この記事は個人ブログと同じ内容です
データベースを操作する SQL
SQL(Structured Query Language)は、関係データベース管理システム(RDBMS)でデータを管理・操作するための標準化された言語です。データベースに格納された情報を効果的に取得、挿入、更新、削除するために使用されます。
SQLは、テーブルと呼ばれるデータの形式で情報を格納し、クエリを使用してデータベースとの対話を行います。初心者にとっても覚えやすく、構文も直感的であるため、多くのデータベース管理システムで広く利用されています。
SQL の歴史は古く、1970 年代初頭に IBM 社において、Edgar F. Codd(エドガー・F・コッド)博士によって革新的な関係モデルが提唱されたことから始まりました。
現代においては、MySQL, PostgreSQL, BigQuery などではこの SQL をベースとしたクエリを組み立て、発行(実行)していくものになっており、データベース製品が異なっても、ベースの文法は同じものです。
クエリを効率良く書こう
データを取得するクエリを組み立てる際のクエリの書き方は必ず 1 つというわけではありません。文法など、クエリとして成立していれば異なった書き方でも同じ結果を取得することができます。
例えば、本の売上を収録しているテーブルがあったとします。
> SELECT * FROM book_salses GROUP BY sale_date; |---------|-----------| | book_id | sale_date | |---------|-----------| | 1 | 2024-01-01| | 1 | 2024-01-01| | 1 | 2024-01-01| | 1 | 2024-01-01| . . . | 1 | 2024-01-05| |---------|-----------|
このテーブルを操作して、本の日次販売数と、累計販売数を出力します。
このとき、以下 2 つの SQL クエリは同じ結果を出力します。
-- クエリ 1 SELECT daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count, SUM(t1.sales_count) as cumulative_sales_volume FROM ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) as daily_salses INNER JOIN ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) t1 ON daily_salses.sale_date >= t1.sale_date GROUP BY daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count ; -- クエリ 2 SELECT sale_date, book_id, COUNT(book_id) as sales_count, SUM(COUNT(book_id)) OVER (PARTITION BY book_id ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_sales_volume FROM book_sales GROUP BY sale_date, book_id ;
出力される結果は 2 つのクエリとも同じ以下が出力されます。
| sale_date | book_id | sales_count | cumulative_sales_volume |
|---|---|---|---|
| 2024-01-01 | 1 | 12 | 12 |
| 2024-01-02 | 1 | 12 | 24 |
| 2024-01-03 | 1 | 12 | 36 |
| 2024-01-04 | 1 | 12 | 48 |
| 2024-01-05 | 1 | 12 | 60 |
2 つのクエリを見比べてみてどう感じるでしょう。少なくとも、ぱっと見て記述量が明らかに違うことはわかると思います。記述量が多いということは、それだけクエリを組み立てるのにも時間がかかりそうですね。
「メラ!」で唱えられる魔法と、「汝の身は我が下に、我が命運は汝の剣に ブツブツブツブツ......」みたいな詠唱して唱える魔法では魔法を発動するまでにかかる時間が違うのと似たようなものです。(仕事は早く済ませたい)
このように、どんなクエリだとしても欲しい結果が得られば何でも良いのかというと必ずしもそうとは言えません。クエリによってパフォーマンスに違いがあったり、可読性にも違いがあります。
今回は、最近では当たり前になりつつある記法を使って、クエリを効率よく組み立てていく方法を見ていきましょう。
CTE
CTE(Common Table Expressions)は、SQLで一時的な結果セットを定義するための構文です。主に複雑なクエリをより読みやすく、管理しやすくするために使用されます。CTEを使用すると、サブクエリやビューと同様に、クエリ内で一時的なテーブルを作成し、それを後続の処理で参照することができます。特に再帰的なクエリや複数の階層的なクエリを処理する際に、CTEは非常に有用です。
最初に見た、1 つめのクエリを見てみましょう。
-- クエリ 1 SELECT daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count, SUM(t1.sales_count) as cumulative_sales_volume FROM ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) as daily_salses INNER JOIN ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) t1 ON daily_salses.sale_date >= t1.sale_date GROUP BY daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count ;
このクエリでは、全く同じクエリを記述している箇所があります。FROM 句の中と INNER JOIN 句の中で行っている SELECT 文です。
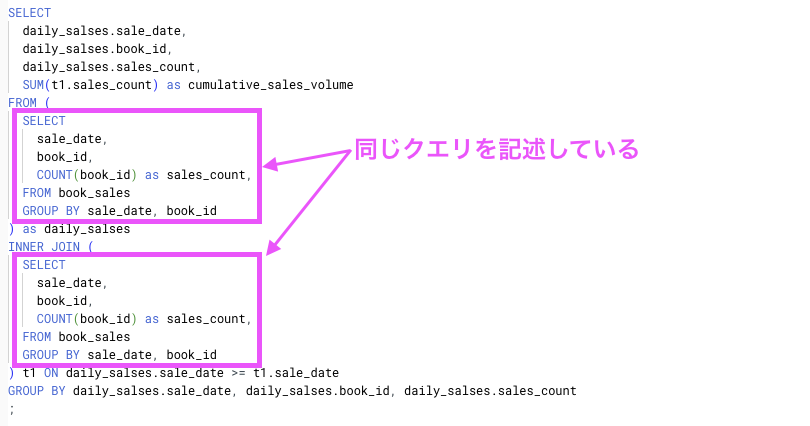
こういった同じクエリを記述している箇所を、CTE を使えば共通化することができます。CTE は WITH 句を使って定義します。
WITH <cte_name> AS (<query>)
WITH daily_salses AS ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) SELECT daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count, SUM(t1.sales_count) as cumulative_sales_volume FROM daily_salses INNER JOIN daily_salses t1 ON daily_salses.sale_date >= t1.sale_date GROUP BY daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count ;
共通化したいクエリを CTE として定義し、実際の SELECT 文で利用することによって、クエリ全体をすっきりさせることができます。
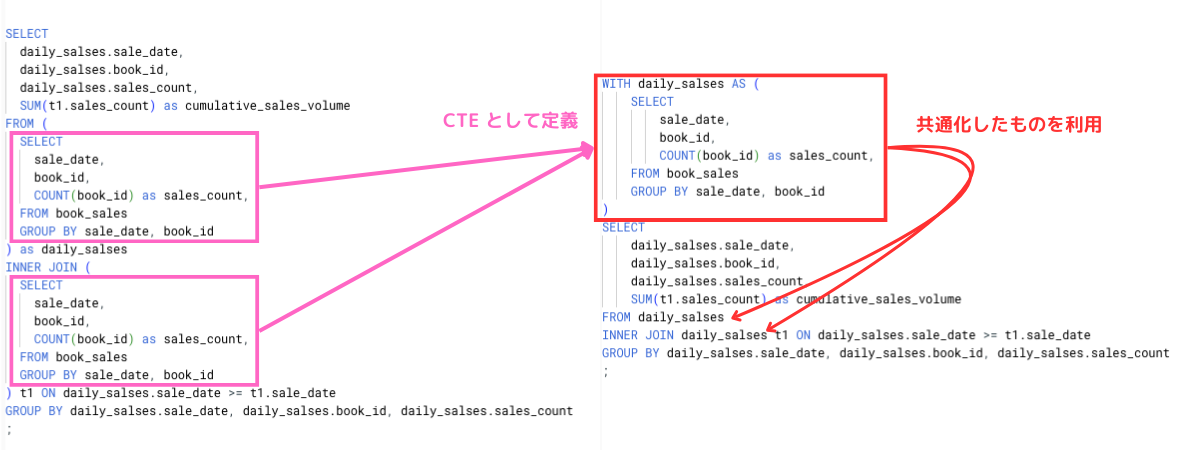
CTE はサブクエリに似ていますが、再利用可能で名前を付けられるので、長いクエリをモジュール化して見通しを良くできるというメリットがあります。特に複数の派生テーブルを作成する必要がある場合に、CTE は非常に便利です。
Window 関数
Window 関数は、SQLでデータセット内の特定の行に対して計算を行うための機能です。通常の集約関数(例:SUM、AVG、COUNT)とは異なり、Window 関数は各行に対して個別に計算を実行し、その結果を結果セットの各行に返します。
前項で CTE に触れたので、それを適用させた先ほどのクエリを見てみましょう。
WITH daily_salses AS ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) SELECT daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count, SUM(t1.sales_count) as cumulative_sales_volume FROM daily_salses INNER JOIN daily_salses t1 ON daily_salses.sale_date >= t1.sale_date GROUP BY daily_salses.sale_date, daily_salses.book_id, daily_salses.sales_count ;
累計を出すために同じ daily_salses を join させ、再度 GROUP BY を実行し累計を SUM() 関数で集計しています。少し冗長な気もしますね。でも累計を出したいのだから仕方ない。
ところが、Window 関数を使えば、上記のような記述をしなくても累計を算出できます。以下は、Window 関数として SUM() 関数を用いた方法です。
WITH daily_salses AS ( SELECT sale_date, book_id, COUNT(book_id) as sales_count, FROM book_sales GROUP BY sale_date, book_id ) SELECT sale_date, book_id, sales_count, SUM(sales_count) OVER (PARTITION BY book_id ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_sales_volume FROM daily_salses ;
SELECT 句の最後で Window 関数として SUM() 関数を使用しています。再度の JOIN も GROUP BY も不要になりました。
これらはもちろん、同じ結果を出力します。
| sale_date | book_id | sales_count | cumulative_sales_volume |
|---|---|---|---|
| 2024-01-01 | 1 | 12 | 12 |
| 2024-01-02 | 1 | 12 | 24 |
| 2024-01-03 | 1 | 12 | 36 |
| 2024-01-04 | 1 | 12 | 48 |
| 2024-01-05 | 1 | 12 | 60 |
Window 関数の基本書式
Window 関数の基本的な構文は以下のようになります。
<ウィンドウ関数>([引数]) OVER ( [PARTITION BY 列1, 列2, ...] [ORDER BY 列1 [ASC|DESC], 列2 [ASC|DESC], ...] [ROWS | RANGE 制約] )
- <ウィンドウ関数> - 使用する Window 関数 (SUM、AVG、COUNT、RANK、DENSE_RANK、ROW_NUMBER など)
- [引数] - Window 関数に渡す引数 (カラム名など)
- PARTITION BY - データをグループ化する列を指定 (オプション)
- ORDER BY - Window 内の並び順を指定 (一部の関数で必須)
- ROWS | RANGE - Window のレンジを行ベースまたは値ベースで指定 (オプション)
Window 関数は OVER 句の中で設定されます。PARTITION BY で指定した列でデータを分割し、ORDER BY で指定した順序でウィンドウが作成されます。さらに ROWS または RANGE を使ってウィンドウのレンジを細かく制御できます。
今回の例に置き換えると、以下のようなことになります。
SUM(sales_count) OVER (PARTITION BY book_id ORDER BY sale_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_sales_volume
「book_id ごとに計算します。それぞれは sale_date 昇順で並べます。計算するウィンドウフレームの開始位置は最初の行から、現在の行までの全ての行です。」
SUM(sales_count) -- 加法集計します OVER ( -- book_id ごとに集計します PARTITION BY book_id -- sale_date を昇順に並び替えた上で集計します ORDER BY sale_date /* * Window の範囲指定は、 * ROWS BETWEEN * UNBOUNDED PRECEDING(最初の行) * AND(から) * CURRENT ROW(現在行) * までです */ ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) as cumulative_sales_volume
こんな感じで、Window 関数は、加法集計以外にも、データの順序付け、ランキングなどのさまざまな用途に使用できます。例えば、各顧客の売上を日付ごとにランク付けする、直近の日付ごとに合計売上を計算する、あるいは移動平均などの時系列解析を行う際に、Window関数が役立ちます。
どんな関数があるのかについては、以下を参照してください。
パフォーマンスアップにも寄与
Window 関数を使えば無駄な JOIN や GROUP BY を行わなくて済む例を見ましたが、これによって、内部的な処理量も減り、パフォーマンスにも寄与します。
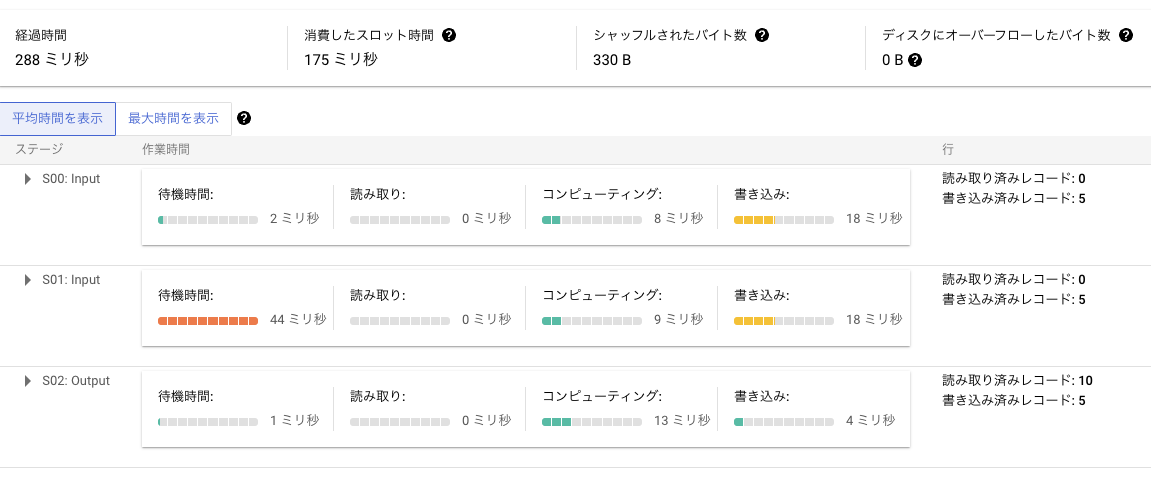
例えば以下は、BigQuery で 2 つのクエリを実行した際のパフォーマンスです。
クエリ 1
クエリ 2
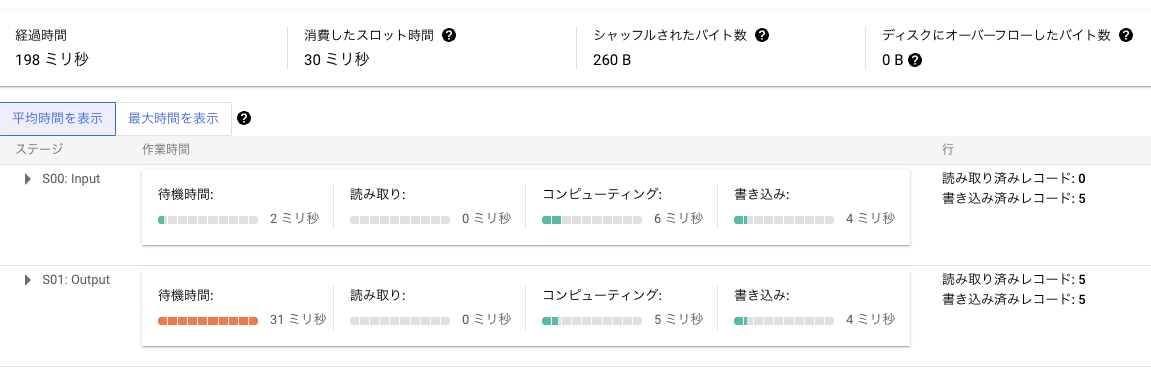
Window 関数を用いたクエリ 2 の方が、JOIN が無くなった分処理量も減っており、パフォーマンスが良くなっています。
BigQuery に限らず、読み込むデータの量や結合数がもっと大きな分析を行う際は、こうしたところで SQL クエリのパフォーマンスが大きく変わってきますので、地味に大切なポイントです。
まとめ
SQL クエリを効率よく書くために、CTE と Window 関数を見ていきました。
CTE で共通化すれば、再利用できて便利ですし、それによって冗長な記述を排除すれば、可読性も上がります。自分ひとりでクエリを組み立て使用している分には良いですが、チームでクエリを管理したり、レビューしたりする時には、クエリの可読性はアプリケーションのプログラミングと同じくらい重要です。
Window 関数もまた、記述量を減らせる上、パフォーマンスもアップさせることができます。分析時には多くのクエリを定義することも多いため、一つ一つのクエリにおいて最大のパフォーマンスで実行できるように定義していけると、最終的なパフォーマンスにも無駄なく実行できます。
まさにクエリのパフォーマンスは「塵も積もれば山となる」です。
CTE も Window 関数も、SQL が 1970 年に生まれたことを考えれば比較的新しい機能ですが、現代においてはそこそこお馴染みになっているものです。
代表的なデータベース製品である MySQL は 8.0 から、PostgreSQL は 8.4 から Window 関数が利用できます。
資料やサンプルも沢山あると思いますので、ぜひ活用してみてください。
現在 back check 開発チームでは一緒に働く仲間を募集中です。 herp.careers