この記事は個人ブログと同じ内容です
JOIN での結合式と、FROM での結合式
テーブル結合といえば JOIN 句が一般的ですが、FROM 句に複数テーブルを指定することでもテーブルを結合できます。例えば、以下 2 つのクエリは全く同じ結果を返します。
SELECT * FROM books INNER JOIN author_book ON books.id = author_book.book_id INNER JOIN authors ON author_book.author_id = authors.id ;
SELECT * FROM books, author_book, authors WHERE books.id = author_book.book_id AND author_book.author_id = authors.id ;
リレーショナルデータベースにおいて上記のようなテーブル結合式は、製品に関わらず広く実装されていますが、例えばこれらは、MySQL がオープンソース化された ver 3.23(2001年)の時点で、両者とも存在する伝統的な結合式です。
では、両者の違いはどこにあるのでしょうか?
(以下、クエリの実行は MySQL 8.0 です)
FROM 句での結合は用途が限定的
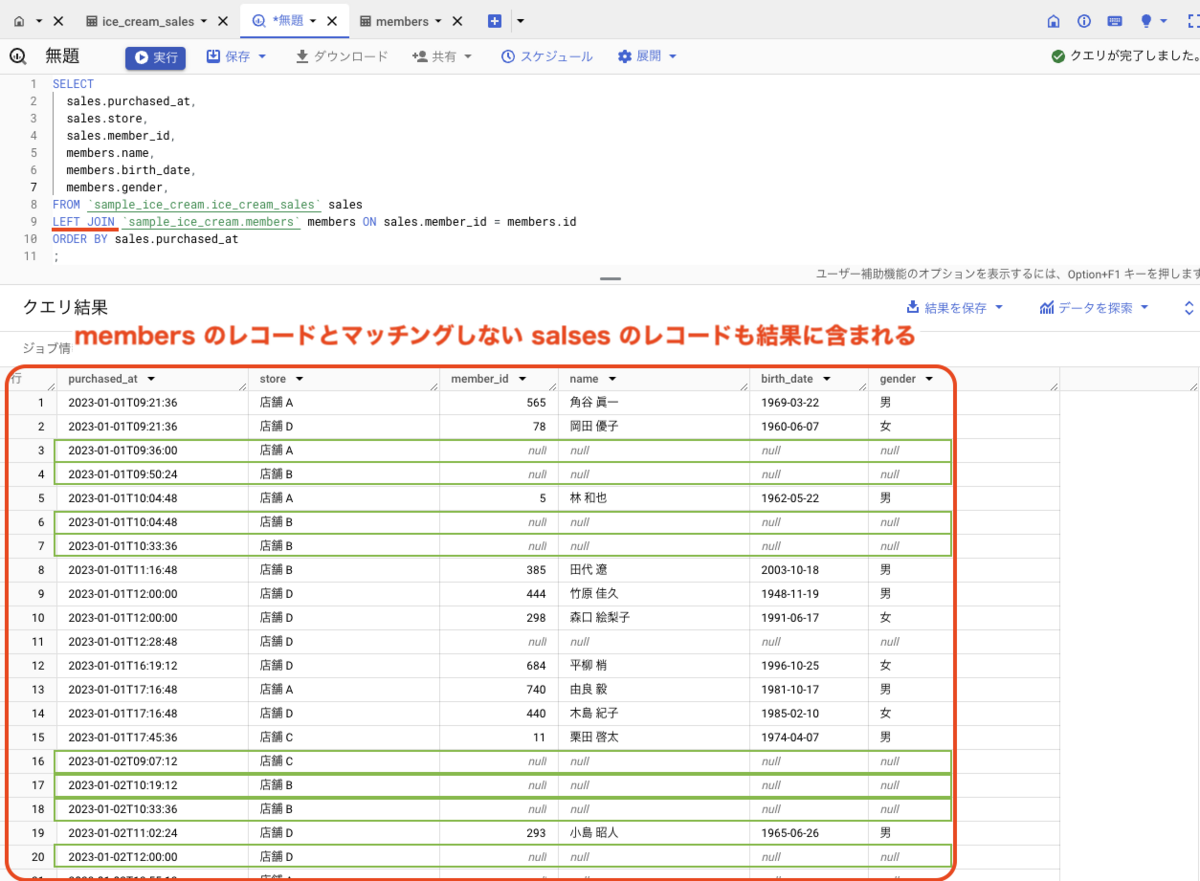
FROM 句に複数テーブルを指定して結合する場合、前提はデカルト積になります。つまり、クロス結合です。
SELECT id, name FROM tbl_a; +----+--------------+ | id | name | +----+--------------+ | 1 | tbl a name 1 | | 2 | tbl a name 2 | | 3 | tbl a name 3 | | 4 | tbl a name 4 | | 5 | tbl a name 5 | +----+--------------+ SELECT id, tbl_a_id, name FROM tbl_c; +----+----------+--------------+ | id | tbl_a_id | name | +----+----------+--------------+ | 1 | 1 | tbl c name 1 | | 2 | 1 | tbl c name 2 | | 3 | 1 | tbl c name 3 | | 4 | 1 | tbl c name 4 | | 5 | 1 | tbl c name 5 | +----+----------+--------------+ -- FROM 句でのテーブル結合 SELECT tbl_a.id, tbl_a.name, tbl_c.tbl_a_id, tbl_c.id, tbl_c.name FROM tbl_a, tbl_c ORDER BY tbl_a.id, tbl_c.id; +----+--------------+----------+----+--------------+ | id | name | tbl_a_id | id | name | +----+--------------+----------+----+--------------+ | 1 | tbl a name 1 | 1 | 1 | tbl c name 1 | | 1 | tbl a name 1 | 1 | 2 | tbl c name 2 | | 1 | tbl a name 1 | 1 | 3 | tbl c name 3 | | 1 | tbl a name 1 | 1 | 4 | tbl c name 4 | | 1 | tbl a name 1 | 1 | 5 | tbl c name 5 | | 2 | tbl a name 2 | 1 | 1 | tbl c name 1 | | 2 | tbl a name 2 | 1 | 2 | tbl c name 2 | | 2 | tbl a name 2 | 1 | 3 | tbl c name 3 | | 2 | tbl a name 2 | 1 | 4 | tbl c name 4 | | 2 | tbl a name 2 | 1 | 5 | tbl c name 5 | | 3 | tbl a name 3 | 1 | 1 | tbl c name 1 | | 3 | tbl a name 3 | 1 | 2 | tbl c name 2 | | 3 | tbl a name 3 | 1 | 3 | tbl c name 3 | | 3 | tbl a name 3 | 1 | 4 | tbl c name 4 | | 3 | tbl a name 3 | 1 | 5 | tbl c name 5 | | 4 | tbl a name 4 | 1 | 1 | tbl c name 1 | | 4 | tbl a name 4 | 1 | 2 | tbl c name 2 | | 4 | tbl a name 4 | 1 | 3 | tbl c name 3 | | 4 | tbl a name 4 | 1 | 4 | tbl c name 4 | | 4 | tbl a name 4 | 1 | 5 | tbl c name 5 | | 5 | tbl a name 5 | 1 | 1 | tbl c name 1 | | 5 | tbl a name 5 | 1 | 2 | tbl c name 2 | | 5 | tbl a name 5 | 1 | 3 | tbl c name 3 | | 5 | tbl a name 5 | 1 | 4 | tbl c name 4 | | 5 | tbl a name 5 | 1 | 5 | tbl c name 5 | +----+--------------+----------+----+--------------+
ここから更に、WHERE 句を指定することで、内部結合の状態を作り出します。
SELECT tbl_a.id, tbl_a.name, tbl_c.tbl_a_id, tbl_c.id, tbl_c.name FROM tbl_a, tbl_c WHERE tbl_a.id = tbl_c.tbl_a_id ORDER BY tbl_a.id, tbl_c.id; +----+--------------+----------+----+--------------+ | id | name | tbl_a_id | id | name | +----+--------------+----------+----+--------------+ | 1 | tbl a name 1 | 1 | 1 | tbl c name 1 | | 1 | tbl a name 1 | 1 | 2 | tbl c name 2 | | 1 | tbl a name 1 | 1 | 3 | tbl c name 3 | | 1 | tbl a name 1 | 1 | 4 | tbl c name 4 | | 1 | tbl a name 1 | 1 | 5 | tbl c name 5 | +----+--------------+----------+----+--------------+
このように、FROM 句に複数テーブルを指定してテーブルを結合させるのは、クロス結合、ないし内部結合が前提となります。外部結合はできません。
JOIN 句は結合職人
JOIN 句を用いたテーブル結合は、内部結合、外部結合、そしてクロス結合と柔軟に結合式を組み立てられます。まさにテーブル結合のためのセンテンスです。
INNER JOIN tbl_b ON ... LEFT JOIN tbl_b ON ... RIGHT JOIN tbl_b ON ... CROSS JOIN tbl_b
パフォーマンス比較
では、どちらの方がパフォーマンスが良いのでしょうか。
テーブルとデータを用意しました。本と出版の世界の一部を表現しています。
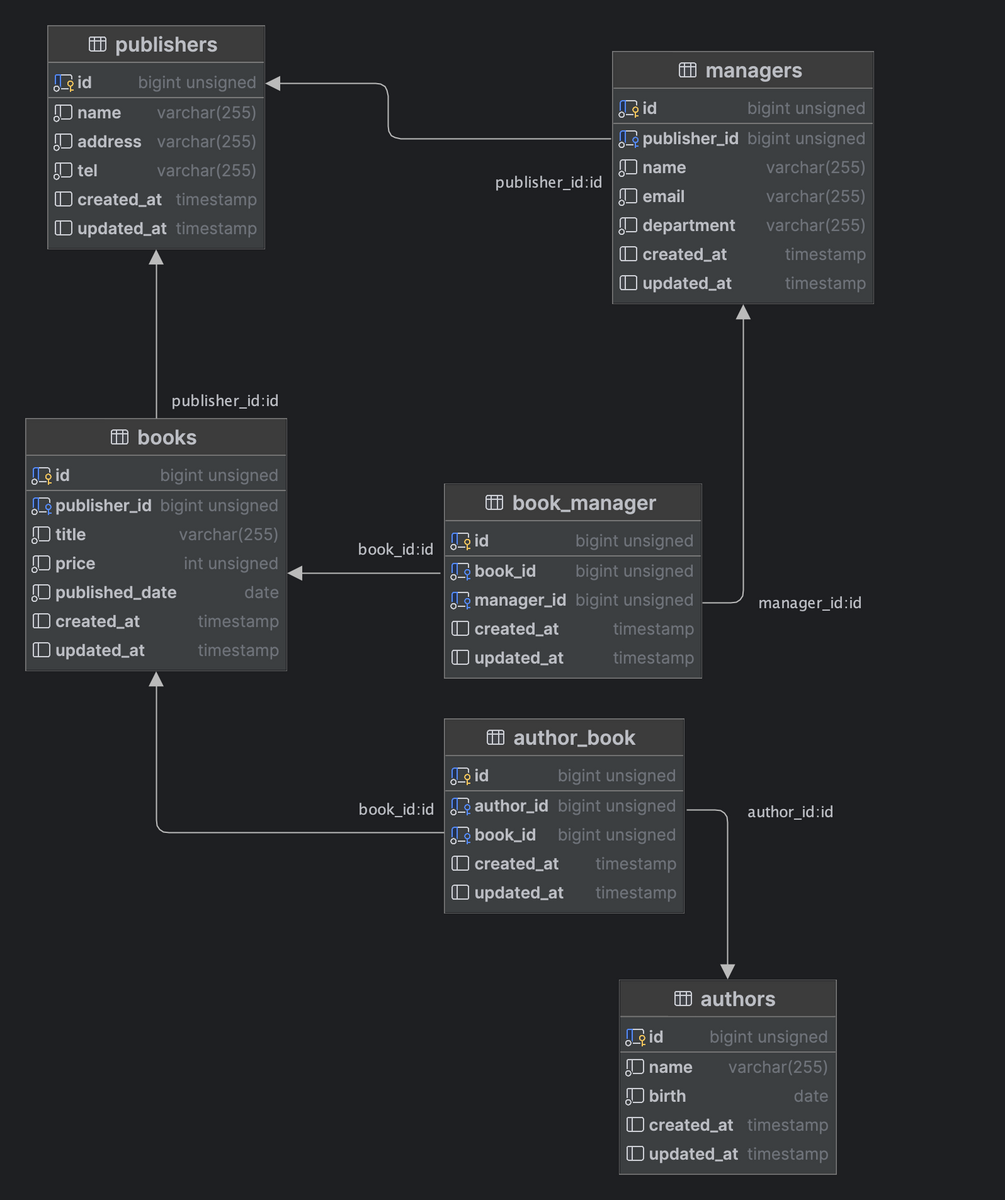
books テーブルには 100 万件のデータを収録し、あとはそれぞれ、1 対 1 または多対多のリレーションです。
| books_count | authors_count | publishers_count | managers_count | author_book_count | book_manager_count |
|---|---|---|---|---|---|
| 1000000 | 100000 | 500 | 5000 | 1000000 | 1000000 |
実行クエリはそれぞれ以下になります。
-- JOIN 句で結合 SELECT * FROM books b INNER JOIN author_book ab ON b.id=ab.book_id INNER JOIN authors a ON ab.author_id=a.id INNER JOIN publishers p on b.publisher_id=p.id INNER JOIN book_manager bm ON b.id=bm.manager_id INNER JOIN managers m ON bm.manager_id=m.id ; -- FROM 句で結合 SELECT * FROM books b, author_book ab, authors a, publishers p, book_manager bm, managers m WHERE b.id=ab.book_id AND ab.author_id=a.id AND b.publisher_id=p.id AND b.id=bm.manager_id AND bm.manager_id=m.id ;
Explain
双方の実行計画を確認しましたが、両方とも全く同じ結果になりました。

| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | managers | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4845 | 100.00 | NULL |
| 1 | SIMPLE | books | NULL | eq_ref | PRIMARY,books_publisher_id_foreign | PRIMARY | 8 | sample.managers.id | 1 | 100.00 | NULL |
| 1 | SIMPLE | publishers | NULL | eq_ref | PRIMARY | PRIMARY | 8 | sample.books.publisher_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | author_book | NULL | ref | author_book_author_id_foreign,author_book_book_id_foreign | author_book_book_id_foreign | 8 | sample.managers.id | 1 | 100.00 | NULL |
| 1 | SIMPLE | authors | NULL | eq_ref | PRIMARY | PRIMARY | 8 | sample.author_book.author_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | book_manager | NULL | ref | book_manager_manager_id_foreign | book_manager_manager_id_foreign | 8 | sample.managers.id | 190 | 100.00 | NULL |
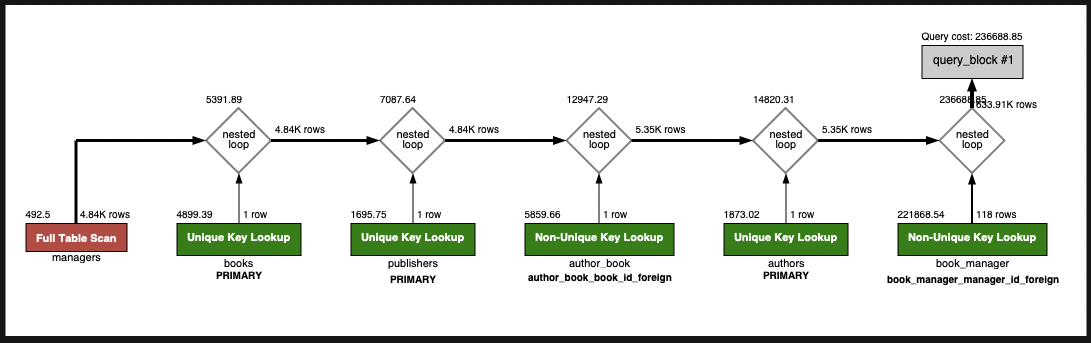
JOIN 句は結合として明示的に意図を示せる句ですが、FROM 句に複数テーブルを指定した場合でも、結合として JOIN 句と同等に処理されることが確認できます。
実行時間
実行計画が同じではあったものの、念のため両者の実行時間を見てみます。
それぞれのクエリを 10 回実行し、その実行時間を確認します。
| 試行回数 | JOIN: Execution time | JOIN: Table lock wait time | FROM: Execution time | FROM: Table lock wait time |
|---|---|---|---|---|
| 1 | 3.84146363 | 0.000132 | 3.70469371 | 0.000019 |
| 2 | 3.86136084 | 0.00015 | 3.85744995 | 0.000007 |
| 3 | 3.78419258 | 0.000018 | 3.77823229 | 0.000034 |
| 4 | 3.87785846 | 0.000184 | 3.80834454 | 0.00011 |
| 5 | 3.78526071 | 0.000016 | 3.81698154 | 0.000121 |
| 6 | 3.83468558 | 0.000057 | 3.79614567 | 0.000031 |
| 7 | 4.27876295 | 0.000013 | 3.76076388 | 0.000011 |
| 8 | 4.43237696 | 0.000016 | 3.82177008 | 0.000158 |
| 9 | 3.82524521 | 0.000123 | 3.98029196 | 0.000102 |
| 10 | 3.76645421 | 0.000033 | 3.88980984 | 0.000116 |
| ---------- | ---------- | ---------- | ---------- | ---------- |
| AVERAGE | 3.928766113 | 0.0000742 | 3.821448346 | 0.0000709 |
実行時間もほとんど差がないといえそうです。
どちらを使うべきか
パフォーマンスには差がないため、結果を抽出するということだけ考えたらどちらを使っても良いということになりますが、テーブル結合を行うならば、JOIN 句を使用しておくのが安全であると考えます。
なぜならば、FROM に複数のを指定した結合は、以下、可読性の面からヒューマンエラーが起こりやすいと感じているからです。
うっかりクロス結合
FROM 句で結合を行う際に最も注意しなければならないのは、結合条件の記述漏れです。
例えば、JOIN 句で結合を行う際は、JOIN 句に対して ON 句を記述することで、各 JOIN に対する結合条件を 1 行ずつ記述していくことができます。これは各テーブルの結合とその結合条件がセットで確認出来るため、条件やそれの指定漏れの確認も行いやすいです。
INNER JOIN author_book ab ON b.id = author_book.book_id -- 結合テーブルと結合条件がセットで記述できる INNER JOIN authors a ON ab.author_id = a.id INNER JOIN publishers p ON b.publisher_id = p.id INNER JOIN book_manager bm ON b.id = bm.manager_id INNER JOIN managers m ON bm.manager_id = m.id
対して、FROM 句で結合を行う際は、WHERE 句にて結合条件を記述していくことになります。
FROM -- 結合テーブル books b, author_book ab, authors a, publishers p, book_manager bm, managers m WHERE b.id = ab.book_id -- books, author_book の結合条件 AND ab.author_id = a.id -- author_book, authors の結合条件 AND b.publisher_id = p.id -- books, publishers の結合条件 AND b.id = bm.manager_id -- books, book_manager の結合条件 AND bm.manager_id = m.id -- book_manager, managers の結合条件
この、結合したいテーブルと結合条件がセットにならない状況は、結合テーブルが増えた際に結合条件の記述漏れを引き起こす可能性が JOIN 句よりもかなり高いといえます。
前述の通り、結合条件を指定しない場合はクロス結合となるため、例えば今回用意したデータであれば、books, author_book の結合条件が未記述の場合、100 万件 × 100 万件 = 1 兆レコードの結果を返そうとすることになり、レコードの多いテーブルではなかなかリスクがあるなといえます。
(ちなみに JOIN 句であっても、結合条件を指定しなければクロス結合になるので注意)
不明瞭な境界線
JOIN 句では、結合後の絞り込みは、例えば以下のように記述するでしょう。
SELECT * FROM tbl_a INNER JOIN tbl_b ON tabl_a.id = tbl_b.tabl_a_id WHERE tbl_b.score > 5 -- 結合後の絞り込み
結合テーブルとその条件があり、結合したデータに対して WHERE 句で絞り込みを行っています。
ON で使用される search_condition は、WHERE 句で使用できるフォームの条件式です。 通常、ON 句はテーブルの結合方法を指定する条件に使用され、WHERE 句は結果セットに含める行を制限します。
JOIN 句 - MySQL 8.0 リファレンスマニュアル
この表現を FROM 句での結合で行う場合は、以下のようなクエリになります。
SELECT * FROM tbl_a, tbl_b WHERE tabl_a.id = tbl_b.tabl_a_id -- 結合条件 AND tbl_b.score > 5 -- 結合後の絞り込み
結合条件と、結合後の絞り込みが同じ WHERE 句に混在することになります。シンプルなクエリなら良いかもしれませんが、結合数が多くなると可読性は一気に下がるはずです。
結合表現の一貫性
冒頭で述べた通り、FROM 句に複数テーブルを指定して結合する場合、クロス結合ないし内部結合が前提です。
外部結合のときだけ JOIN 句を用いるくらいなら、内部結合もクロス結合も JOIN を使っておけば、テーブル結合の表現は全て JOIN 句で統一されるため、メンテナンスもしやすいはずです。
SQL ステートメントは、意図の分かる作文でありたい。
どちらを使うにせよ、業務で SQL 文を作成するのであれば、欲しい結果を得る為だけでなく、意図が明確に伝わるようにクエリを組み立てていく意識は持ちたいものです。
いつかそのクエリをメンテナンスするであろう、チームの誰か、そして自分のために。
SQL 文は、パフォーマンスを大切にしながらも、生み出す自身の意図が簡単かつ適切に相手に伝わる作文でありたいですね。
参考:
現在 back check 開発チームでは一緒に働く仲間を募集中です。 herp.careers