この記事は個人ブログと同じ内容です
ログの分析をどのような手段で実施するか
ログの多くはテキストファイルであることが多く、DB に格納されていないことがほとんどです。
しかも、ログファイルは大抵、複数の環境から吐き出されたり、量や時間で分割して出力されたりするため、複数のファイルにまたがっていることがほとんど。
そんな環境下でも、ログ分析の環境を簡単に構築し、柔軟に解析していけるのが、Amazon Athena です。
AWS Athena
AWS Athena は、Amazon S3 に保存されたデータを標準的な SQL を使って直接分析できるインタラクティブなクエリサービスです。サーバーの管理や設定は不要で、数秒でクエリを実行し、結果を取得できます。
使いやすい上に瞬時にログ分析の環境を用意できる。
最初に結論からお伝えしておくと、ログ分析に Athena を用いるのはとてもオススメです。
特に調査や障害など、急にスポットでログ分析が発生した時などは瞬時に分析環境を構築できるため、初動が非常に早くなります。
前提とデータの用意
今回は、ログの分析を行ってみます。
以下のフォーマットを持つ、nginx ライクなログを 1000 行、擬似的に作成しました。API のアクセスログを模しています。
192.168.0.247 - - [2024-02-18 14:56:55] "POST /api/v1/tasks/24361 HTTP/1.1" 201 7101 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36" 192.168.0.142 - - [2024-02-18 14:56:56] "GET /api/v1/messages/20050 HTTP/1.1" 200 2942 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36" . . .
この access.log を、 S3 のバケットに配置してあります。
データベース作成
まずは、Athena でデータベースを作成します。初期は default になっています。データベースを作成せずに default のまま使うこともできます。
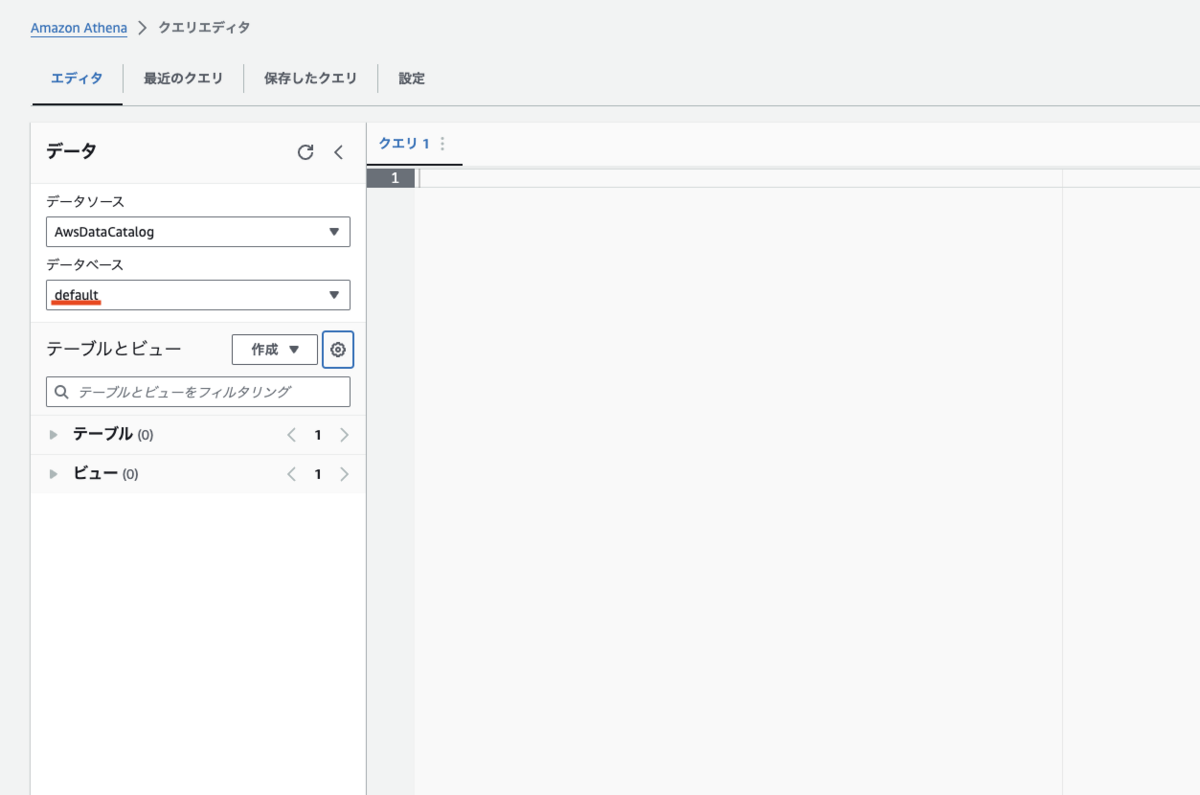
エディターにデータベース作成のクエリを入力し、実行ボタンを押下します。
CREATE DATABASE log_analysis;
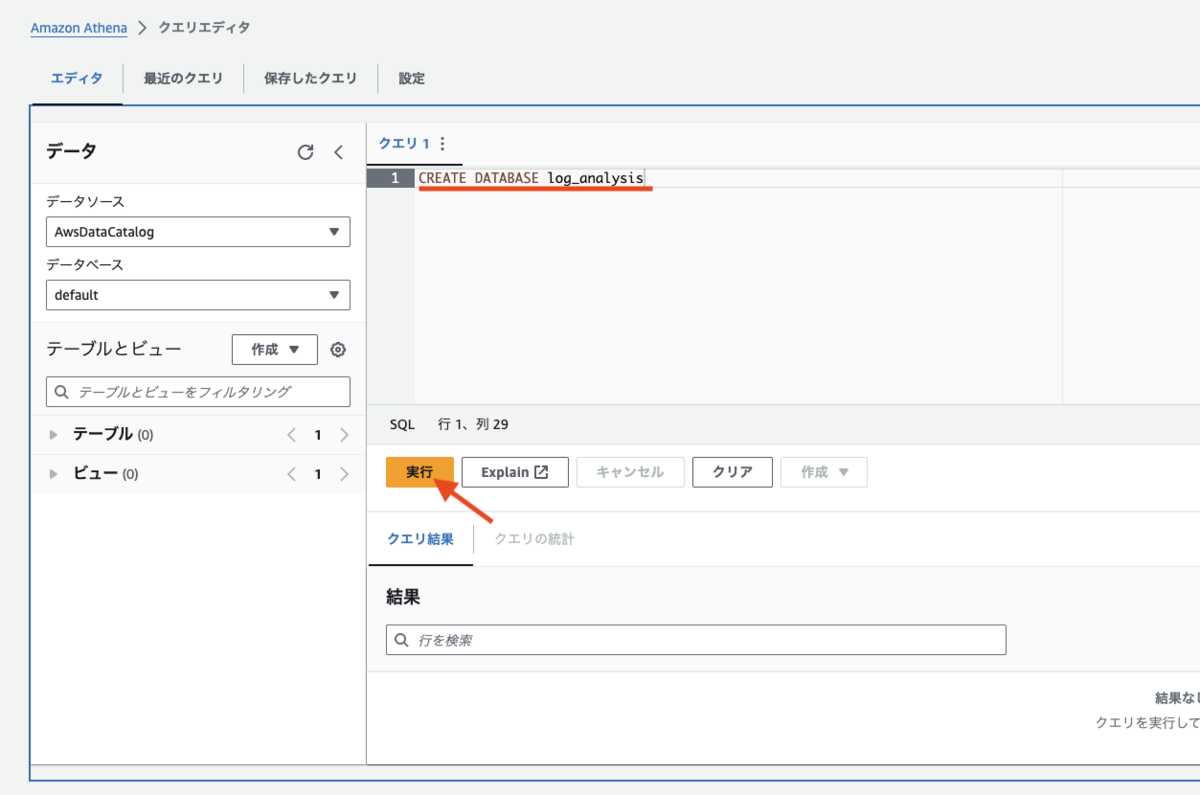
実行が成功すると、左メニューのデータベースのセレクトボックスから、log_analysis を選択できるようになります。
テーブル作成
作成したデータベース log_analysis にテーブルを作成していきます。
作成テーブルは、最初に用意して S3 に配置したログのテーブルです。
左メニュー「テーブルとビュー」に「作成」というセレクトボックスがあります。そこから、「S3バケットデータ」を選択します。
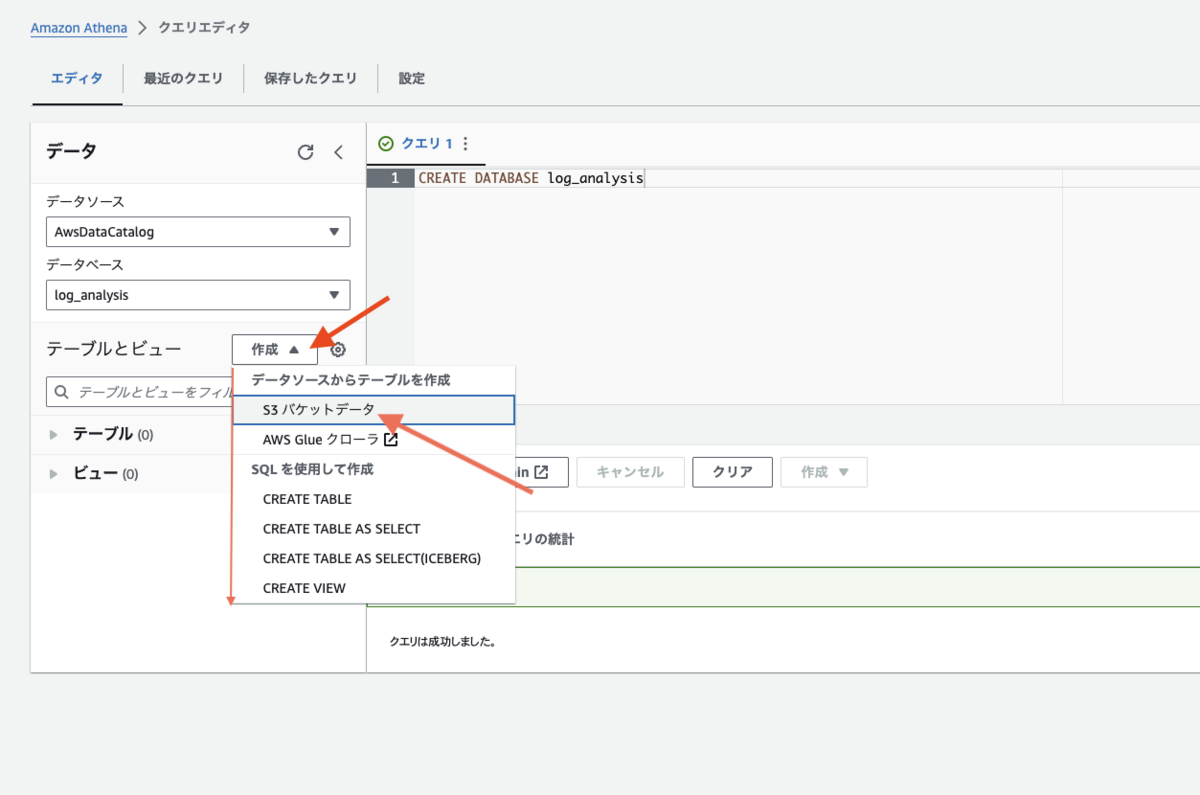
「S3 バケットデータからテーブルを作成」という画面に遷移します。ここで必要な入力を行い、テーブルを作成します。
テーブルの詳細セクションでは、テーブル名とその説明を入力します。データベース選択セクションでは、先程作成した log_analysis を選択します。
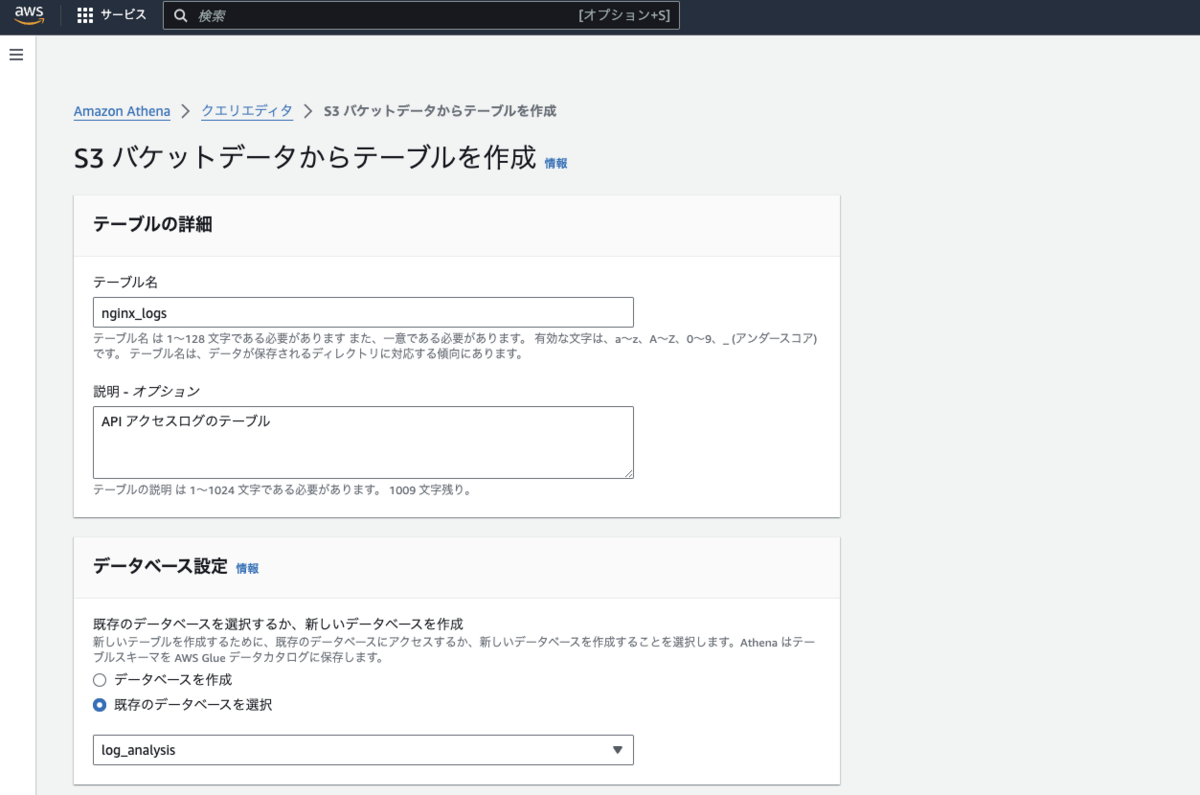
データセットセクションでは、ログファイルが設定されている S3 のバケット、ディレクトリを指定します。
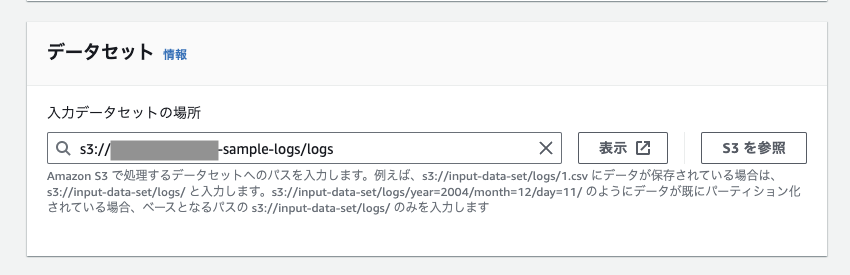
データ形式セクションでは、ファイル(今回でいうとログファイル)のパースに必要な情報を指定します。
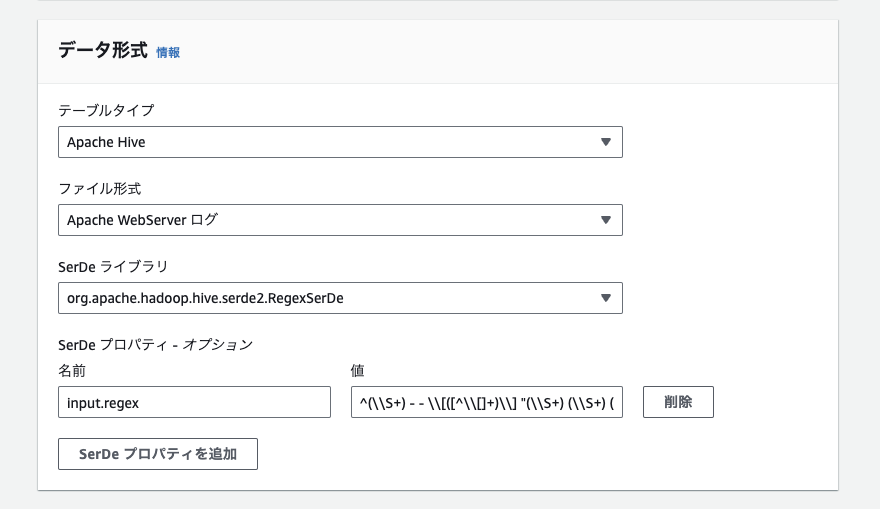
今回、ログは正規表現でパースするため、このような指定になっています。
- テーブルタイプ
- Apache Hive
- ファイル形式
- Apache WebServer ログ
- SerDe ライブラリ
- SerDe プロパティ - オプション
- 名前: input.regex
- 値:
^(\\S+) - - \\[([^\\[]+)\\] "(\\S+) (\\S+) (\\S+)" (\\S+) (\\S+) "(\\S+)" "(.*)"
列の詳細セクションでは、作成するテーブルのカラムを定義します。
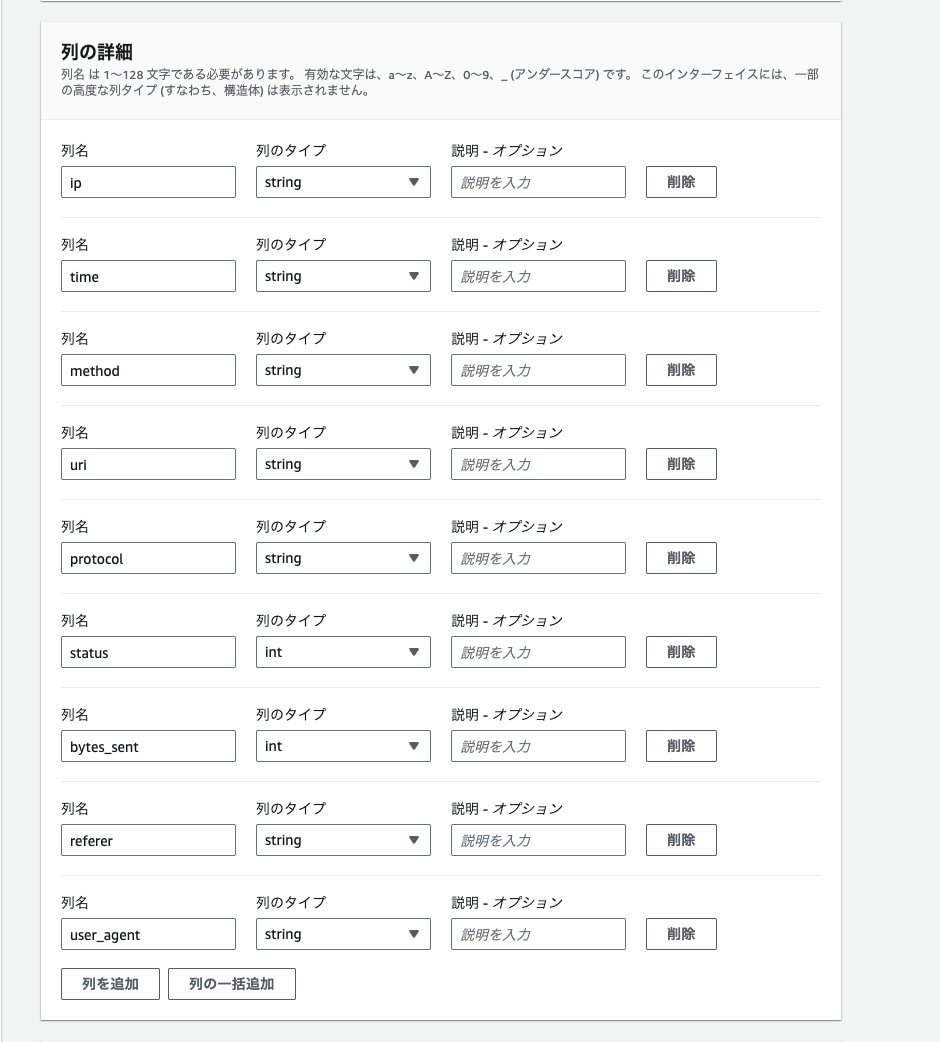
- ip: string,
- time: string,
- method: string,
- uri: string,
- protocol: string,
- status: int,
- bytes_sent: int,
- referer: string,
- user_agent: string
注意点は、データ形式セクションでログのパースを正規表現で記載しましたが、正規表現によってキャプチャ(抽出)する数と、ここで指定するカラムの数は同じである必要があります。
このセクション以降はオプションなので今回は設定しません。最下部にある「テーブルを作成」ボタンを押下すると、テーブルが作成されます。
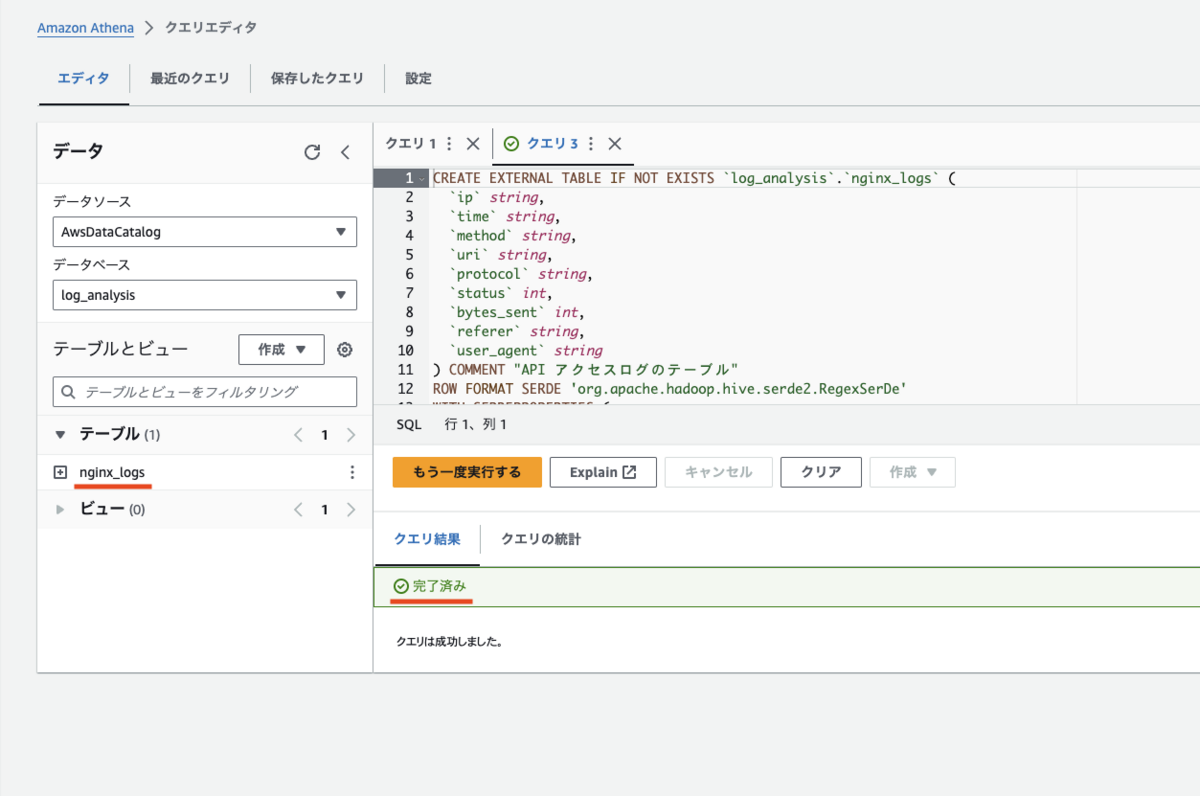
-- DDL CREATE EXTERNAL TABLE IF NOT EXISTS `mydatabase`.`nginx_logs` ( `ip` string, `time` string, `method` string, `uri` string, `protocol` string, `status` int, `bytes_sent` string, `referer` string, `user_agent` string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'input.regex' = '^(\\S+) - - \\[([^\\[]+)\\] "(\\S+) (\\S+) (\\S+)" (\\S+) (\\S+) "(\\S+)" "(.*)"' ) STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://sample-logs/logs/' ;
クエリを実行しログデータを取得する
テーブルが作成されたので、実際にクエリを実行してログのデータを取得してみます。
SELECT * FROM nginx_logs ;
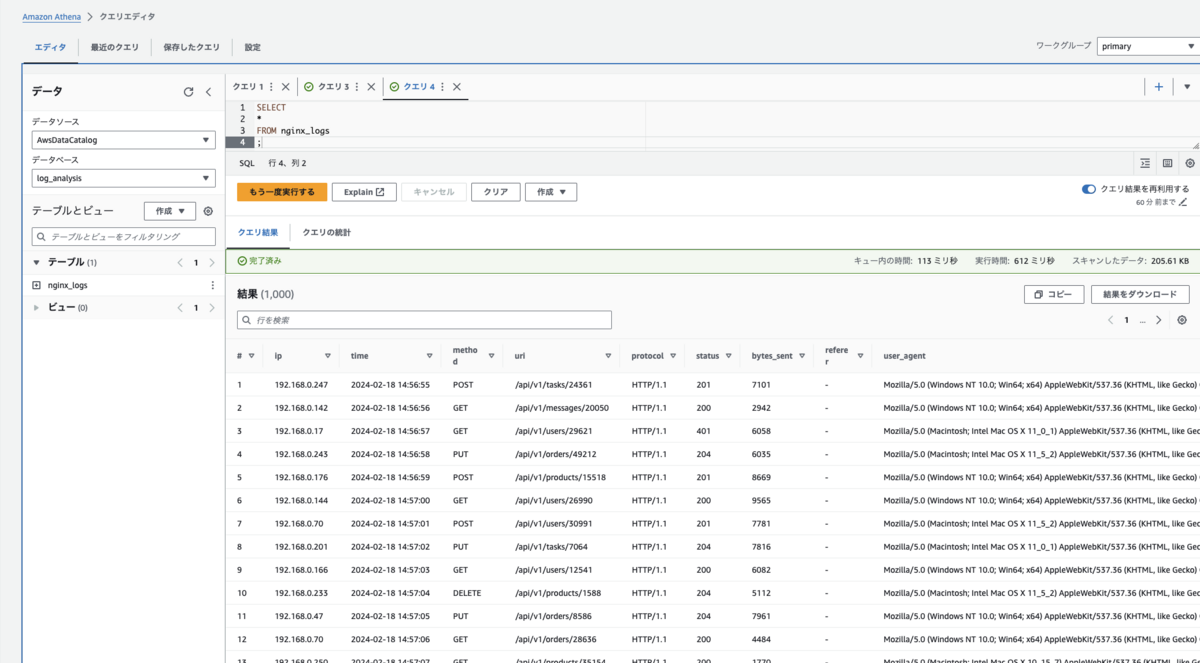
取得できました。SQL を記述してログのデータが取得できるのはとても利便性が高いですね。
| ip | time | method | uri | protocol | status | bytes_sent | referer | user_agent |
|---|---|---|---|---|---|---|---|---|
| 192.168.0.247 | 2024-02-18 14:56:55 | POST | /api/v1/tasks/24361 | HTTP/1.1 | 201 | 7101 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.142 | 2024-02-18 14:56:56 | GET | /api/v1/messages/20050 | HTTP/1.1 | 200 | 2942 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 |
| 192.168.0.17 | 2024-02-18 14:56:57 | GET | /api/v1/users/29621 | HTTP/1.1 | 401 | 6058 | - | Mozilla/5.0 (Macintosh; Intel Mac OS X 1101) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.1234.5678 Safari/537.36 |
| 192.168.0.243 | 2024-02-18 14:56:58 | PUT | /api/v1/orders/49212 | HTTP/1.1 | 204 | 6035 | - | Mozilla/5.0 (Macintosh; Intel Mac OS X 1152) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.176 | 2024-02-18 14:56:59 | POST | /api/v1/products/15518 | HTTP/1.1 | 201 | 8669 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.1234.5678 Safari/537.36 |
| 192.168.0.144 | 2024-02-18 14:57:00 | GET | /api/v1/users/26990 | HTTP/1.1 | 200 | 9565 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.70 | 2024-02-18 14:57:01 | POST | /api/v1/users/30991 | HTTP/1.1 | 201 | 7781 | - | Mozilla/5.0 (Macintosh; Intel Mac OS X 1152) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.201 | 2024-02-18 14:57:02 | PUT | /api/v1/tasks/7064 | HTTP/1.1 | 204 | 7816 | - | Mozilla/5.0 (Macintosh; Intel Mac OS X 1101) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.1234.5678 Safari/537.36 |
| 192.168.0.166 | 2024-02-18 14:57:03 | GET | /api/v1/users/12541 | HTTP/1.1 | 200 | 6082 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.233 | 2024-02-18 14:57:04 | DELETE | /api/v1/products/1588 | HTTP/1.1 | 204 | 5112 | - | Mozilla/5.0 (Macintosh; Intel Mac OS X 1152) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.9876.54321 Safari/537.36 |
| 192.168.0.47 | 2024-02-18 14:57:05 | PUT | /api/v1/orders/8586 | HTTP/1.1 | 204 | 7961 | - | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36 |
ログデータの分析
SQL でログデータを分析していけるということで、簡単な分析を行ってみます。
エンドポイントの成功率・エラー率
各エンドポイントの成功率やエラー率を算出してみます。
WITH log_with_endpoint_added AS ( SELECT method, regexp_extract(uri, '^/api/v1/\w+') as endpoint, status FROM nginx_logs ) , log_with_call_count_added AS ( SELECT method, endpoint, status, status / 100 as status_class, COUNT(endpoint) as call_count FROM log_with_endpoint_added GROUP BY method, endpoint, status ) , number_results_per_endpoint AS ( SELECT endpoint, method, SUM(call_count) as all_count, SUM(CASE WHEN status_class = 2 THEN call_count ELSE 0 END) as succeeded_count, SUM(CASE WHEN status_class = 4 THEN call_count ELSE 0 END) as client_error_count, SUM(CASE WHEN status_class = 5 THEN call_count ELSE 0 END) as server_error_count FROM log_with_call_count_added GROUP BY endpoint, method ) SELECT endpoint, method, all_count as count, CONCAT(CAST(ROUND((CAST(succeeded_count as DOUBLE) / all_count) * 100, 2) as VARCHAR), '%') as succeeded_rate, CONCAT(CAST(ROUND((CAST(client_error_count as DOUBLE) / all_count) * 100, 2) as VARCHAR), '%') as client_error_rate, CONCAT(CAST(ROUND((CAST(server_error_count as DOUBLE) / all_count) * 100, 2) as VARCHAR), '%') as server_error_rate FROM number_results_per_endpoint ORDER BY server_error_rate desc ;
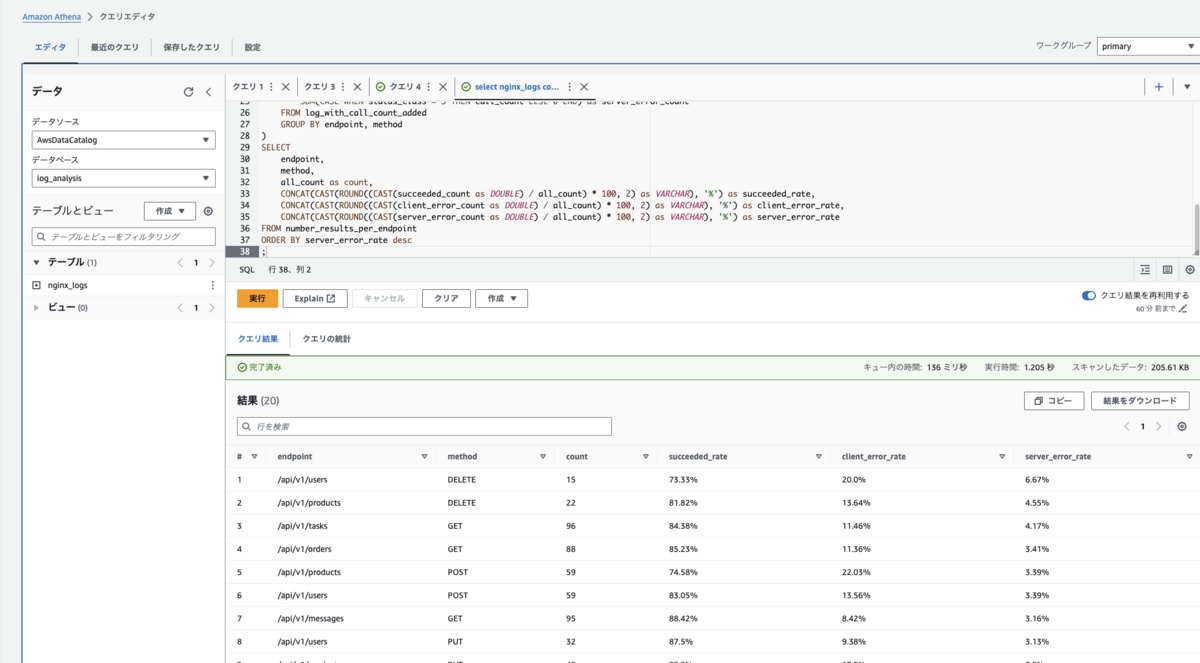
| endpoint | method | count | succeeded_rate | client_error_rate | server_error_rate |
|---|---|---|---|---|---|
| /api/v1/users | DELETE | 15 | 73.33% | 20.00% | 6.67% |
| /api/v1/products | DELETE | 22 | 81.82% | 13.64% | 4.55% |
| /api/v1/tasks | GET | 96 | 84.38% | 11.46% | 4.17% |
| /api/v1/orders | GET | 88 | 85.23% | 11.36% | 3.41% |
| /api/v1/products | POST | 59 | 74.58% | 22.03% | 3.39% |
| /api/v1/users | POST | 59 | 83.05% | 13.56% | 3.39% |
| /api/v1/messages | GET | 95 | 88.42% | 8.42% | 3.16% |
| /api/v1/users | PUT | 32 | 87.50% | 9.38% | 3.13% |
| /api/v1/products | PUT | 40 | 80.00% | 17.50% | 2.50% |
| /api/v1/products | GET | 88 | 79.55% | 18.18% | 2.27% |
| /api/v1/users | GET | 91 | 78.02% | 19.78% | 2.20% |
| /api/v1/messages | POST | 49 | 83.67% | 14.29% | 2.04% |
| /api/v1/tasks | POST | 59 | 88.14% | 10.17% | 1.69% |
| /api/v1/messages | PUT | 29 | 82.76% | 17.24% | 0.00% |
| /api/v1/messages | DELETE | 17 | 100.00% | 0.00% | 0.00% |
| /api/v1/orders | DELETE | 18 | 94.44% | 5.56% | 0.00% |
| /api/v1/tasks | DELETE | 8 | 87.50% | 12.50% | 0.00% |
| /api/v1/tasks | PUT | 39 | 92.31% | 7.69% | 0.00% |
| /api/v1/orders | PUT | 40 | 82.50% | 17.50% | 0.00% |
| /api/v1/orders | POST | 56 | 89.29% | 10.71% | 0.00% |
SQL でクエリを書けるので、集計などもこうして柔軟に分析を行っていけます。
複数リソースを用いた分析
Athena を使えば、ログファイルを柔軟に分析できることがわかりました。次に、ログファイルだけではなく、別のリソースを掛け合わせて使ってみます。
ログファイル × CSV ファイル
先ほどのログファイルのデータを使って、このアプリケーション API において使われていないエンドポイントを抽出してみます。
新たに、エンドポイントの一覧を収録した CSV ファイルを用意しました。
endpoints.csv
/api/v1/products /api/v1/orders /api/v1/users /api/v1/messages /api/v1/tasks /api/v1/bookmarks /api/v1/friends
表というよりは、エンドポイントの一覧が書き連ねてあるだけの CSV ファイルです。
これを S3 に配置します。
この CSV に対応するテーブルを Athena に作成します。(nginx_logs テーブルを作成したのと同じ要領で、CSV をパースする設定にてテーブルを作成します。)
-- DDL CREATE EXTERNAL TABLE IF NOT EXISTS `mydatabase`.`endpoints` (`endpoint` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ('field.delim' = ',') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://sample-logs/documents/' TBLPROPERTIES ('classification' = 'csv');
作成した endpoints テーブルを SELECT してみます。
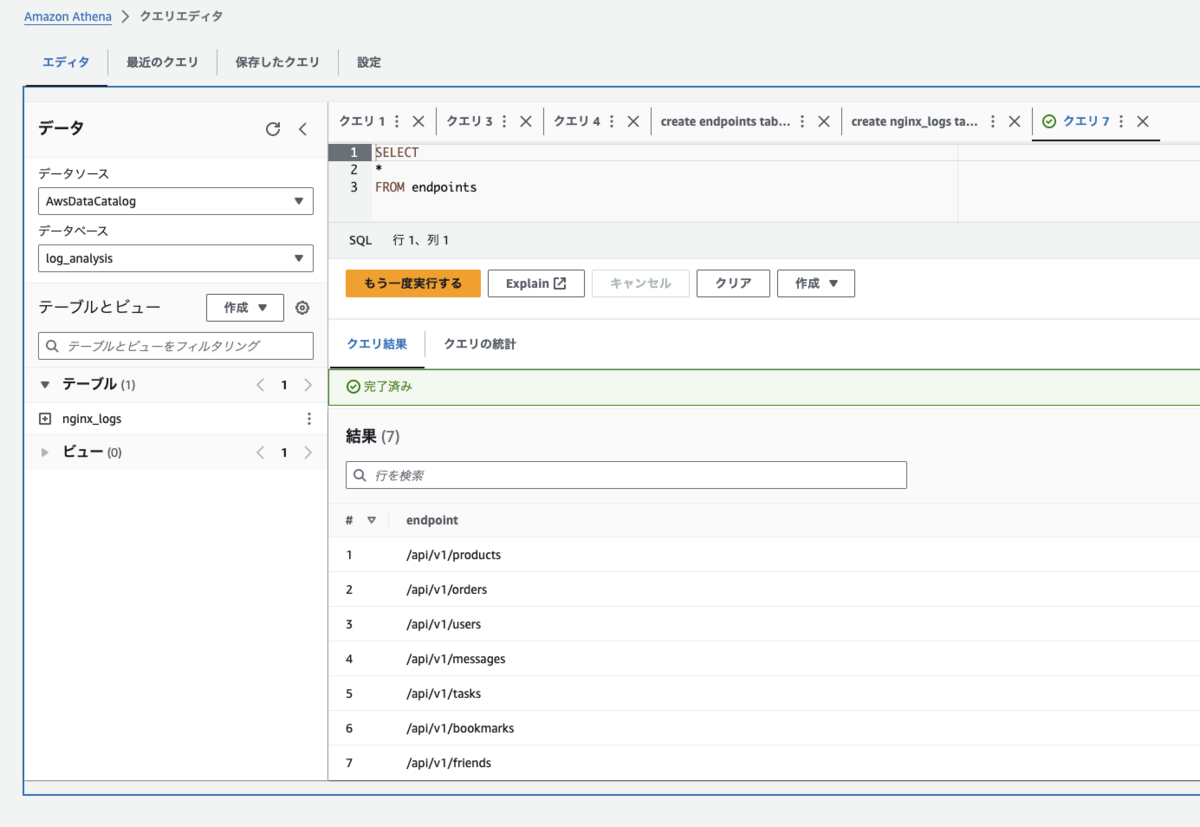
あとは、先程の nginx_logs テーブルのデータにこの endpoints テーブルのデータをぶつければ、使用されていないエンドポイントが抽出できます。
WITH log_with_endpoint_added AS ( SELECT method, regexp_extract(uri, '^/api/v1/\w+') as endpoint, status FROM nginx_logs ) , endpoint_used AS ( SELECT DISTINCT endpoint FROM log_with_endpoint_added ) SELECT * FROM endpoints WHERE not exists( SELECT * FROM endpoint_used WHERE endpoints.endpoint=endpoint_used.endpoint ) ;
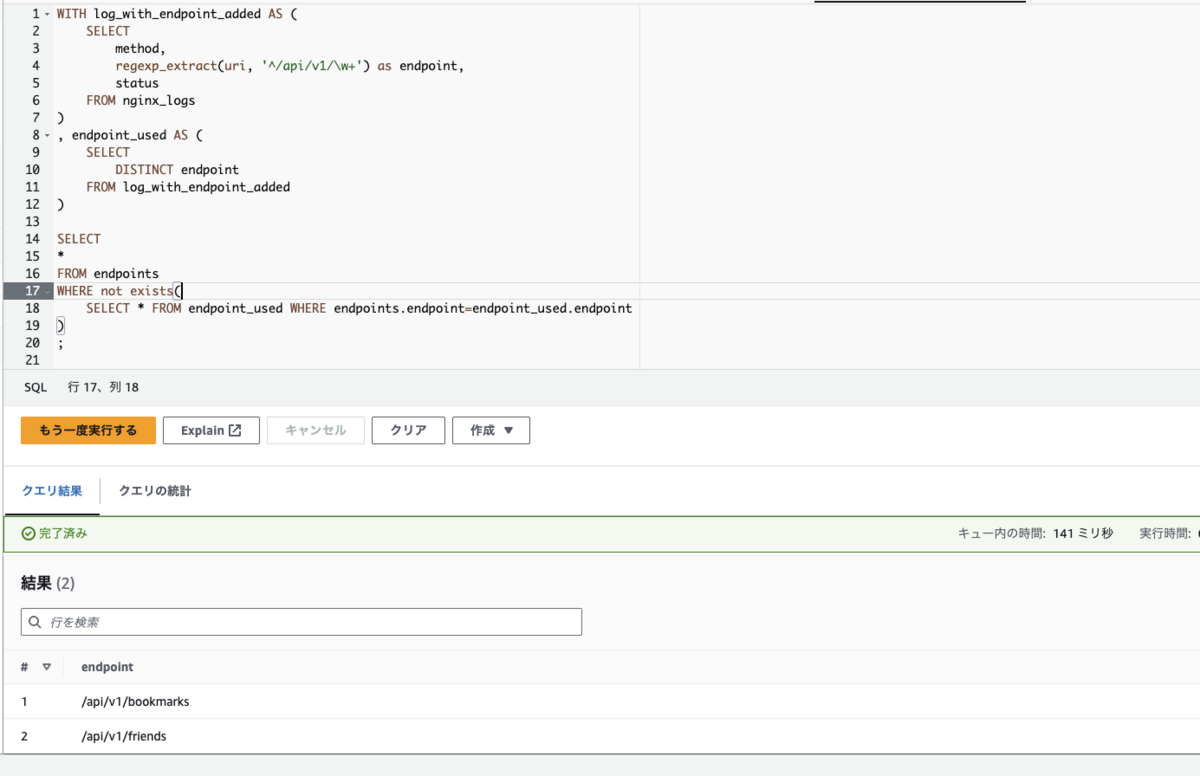
こんな風に、様々な形式のデータを取り込み、分析できる柔軟性を Athena は持ち合わせています。
瞬時に、柔軟に、そして簡単に。
AWS Athena は、標準的な SQL を使用してデータにアクセスできるため、SQL のスキルを持つ多くのユーザーにとって親しみやすい環境です。今回は取り上げませんでしたが、notebook の実行も可能なため、SQL の範囲を超えるような分析も行える点も良いです。
また、データのフォーマットに対する柔軟性も高く、JSON、CSV、Parquet、ORC などのさまざまな形式のデータに対応しています。これにより、さまざまなデータソースからのデータを統合して分析することができます。
個人的には、急なログ分析の必要が生じた際に瞬時に分析環境を構築できる点は、非常に心強く、利便性が高いと感じています。
ログなどの分析を行う際は、Amazon Athena を試してみてください。
現在 back check 開発チームでは一緒に働く仲間を募集中です。 herp.careers