスとはこれら名詞同士の関係性によって説明ができます。
「出品者」が「店舗」を開いて、「商品」を陳列した
このように、名詞そのものの属性や、名詞同士の繋がり合いのことを「ビジネスルール」と言います。
「Entities」の領域はこれらのビジネスルールを、他のレイヤーから保護するように隠蔽します。
そして、その他のレイヤーがこの隠蔽されたビジネスルールに依存することで、ビジネスルール(仕様)の変更を一箇所に集めることを実現するのです。
ここで、Userのビジネスルールを考えてみましょう。User(出品者)は、名前などの情報を持っています。
簡単に例を書くと以下の様になる。
<?php
class UserEntity
{
@var
private $id;
@var
private $name;
public function __construct(
string $id = null,
string $name
) {
$this->id = $id;
$this->name = $name;
}
public function getId(): string
{
return $this->id;
}
public function getName(): string
{
return $this->name;
}
}
ただしこれでは不完全で、上記のコードの様にクラスのメンバがプリミティブ型(stringやintなどの原始的な型)で定義されていると、なにかと不都合な事が生じます。
ここで登場するのが「ValueObject」という値を表現するオブジェクトです。
ValueObject
プリミティブ型は、「stringは文字列、intは数値」とある程度、型の制約をしてくれるものの、ビジネスルールとしてはこの制約では不十分です。
たとえば上記のUserEntityクラスの場合、Userの氏名であるnameの文字数はstring型の最小単位の空文字を許容して良いのでしょうか?
この様に、プリミティブ型の制約はビジネスルールの制約よりもザルであることを踏まえ、以下のようにValueObjectを作成します。
<?php
class UserName
{
public const MIN_LENGTH = 1;
@var
private $_value;
private function __construct(string $value)
{
$this->_value = $value;
}
public static function create(string $value): self
{
self::validation($value);
return new self($value);
}
private static function validation(string $value): bool
{
if (mb_strlen($value) < self::MIN_LENGTH) {
throw new RuntimeException('名前は必須です。');
}
}
public function value(): string
{
return $this->_value();
}
}
このようにValueObjectを作成し、先程のUserEntityをリファクタリングします。
<?php
class UserEntity
{
@var
private $id;
@var
private $name;
public function __construct(
string $id = null,
UserName $name
) {
$this->id = $id;
$this->name = $name;
}
public function getId(): string
{
return $this->id;
}
public function getName(): UserName
{
return $this->name;
}
}
変更点は、コンストラクタでの$nameの取得の型がstringからUserNameに変更され、UserEntityのメンバ変数である$nameもUserNameに型が変更されています。
これを実際にインスタンス化すると以下のようになります。
<?php
$userEntity = new UserEntity(
'aaaa-bbbb-ccccc',
UserName::create('斎藤 一')
);
この時、もしもUserName::createの引き数に与えられたプリミティブの値が必要文字数を満たしていなければ、UserNameの値審査機能がエラーをスローし、不正な値の混入を阻止します。
また、ビジネスルールの変更で、「UserNameは最低文字数を5文字にしてほしい。」などという要求が出てきた場合も以下の箇所を一箇所変更するだけで全てのコードにルールの変更を反映させることができます。
<?php
class UserName
{
public const MIN_LENGTH = 5;
(以下省略......)
この様に、MIN_LENGTHの値を一箇所変えることで、ソースコード全体のUserNameに関わる処理に対してルールの変更を伝播することができます。
ここまで、EntitiesやValueObjectをみてきましたが、これらを定義しただけではまだアプリケーションとして体をなしていません。
メモリー上で表現したEntityやValueObjectの状態を保存や再構築することが、アプリケーションをたり立たせる上で必要になります。
それを実現するのが「Gateways」という存在です。
Gateways
LaravelではしばしばRepositoryパターンが採用されますが、このRepositoryがGatewaysに該当します。
主にデータベースに対する保存や、再構築を担当するレイヤーです。
Laravelの場合はこの領域でEloquentモデルのORMを使うことでDatabaseの操作を行います。
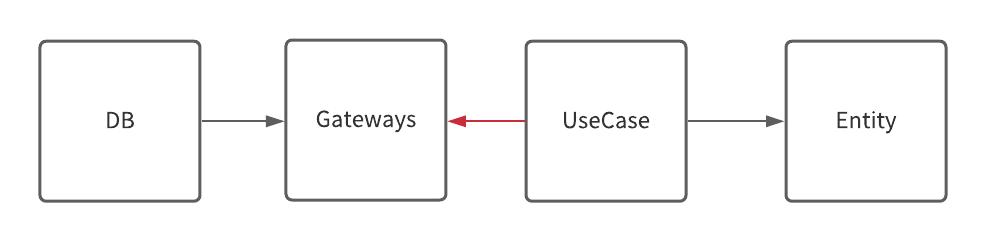
ここで問題となるのが、依存性の方向性です。
普通にRepositoryをクラスとして定義してしまうと、それを使う後述するUseCase層からGatewaysに依存の方向性が直接逆流してしまいます。
ここでInterfaceを使った「依存性逆転の原則」を使うことで、依存の方向性を維持することを実現します。
この例でみると、具象クラスであるReopsitory(Gateways層)はinterfaceを実装することでInterfaceへ依存のベクトルを延ばしています。(白抜きの矢印は実装による依存ベクトルを示す。)
この事を「依存性逆転の原則」と言います。
まずInterfaceから見ていきましょう。
<?php
interface UserRepositoryInterface
{
@param
@return
public function save(UserEntity $customer): UserEntity;
}
この様に、引数と戻り値の型を制約したInterfaceを定義します。
この抽象に依存する形で、具象クラスであるRepositoryを作成します。
<?php
class UserRepository implements UserRepositoryInterface
{
@param
@param
@return
public function save(string $uuid, UserEntity $user): UserEntity
{
@var
$ormUser = User::create([
'id' => $uuid,
'name' => $customer->getName()->value(),
]);
return new UserEntity(
$ormUser->id,
UserName::create($ormCustomer->name)
);
}
}
この様に、InterfaceにRepositoryが依存する形をとり、UseCaseなどからはInterfaceをサービスコンテナを通じて呼び出すようにすることで、依存性の方向性を維持することができる。
Geteways層であるRepositoryをInterfaceを通じて抽象に依存させることの意味は、UseCaseからみた時のRepositoryの「可変性」を維持するためと言えます。
以下の図を御覧ください。
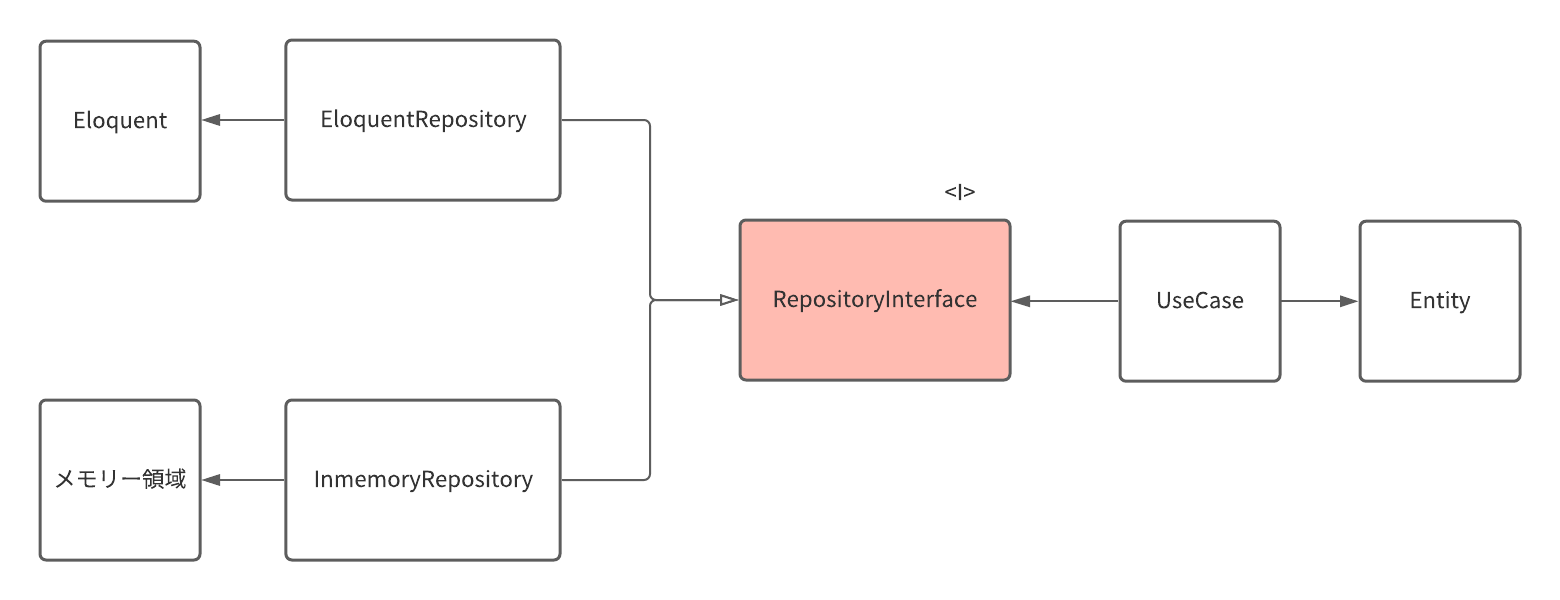
この様に、RepositoryInterfaceを実装した具象クラスがEloquentRepositoryとInmemoryRepositoryの2つ実装されているケースを考えます。
InmemoryRepositoryの用途は主にテスト用で、特にDataStoreなどに保存することなく、連想配列としてメンバ変数に値を保存するようなクラスです。
RepositoryInterfaceは現状ではこれら2つの具象クラスをbundleしている形になっており、UseCaseはこのRepositoryInterfaceへ依存しているため、どちらの具象クラスも外部注入(DI)することが叶います。
この性質を利用すれば、実際の運用の際はEloquentRepositoryを使用し、TestのときはInmemoryRepositoryを使用することができ、簡単にテストデータの構築を行うことができます。
また、技術の革新により新たに高性能なDataStoreが生まれて、DataStoreをそちらに乗り換えたい。
そして、そのDataStoreがEloquentモデルに対応していない...。
その様な場合でも、RepositoryInterfaceを実装した新たなDataStore用の具象Repositoryを作成することで、UseCaseなどの層に影響を与えることなく入れ替えを行うことができるのです。
この様に、アプリケーションを特定の技術基盤に縛られないように「pluggable」(脱着可能)にして置くことで、ここでも「可変性」を守っているというわけです。
UseCase
UseCaseはアプリケーションのAPI で、ドメインオブジェクトを操作し利用者の目的を達成することが役割で、1つのビジネストランザクションとして定義します。
Entityは「名詞」に該当するということを上げましたが、UseCaseは「活動(動詞)」を表現します。
「pluggable」な建て付けにするためのinterfaceとその実装がこれにあたります。
「pluggable」にすることで、テストの際はテスト用のUseCaseの具象クラスとすり替えて、UI層のテストを行いやす行くすることや、Databaseの建て付けなどがまだ確定していない段階でのフロントエンドの先行開発なども容易になります。
ここで具体的なUseCaseの実装例を示します。
<?php
namespace Packages\Application\User;
use Packages\Domain\CommonRepository\UuidGeneratorInterface;
use Packages\Domain\Models\User\AuthUserEntity;
use Packages\Domain\Models\User\UserEmail;
use Packages\Domain\Models\User\UserId;
use Packages\Domain\Models\User\UserName;
use Packages\Domain\Models\User\UserPassword;
use Packages\Domain\Models\User\UserRepository;
use Packages\UseCase\User\Create\UserCreateRequest;
use Packages\UseCase\User\Create\UserCreateResponse;
use Packages\UseCase\User\Create\UserCreateUseCaseInterface;
class UserCreateInteractor implements UserCreateUseCaseInterface
{
@var
private $userRepository;
@var
private $uuidGenerator;
public function __construct(
UserRepository $userRepository,
UuidGeneratorInterface $uuidGenerator
) {
$this->userRepository = $userRepository;
$this->uuidGenerator = $uuidGenerator;
}
public function __invoke(UserCreateRequest $request): UserCreateResponse
{
$user = new AuthUserEntity(
UserId::create($this->uuidGenerator->generateUuidString()),
UserName::create($request->getName()),
UserEmail::create($request->getEmail()),
UserPassword::create($request->getPassword())
);
$user = $this->userRepository->create($user);
return new UserCreateResponse(
$user->getId()->value(),
$user->getName()->value(),
$user->getEmail()->value()
);
}
}
UseCaseはinterfaceを通じて、後述するControllerから使用されますが、ControllerとUseCase間のデータのやり取りはDTO(Data Transfer Object)で行います。
例えば、上記のソースコードでUseCaseの__invokeメソッドの引き数はUserCreateRequestというDTOクラスです。
この点において、Laravelを普段から使っている人であれば、「フロントエンドからの送信を受信しているFormRequestをそのままUseCaseの引き数にしてしまえばよいのでは?」という疑問を抱くと思います。
ですが、ここでもう一度クリーンアーキテクチャーの同心円を思い出して頂きたい。
この図をみると、Frameworksのレイヤーは同心円上の最も外側に位置します。
LaravelのFormRequestクラスはこのFrameworks層の住人であり、これにUseCaseが依存することは依存方向性の逆流を意味します。
UseCaseが特定のFrameworkなどの技術基盤を前提に作られてしまうことは、「可変性」の低下を招くことになるため、DTOを使うことで「疎結合」を維持したいというモチベーションがここにはあります。
UserCreateResponse(OutputDTO)については、外部公開すべきデータを制御するために用いています。
Entityクラスのメンバ変数はprivateなので、これを公開範囲を指定し、公開可能なデータとしてControllerに返却したいモチベーションがここにはあります。
Controllers
Controllers は入力をアプリケーション(UseCases)が要求する形に変更して伝えるのが役目です。
今回はLaravelを使うので、laravelのControllerがそれに当たります。
フロントエンドから送られてきたリクエストの内容を、UseCaseが求める形に変換し、UseCaseに伝えます。
さらに、httpリクエストがレスポンスと対である兼ね合いで、laravelなどのフレームワークの場合はUIへの変換処理もControllerが担うことになります。
本来これらはPresenterの役割ですが、今回は割愛させて頂きます。
以上までを踏まえて、Laravelで実際にコードを書いてみます。
全体図
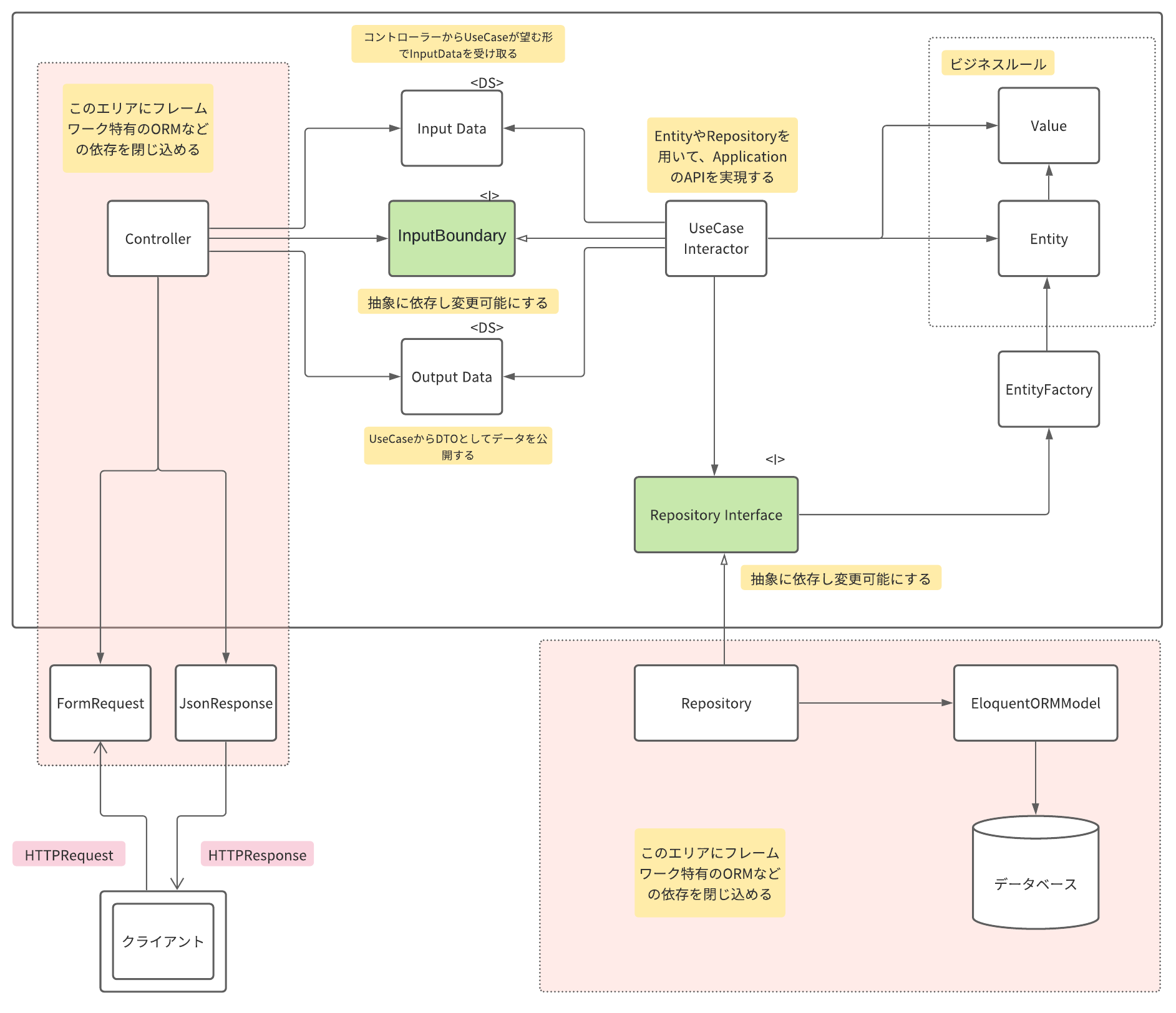
これは今回私なりに考えた、Laravelでクリーンアーキテクチャーに従う場合の全体図になります。
今回のサンプルアプリケーションも、基本的にこの画像のスキームに則って実装します。
薄いピンク色に囲まれたゾーンが、クリーンアーキテクチャーの同心円状の外側に位置するFrameworks層にあたり、基本的な考え方としてはLaravelのEloquentモデルの機能や、FormRequestなどのValidation機能などはこのゾーンに閉じ込めてフル活用します。
そして、色の囲みがないUseCaseやEntityなどの領域は基本的にLaravelやその他の技術基盤に依存させないクリーンな状態を保つようにします。
サンプルアプリの仕様
UserはShopを複数持つことができて、Productを複数出品できる。
サンプルアプリリポジトリはこちら
実際にアプリケーションを構築する
上記の使用を全て上げてしまうと冗長になるので、ここでは、Userの登録機能だけを取り出してサンプルアプリリポジトリの解説をしていきます。
まずはEntityとValueObjectを定義する
UserEntity
<?php
namespace Packages\Domain\Models\User;
@package
class UserEntity
{
@var
protected $id;
@var
protected $name;
@var
protected $email;
@param
@param
@param
@param
public function __construct(UserId $id, UserName $name, UserEmail $email)
{
$this->id = $id;
$this->name = $name;
$this->email = $email;
}
@return
public function getId(): UserId
{
return $this->id;
}
@return
public function getName(): UserName
{
return $this->name;
}
@return
public function getEmail(): UserEmail
{
return $this->email;
}
}
UserId
<?php
namespace Packages\Domain\Models\User;
@package
class UserId
{
@var
private $_value;
@param
private function __construct(string $userId)
{
$this->_value = $userId;
}
public static function create(string $userId): self
{
return new self($userId);
}
public function value(): string
{
return $this->_value;
}
@param
@return
public function isEquals(UserId $otherId): bool
{
return $this->_value === $otherId->value();
}
}
UserName
<?php
namespace Packages\Domain\Models\User;
use RuntimeException;
@package
class UserName
{
public const MIN_LNEGTH = 3;
@var
private $_value;
@param
private function __construct(string $userName)
{
self::validation($userName);
$this->_value = $userName;
}
public static function create(string $userName): self
{
return new self($userName);
}
public function value(): string
{
return $this->_value;
}
private static function validation(string $value): void
{
if (mb_strlen($value) < self::MIN_LNEGTH) {
throw new RuntimeException(sprintf('名前の最小文字数は%sです', self::MIN_LNEGTH));
}
}
}
ここで注目したいのはvalidationメソッドです。
この様に、ValueObject自身に値審査機能があることで、そもそも不正な値で値オブジェクトを生成させないという建て付けになります。
また、今回のケースの「ユーザーの名前の文字数は3文字以上にしたい」といったルールをDomainObjectであるValueObjectに共通化することで、たとえばルールの変更を行う際に、DomainObjectの変更をするだけで全体に変更を反映することができます。
<?php
class UserName
{
public const MIN_LNEGTH = 20;
UserEmail
<?php
namespace Packages\Domain\Models\User;
@package
class UserEmail
{
@var
private $_value;
@param
private function __construct(string $userEmail)
{
$this->_value = $userEmail;
}
public static function create(string $userEmail): self
{
return new self($userEmail);
}
public function value(): string
{
return $this->_value;
}
}
AuthUserEntity
UserEntityは、登録処理のときはUserPasswordが必須ですが、普段アプリケーション上の挙動を実現するためにはむしろUserPasswordはEntityの中には不要です。
そこで、今回は認証用にUserEntityを継承し拡張したAuthUserEntityを作成します。
<?php
namespace Packages\Domain\Models\User;
@package
class AuthUserEntity extends UserEntity
{
@var
private $password;
public function __construct(UserId $id, UserName $name, UserEmail $email, UserPassword $password)
{
parent::__construct($id, $name, $email);
$this->password = $password;
}
@return
public function getPassword(): UserPassword
{
return $this->password;
}
}
追加点は$passwordというメンバ変数とそのgetterメソッドが追加されたに過ぎません。
UserPassword
<?php
namespace Packages\Domain\Models\User;
TODO
use Illuminate\Support\Facades\Hash;
use RuntimeException;
@package
class UserPassword
{
public const MIN_LENGTH = 8;
@var
private $_value;
@param
private function __construct(string $userPassword)
{
$this->_value = $userPassword;
}
public static function create(string $userPassword): self
{
self::validation($userPassword);
return new self($userPassword);
}
public function value(): string
{
return $this->_value;
}
@return
public function getHashValue(): string
{
return Hash::make($this->_value);
}
private static function validation(string $userPassword): void
{
if (strlen($userPassword) < self::MIN_LENGTH) {
throw new RuntimeException(sprintf('パスワードは最低%s文字です。', UserPassword::MIN_LENGTH));
}
}
}
ここで注目したいのは、getHashValueという関数です。
ここではDatabaseに保存する際に、平文のパスワードをハッシュ化するための機能をValueObject自身に実装しています。
ただし、コード上のTODOでも記載したとおり、このハッシュ化ロジックにはLaravelのファサード機能を使っています。
DomainObjectであるValueObjectが「Laravel」という特定の技術基盤に依存している形になってしまっているので、このあたりのベストプラクティスはまだ私も考察中ですが、今回はこのままで進めたいと思います。
Entityが出揃ったところでRepositoryを作成
UserRepository
<?php
namespace Packages\Domain\Models\User;
use App\User;
interface UserRepository
{
public function getById(UserId $userId): UserEntity;
public function create(AuthUserEntity $userEntity): UserEntity;
}
Repositoryは上記を見てわかるように、ただのインターフェースです。
実際の具体的な処理はこのインターフェースを実装した、具象クラスにて実装します。
UserEloquentRepository
<?php
namespace Packages\Infrastructure\EloquentRepository;
use Packages\Domain\Models\User\UserEntity;
use Packages\Domain\Models\User\AuthUserEntity;
use Packages\Domain\Models\User\UserId;
use Packages\Domain\Models\User\UserRepository;
use Packages\Domain\Models\User\UserEntityFactory;
use App\User;
class UserEloquentRepository implements UserRepository
{
public function create(AuthUserEntity $userEntity): UserEntity
{
$ormUser = User::create([
'id' => $userEntity->getId()->value(),
'name' => $userEntity->getName()->value(),
'email' => $userEntity->getEmail()->value(),
'password' => $userEntity->getPassword()->getHashValue(),
]);
return UserEntityFactory::createFromORM($ormUser);
}
public function getById(UserId $userId): UserEntity
{
$ormUser = User::find($userId->value());
return UserEntityFactory::createFromORM($ormUser);
}
}
ここで注意したいのは、LaravelのEloquentモデルを直接返さず、戻り値としてUserEntityに載せ替えている点です。
これは、後述するUseCase層にLaravel特有の技術基盤であるEloquentモデルを漏れ出さないようにするためです。
EloquentのことはEloquentRepositoryの中だけで完結しろというわけです。
また、ここで新しい概念である「UserEntityFactory」というものが登場しているのでこの点を補足説明致します。
UserEntityFactory
<?php
namespace Packages\Domain\Models\User;
use App\User;
@package
class UserEntityFactory
{
public static function createFromORM(User $user): UserEntity
{
return new UserEntity(
UserId::create($user->id),
UserName::create($user->name),
UserEmail::create($user->email)
);
}
}
中身の処理は上記の様になっており、単純にEloquentModelのUserを自前のDomainObjectであるUserEntityに載せ替えているだけの処理です。
この程度であれば、このFactoryクラスの存在意義は感じにくいかもしれませんが、例えば多数のリレーション関係を持つモデルをEntityの載せ替える処理は、それ自体が複雑なロジックになります。
この「載せ替える」というロジックはそもそもRepositoryの責務そのものとは別問題なので、Factoryというクラスに役割を分割するというわけです
DomainObjectをまとめ上げてUseCaseを作る
UserCreateUseCaseInterface
<?php
namespace Packages\UseCase\User\Create;
interface UserCreateUseCaseInterface
{
public function __invoke(UserCreateRequest $request): UserCreateResponse;
}
UseCaseもインターフェースで抽象化します。
理由は、バックエンドが完成するまえにでもUseCaseをスタブと切り替えることでフロントエンドの先行開発などができるからです。
ここでもやはり「pluggable」な構成にすることで、柔軟性をもたせることができるというわけです。
UserCreateRequest
<?php
namespace Packages\UseCase\User\Create;
class UserCreateRequest
{
@var
private $name;
@var
private $email;
@var
private $password;
@param
@param
@param
public function __construct(string $name, string $email, string $password)
{
$this->name = $name;
$this->email = $email;
$this->password = $password;
}
@return
public function getName(): string
{
return $this->name;
}
@return
public function getEmail(): string
{
return $this->email;
}
@return
public function getPassword(): string
{
return $this->password;
}
}
データの転送用のDTOになります。
LaravelのFormRequetを直接UseCase層に流入させてしまうと、UseCase層がLaravelという特定の技術基盤に侵食されてしまいます。
この事を防ぐためにDTOで連絡を取り合います。
UserCreateResponse
<?php
namespace Packages\UseCase\User\Create;
class UserCreateResponse
{
@var
private $id;
@var
private $name;
@var
private $email;
@param
@param
@param
public function __construct(string $id, string $name, string $email)
{
$this->id = $id;
$this->name = $name;
$this->email = $email;
}
@return
public function getId(): string
{
return $this->id;
}
@return
public function getName(): string
{
return $this->name;
}
@return
public function getEmail(): string
{
return $this->email;
}
@return
public function toArray(): array
{
return [
'id' => $this->id,
'name' => $this->name,
'email' => $this->email,
];
}
}
こちらもデータ転送用のDTOです。
こちらはUseCaseからControllerへのデータ転送用になりますが、これはEntityのprivateなメンバ変数を、公開範囲を制御しつつControllerへ伝える役割を担っています。
UserCreateInteractor
<?php
namespace Packages\Application\User;
use Packages\Domain\CommonRepository\UuidGeneratorInterface;
use Packages\Domain\Models\User\AuthUserEntity;
use Packages\Domain\Models\User\UserEmail;
use Packages\Domain\Models\User\UserId;
use Packages\Domain\Models\User\UserName;
use Packages\Domain\Models\User\UserPassword;
use Packages\Domain\Models\User\UserRepository;
use Packages\UseCase\User\Create\UserCreateRequest;
use Packages\UseCase\User\Create\UserCreateResponse;
use Packages\UseCase\User\Create\UserCreateUseCaseInterface;
class UserCreateInteractor implements UserCreateUseCaseInterface
{
@var
private $userRepository;
@var
private $uuidGenerator;
public function __construct(
UserRepository $userRepository,
UuidGeneratorInterface $uuidGenerator
) {
$this->userRepository = $userRepository;
$this->uuidGenerator = $uuidGenerator;
}
public function __invoke(UserCreateRequest $request): UserCreateResponse
{
$user = new AuthUserEntity(
UserId::create($this->uuidGenerator->generateUuidString()),
UserName::create($request->getName()),
UserEmail::create($request->getEmail()),
UserPassword::create($request->getPassword())
);
$user = $this->userRepository->create($user);
return new UserCreateResponse(
$user->getId()->value(),
$user->getName()->value(),
$user->getEmail()->value()
);
}
}
「UserCreateUseCaseInterface」の具象クラスです。
ここで、いままで作成したEntityやValueObject、RepositoryなどのDomainObject達をコントロールし、アプリケーションとしての振る舞いを実現し、利用者に機能を提供します。
利用者に公開するためにControllerを作る
AuthController
<?php
namespace App\Http\Controllers;
use App\Http\Requests\Auth\AuthLoginRequest;
use App\Http\Requests\Auth\AuthRegisterRequest;
use Packages\UseCase\User\Create\UserCreateRequest;
use Packages\UseCase\User\Create\UserCreateUseCaseInterface;
use Packages\UseCase\User\Get\UserGetRequest;
use Packages\UseCase\User\Get\UserGetUseCaseInterface;
use Illuminate\Http\JsonResponse;
class AuthController extends Controller
{
@return
public function __construct()
{
$this->middleware('auth:api', ['except' => ['login']]);
}
public function register(
AuthRegisterRequest $request,
UserCreateUseCaseInterface $userCreateUseCase
): JsonResponse {
$userCreateRequest = new UserCreateRequest(
$request->name,
$request->email,
$request->password
);
$response = $userCreateUseCase($userCreateRequest);
if (!$token = auth('api')->attempt($request->all())) {
return response()->json(['error' => 'Unauthorized'], 401);
}
return response()->json([
'user' => $response->toArray(),
'access_token' => $token,
'token_type' => 'bearer',
'expires_in' => auth()->factory()->getTTL() * 60
]);
}
}
LaravelのControllerクラスです。
利用者からのRequestを受け取り、UseCaseへそのリクエストを処理できる形に変換して伝えることが役割です。
今回の実装ではPresenterは取り上げていないので、UseCaseからのレスポンスをJsonResponseに変換して利用者へレスポンスを返すような建て付けにしています。
AuthRegisterRequest
<?php
namespace App\Http\Requests\Auth;
use Illuminate\Contracts\Validation\Validator;
use Illuminate\Foundation\Http\FormRequest;
use Illuminate\Http\Exceptions\HttpResponseException;
use Packages\Domain\Models\User\UserPassword;
use Packages\Domain\Models\User\UserName;
class AuthRegisterRequest extends FormRequest
{
@return
public function authorize()
{
return true;
}
@return
public function rules()
{
return [
'name' => [
'required',
'string',
sprintf('min:%s', UserName::MIN_LNEGTH),
'max:255'
],
'email' => [
'required',
'string',
'email:strict,dns',
'max:255',
'unique:users'
],
'password' => [
'required',
'string',
sprintf('min:%s', UserPassword::MIN_LENGTH),
'confirmed',
],
];
}
protected function failedValidation(Validator $validator)
{
throw new HttpResponseException(
response()->json([
'message' => $validator->errors()->toArray(),
], 403)
);
}
}
LaravelのFormRequestクラスです。
通常の「Illuminate\Http\Request」クラスを継承しており、同時にvalidation機能も提供してくれる便利なクラスなので使わない手はありません。
Controllerはクリーンアーキテクチャーにおける同心円の中で一番外側のFrameworkds層の住人なので、ここでLaravel独自の技術に依存することは問題ではありません。
ここで、「ValueObjectで値の審査をしているからFormRequestでのValidationは不必要では?」という意見もあると思います。
たしかに、この2つは値に対するルールが同一になると思いますが、FormRequestとValueObjectではそれぞれが持つ役割が違います。
ValueObjectは値そのもののビジネスルールであり、FormRequestはそのビジネスルールに従い、Requestを審査するという役割です。
FormRequestはルール以外の者の侵入を拒み、ValueObjectはルール以外の生成を拒みます。
そしてValueObjectが生成を拒むおかげで、Request以外からのルートでEntityが生成される場合でも審査機能を利かすことができます。
この様に、「Laravelの機能を使わない」ではなく「ドメイン層やアプリケーション層では使わない」というルールに徹して活用すれば、ビジネスルールが特定の技術基盤に依存してしまうことを避けられます。
まとめ
ここまで、クリーンアーキテクチャーをLaravelで活用する方法を自分なりに研究してきましたが、簡潔に言うならば「クリーンアーキテクチャーとは、ビジネスルールの在り処を一箇所に集め、技術基盤との堺にインターフェースを挟むことでビジネスルールに対して"pluggable(脱着可能)"にする事で、"可変性"を保ちながらプロダクトを成長させるための指針」と言えると思います。
特にインターフェースの文脈で私が思うことは、「抽象に依存」という言葉が示すとおり我々開発者にとって物事を抽象化することが最も重要な仕事と言っても過言ではありません。
なぜならば、頭の中で抽象化出来ていない物事のインターフェースを作ることは出来ないからです。
抽象化出来ていないと、UI層で仕様をもみながら行きあたりばったりでコードを書くことになり、結果として「賢いUI」になって行き、可変性の低いソースコードになって行く。
だから、いきなりエディターに向かうのではなく、ドメイン従事者に多くのヒアリングを行い、簡単にでも良いので全体構成を書き出すなどして整理することから始めた方が良い。
開発者が関与するプロダクトの抽象度を上げ、質の高いインターフェースを作り上げることができるかどうかは、その事業ドメインについてどれだけ知り尽くしているかに依存します。
そして、そのインターフェースの抽象度の質によって、そのプロダクトが将来に向けて拡張的で居られるかどうかが決まってしまう。
アーキテクチャーにゴールや正解はなく、常に思考を練り、よりスマートに、よりシンプルにバージョンアップしていかなくてはならないものです。
思考を凝らし、難しいことを単純化するツールとして、クリーンアーキテクチャーの考え方は活用の価値があると思います。