この記事は個人ブログと同じ内容です
データ分析基盤を構築する上で欠かせないのが ETL ツールです。外部データソースの取り込みを一元管理し、分析基盤のデータを最新に保ちます。
今回は、TROCCO と BigQuery を使って分析基盤を構築し、データ処理の流れを体験してみましょう。
対象
本記事は、TROCCO を使ってみたい。分析基盤を構築してみたい人が対象です。
TROCCO と GCP を利用します。個人利用のアカウントを使い、ハンズオン形式で進めていけます。
基本的には無料の範囲で実施しますが、扱うデータによって GCP 側で課金が発生する場合があります。無料範囲で実施したい場合は、本記事で提供するデータを使用してください。
(本記事で作成、有効化していく各リソースは、ハンズオン終了後、不要になったら自身の環境から削除、ないし無効化してください。)
TROCCO
TROCCO は、外部データソースの取り込みからデータマートの生成までをカバーする ETL ツールです。
TROCCO®は、ETL/データ転送・データマート生成・ジョブ管理・データガバナンスなどのデータエンジニアリング領域をカバーした、分析基盤構築・運用の支援SaaSです。
あらゆるデータの連携・整備・運用を自動化し、スピーディーにデータ活用環境を整備。インサイトを得やすい状況に導きます。
https://trocco.io/lp
DB やログなどのデータを分析基盤に取り込んだり、分析基盤のデータからデータマートを作成したりを一括管理できます。さらにこれらをワークフローとして定義することで、分析基盤上のデータを最新に保つなどの仕組みも備えています。
TROCCO フリープランアカウント作成
TROCCO では、無料で使えるフリープランがあります。
https://trocco.io/lp/plan.html

フリープランを使用するには、あらかじめ申し込みが必要です。アカウント発行には 1 営業日程度かかるので、前もって申し込んでおきます。
アカウントが作成されたら、ログイン画面からログインします。
https://trocco.io/users/sign_in
TROCCO と BigQuery で構築する分析基盤
今回は、BigQuery を分析基盤として、TROCCO を ETL ツールとして使い、Google スプレッドシートのデータを取り込み、そこからさらにデータマートを作成するまでを行ってみましょう。
まずは、GCP と TROCCO で事前準備の設定を行っていきます。その後で、外部データの取り込みやデータマート作成を行います。
GCP 設定
まずは GCP の設定を行います。GCP でプロジェクトが作成されている前提で進めますのでまだ作成していない場合はプロジェクトを作成してください。
https://cloud.google.com/resource-manager/docs/creating-managing-projects?hl=ja
TROCCO 接続用のサービスアカウント作成
TROCCO から BigQuery に接続できるように、サービスアカウントを作成します。
「IAMと管理」より、「サービスアカウント」を押下し、サービスアカウントを作成します。
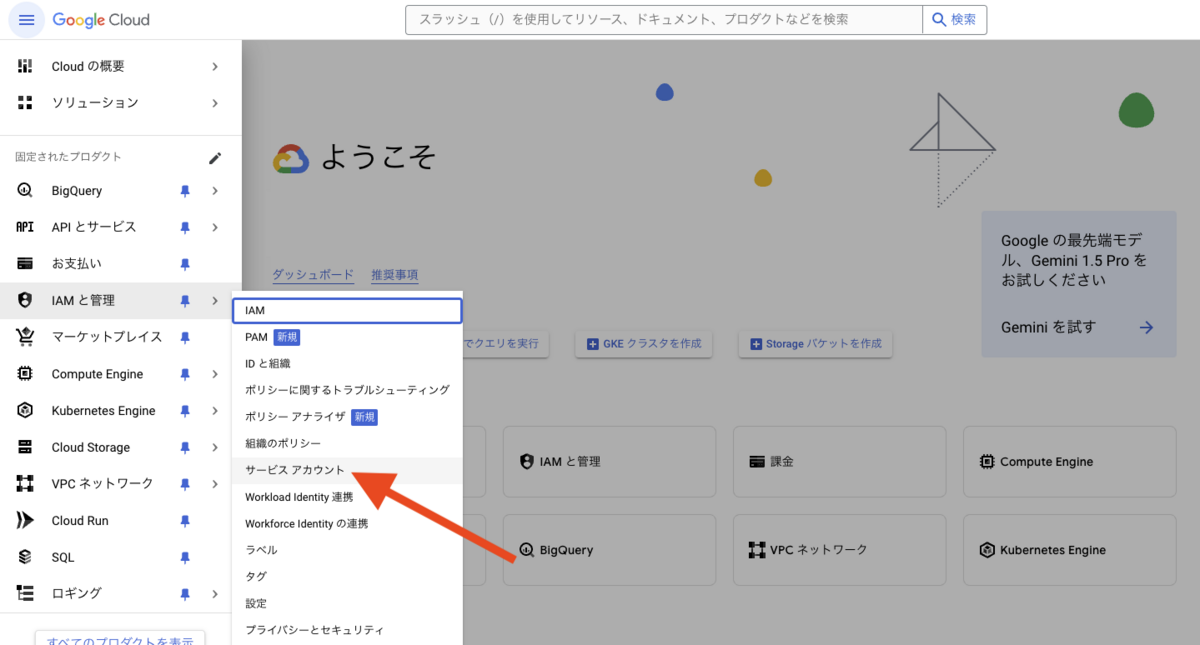
サービスアカウント画面にアクセスしたら、「サービスアカウントを作成」を押下します。
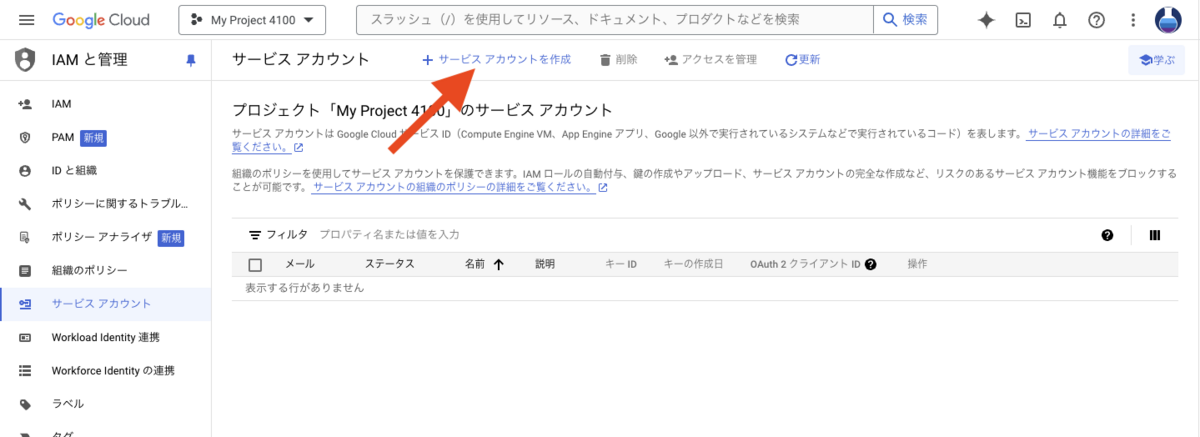
「サービス アカウントの詳細」では、サービスアカウントの名前を入力します。入力したら、「作成して続行」ボタンを押下します。
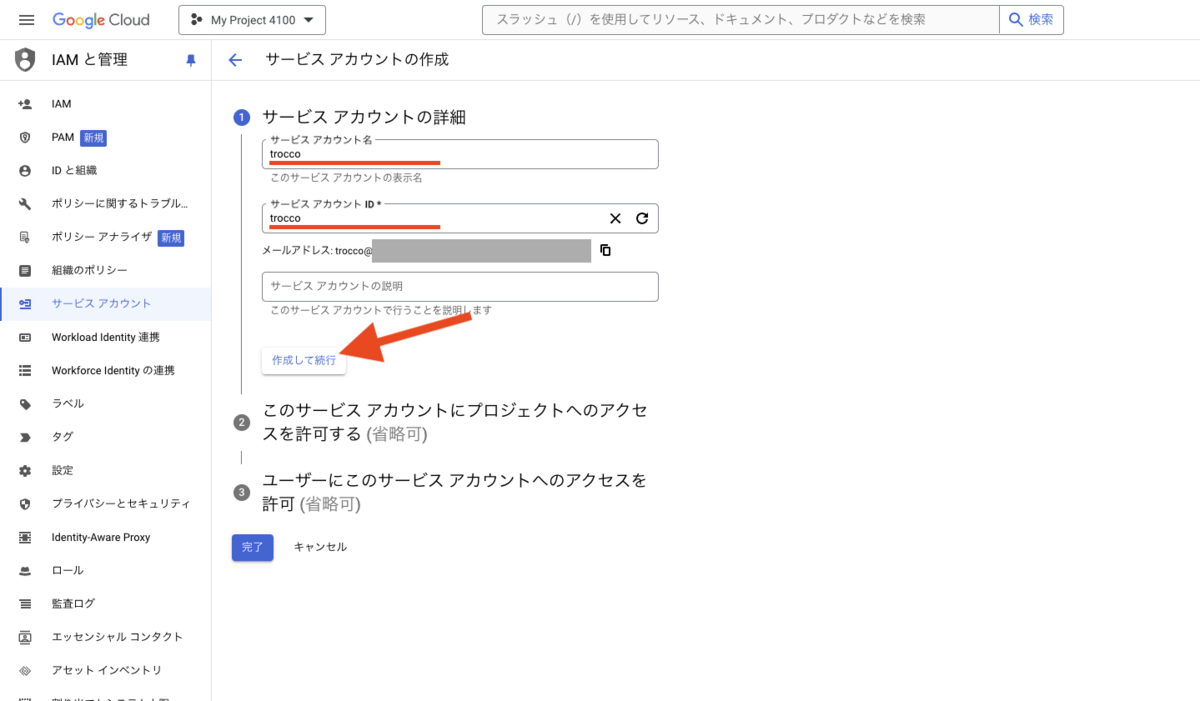
次に、このサービスアカウントに権限を付与していきます。「BigQuery ジョブユーザー」と「BigQuery データオーナー」を付与します。
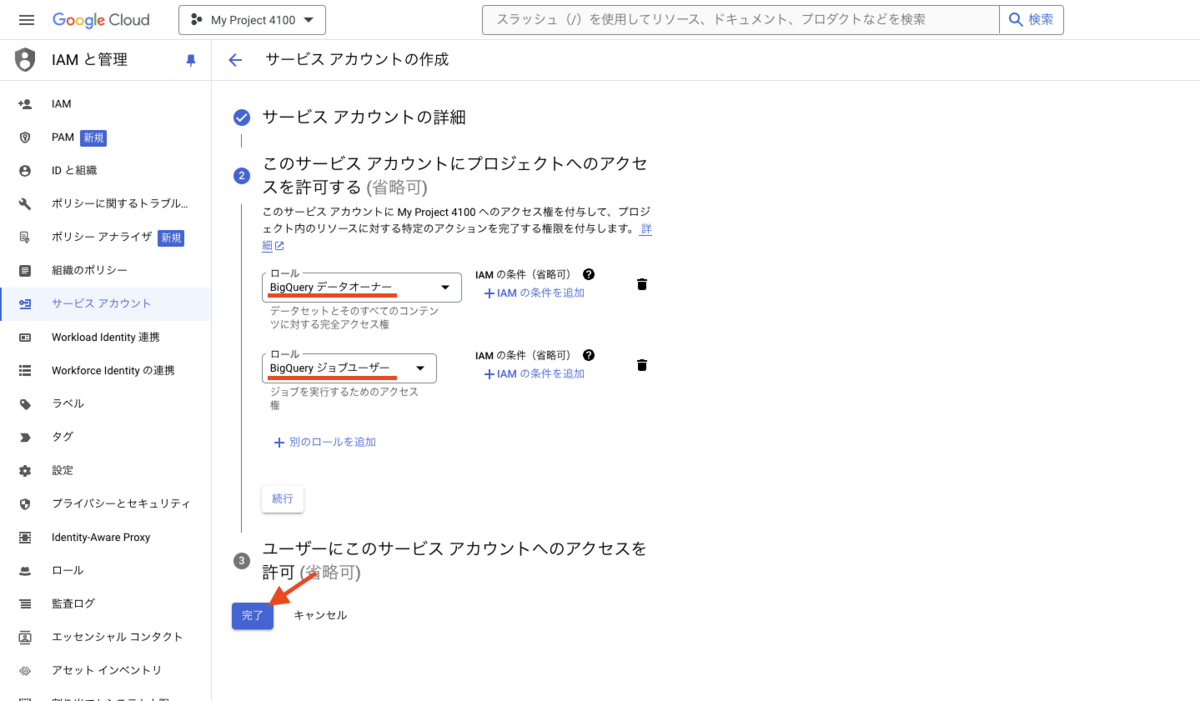
完了ボタンを押下し、サービスアカウントの作成は完了です。
なお、サービスアカウントへのロール付与について、業務で使用する場合は管理者に相談のもと、適切な権限を付与するようにしてください。
https://cloud.google.com/bigquery/docs/access-control?hl=ja
サービスアカウントが作成されました。続いて、キーを発行します。
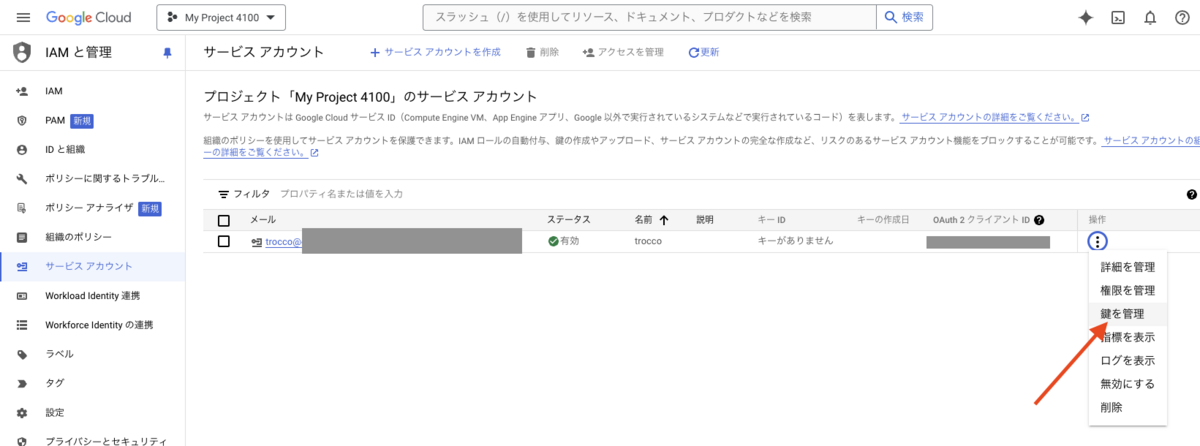
「鍵を追加」より、「新しい鍵を作成」を押下します。
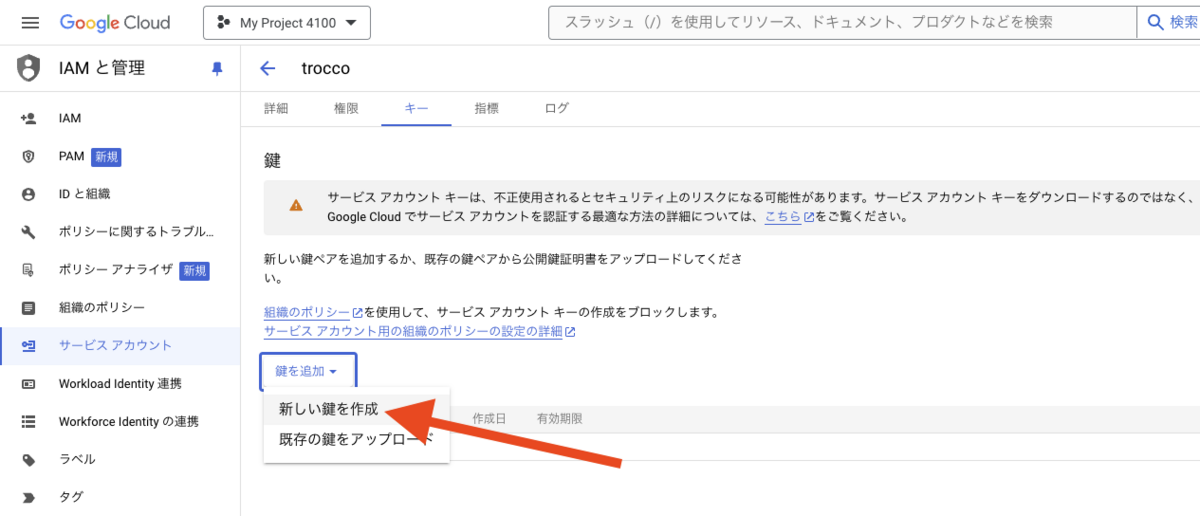
キーのタイプは「JSON」を選択し、作成ボタンを押下します。
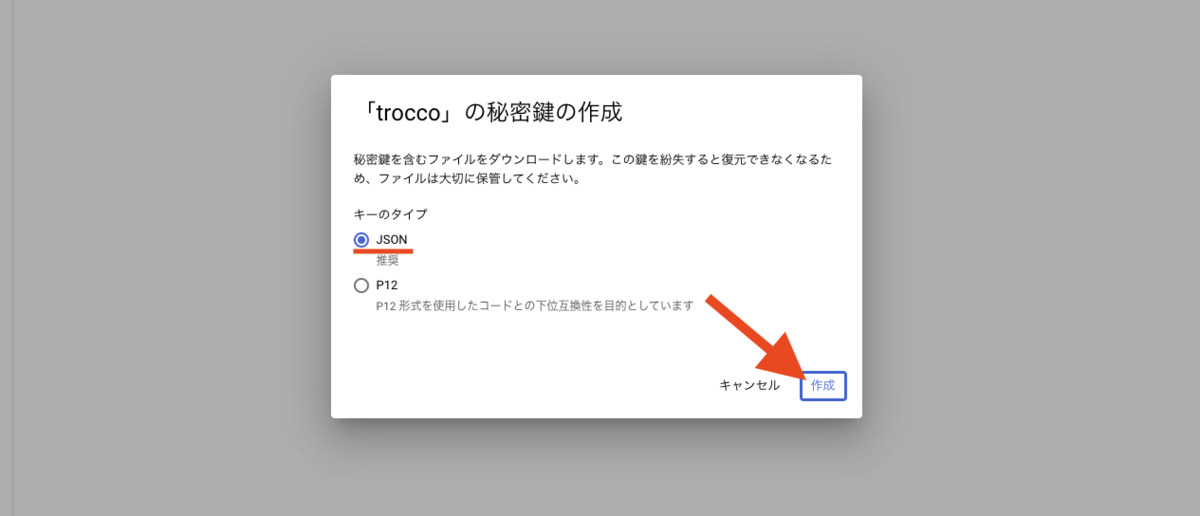
これでキーが生成されました。生成されキーは JSON ファイルで自動的にダウンロードされます。JSON ファイルを開いてみると以下が収録されています。キーは後工程で使用します。
{ "type": "xxx", "project_id": "xxx", "private_key_id": "xxx", "private_key": "xxx", "client_email": "xxx", "client_id": "xxx", "auth_uri": "xxx", "token_uri": "xxx", "auth_provider_x509_cert_url": "xxx", "client_x509_cert_url": "xxx", "universe_domain": "xxx" }
Google Sheets API の有効化
今回は、外部データソースとして Google Sheets を使います。TROCCO はスプレッドシートへのアクセスに Sheets API と Drive API を用いますので、これを有効化しておきます。
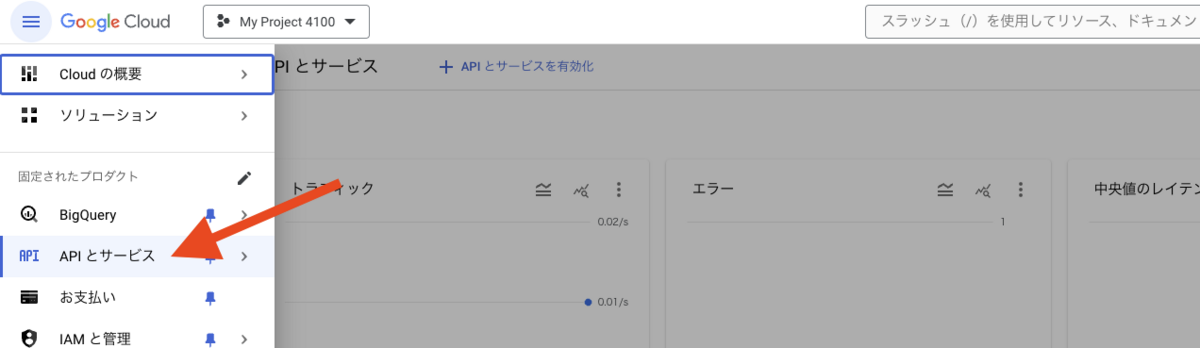
GCP のコンソール画面から、「APIとサービス」にアクセスし、検索窓に「Google Sheets API」と入力すると出てくる「Google Sheets API」を押下します。
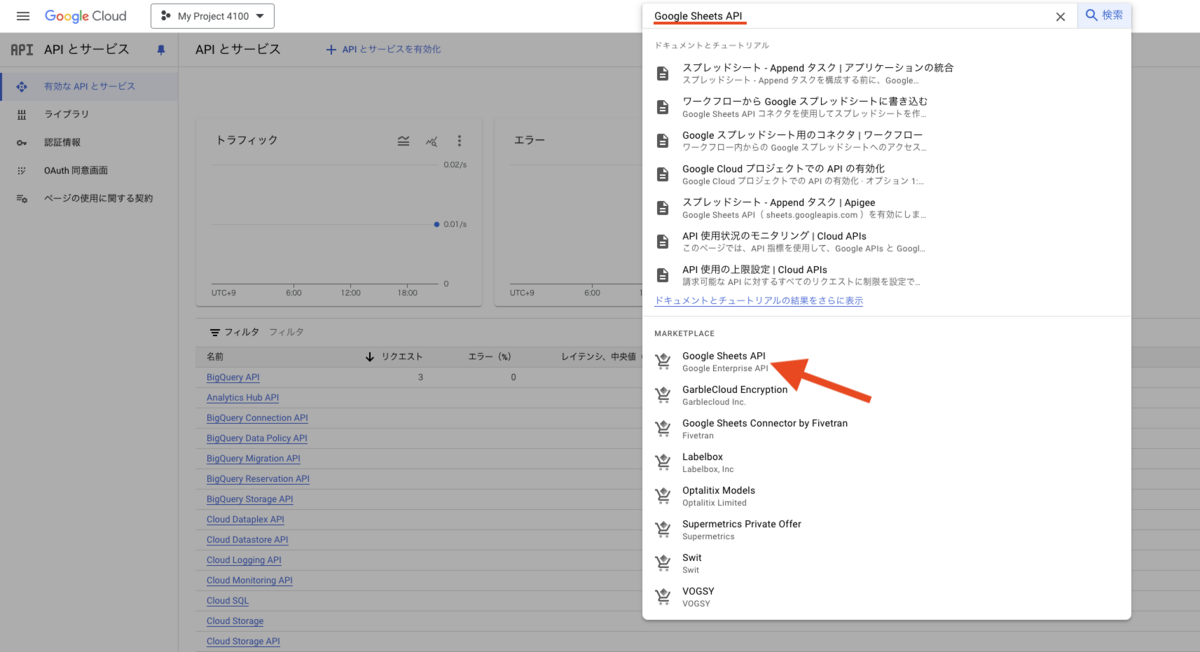
Google Sheets API を有効にするボタン押下します。
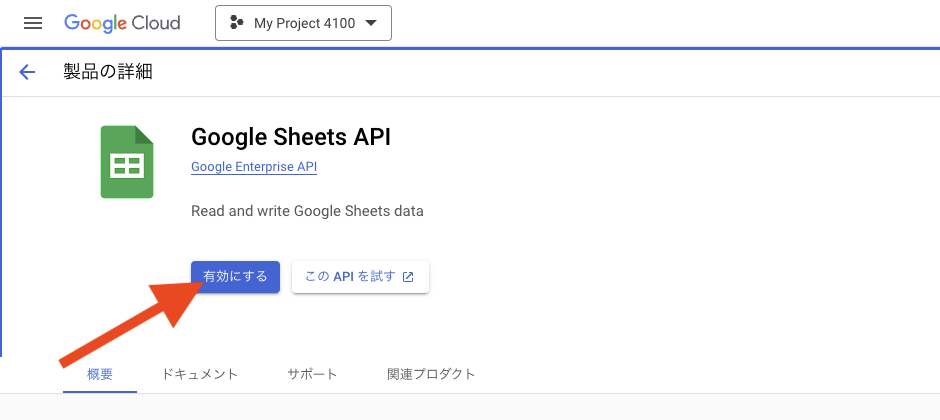
これで Google Sheets API の有効化は完了です。
Google Drive API の有効化
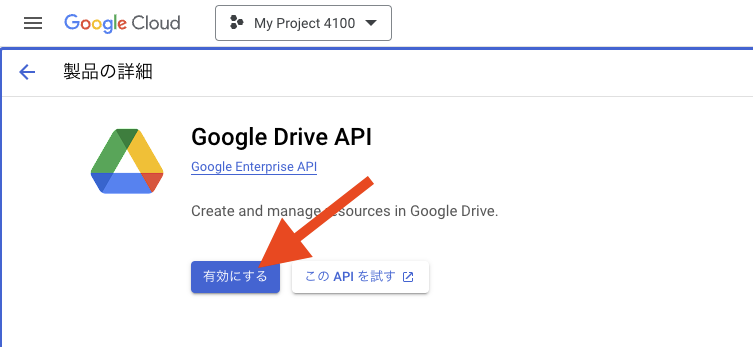
同じく、Drive API も有効化します。検索窓に「Google Drive API」と入力すると出てくる「Google Drive API」を押下します。
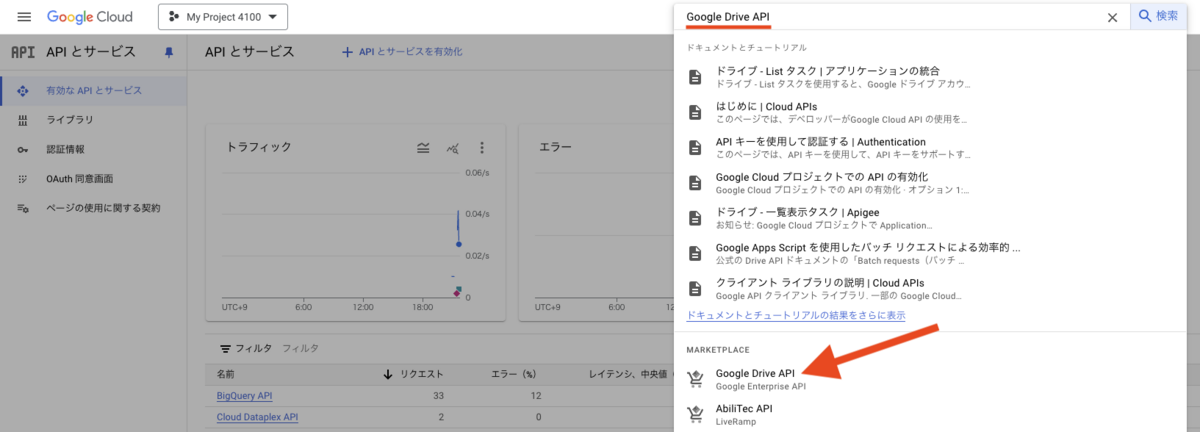
「有効にする」ボタンを押下します。
TROCCO 設定
続いて、TROCCO 側の設定を行っていきます。
接続情報の登録
TROCCO がスプレッドシートに接続するための接続情報と、BigQuery に接続するための接続情報 2 つを登録します。
左メニュー「接続一覧」を押下し接続情報一覧へアクセスしたら、画面右上にある「新規作成」ボタンを押下します。
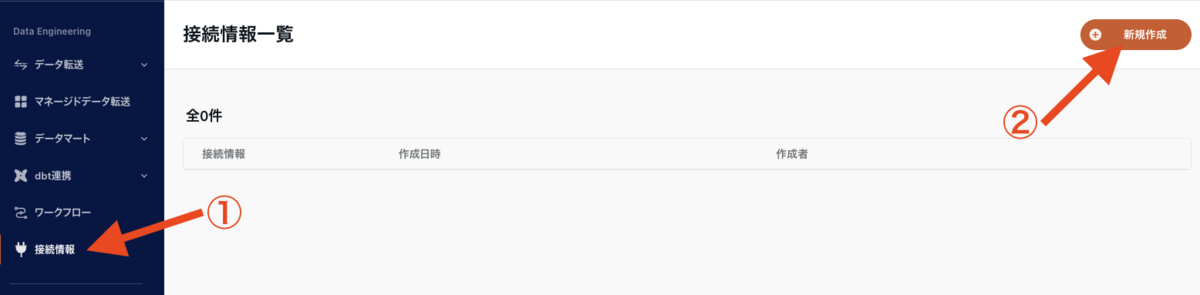
Google Spreadsheets 接続情報
「ファイル・ストレージサービス」タブを押下すると、Google Spreadsheets が表示されますので、これを押下します。
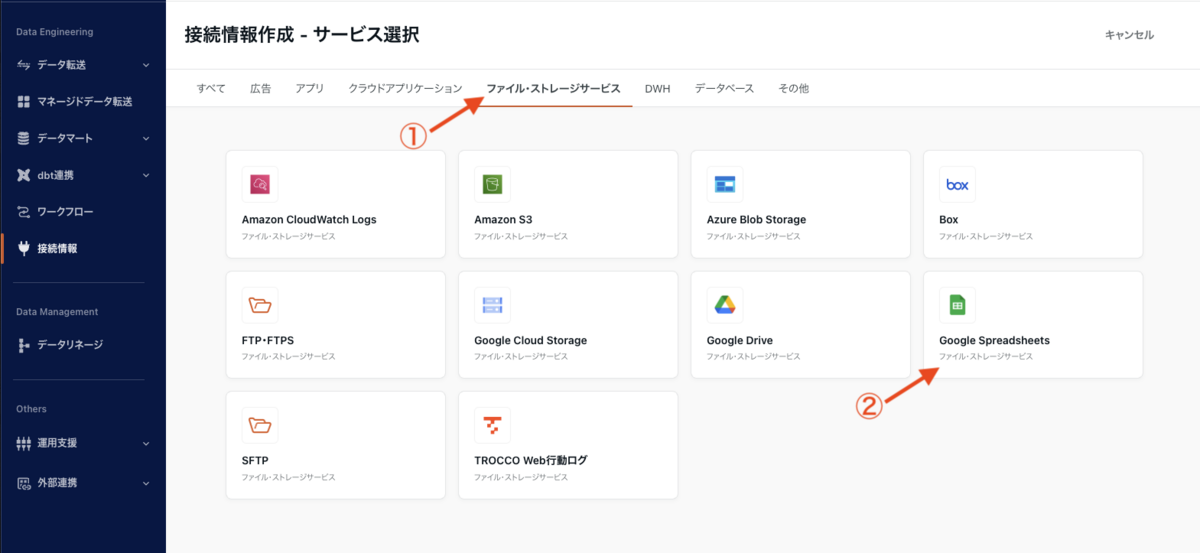
「サービスアカウントで作成」ボタンを押下します。

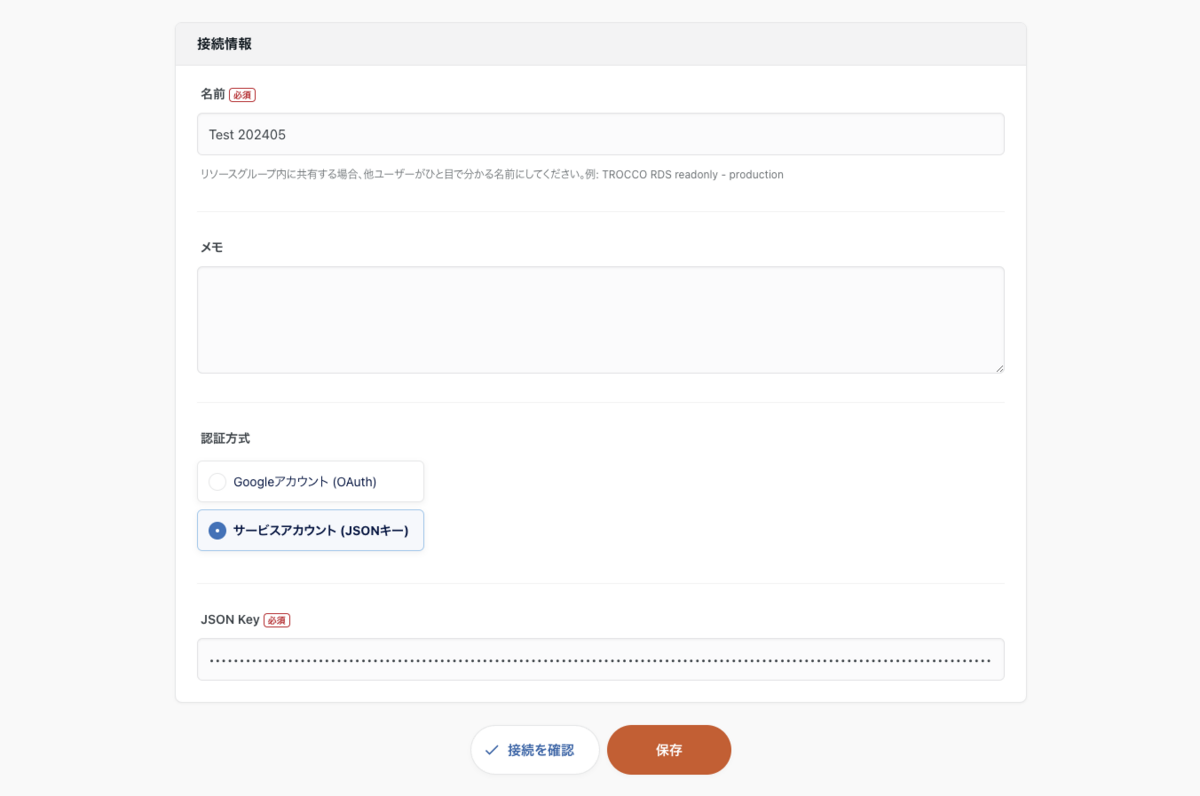
接続情報の作成画面で、必要な情報を入力します。認証方式は JSON を選択し、JSON Key には、GCP で TROCCO 接続用のサービスアカウントを作成した際にダウンロードした JSON ファイルの中身を全てコピーし、ここにペーストします。
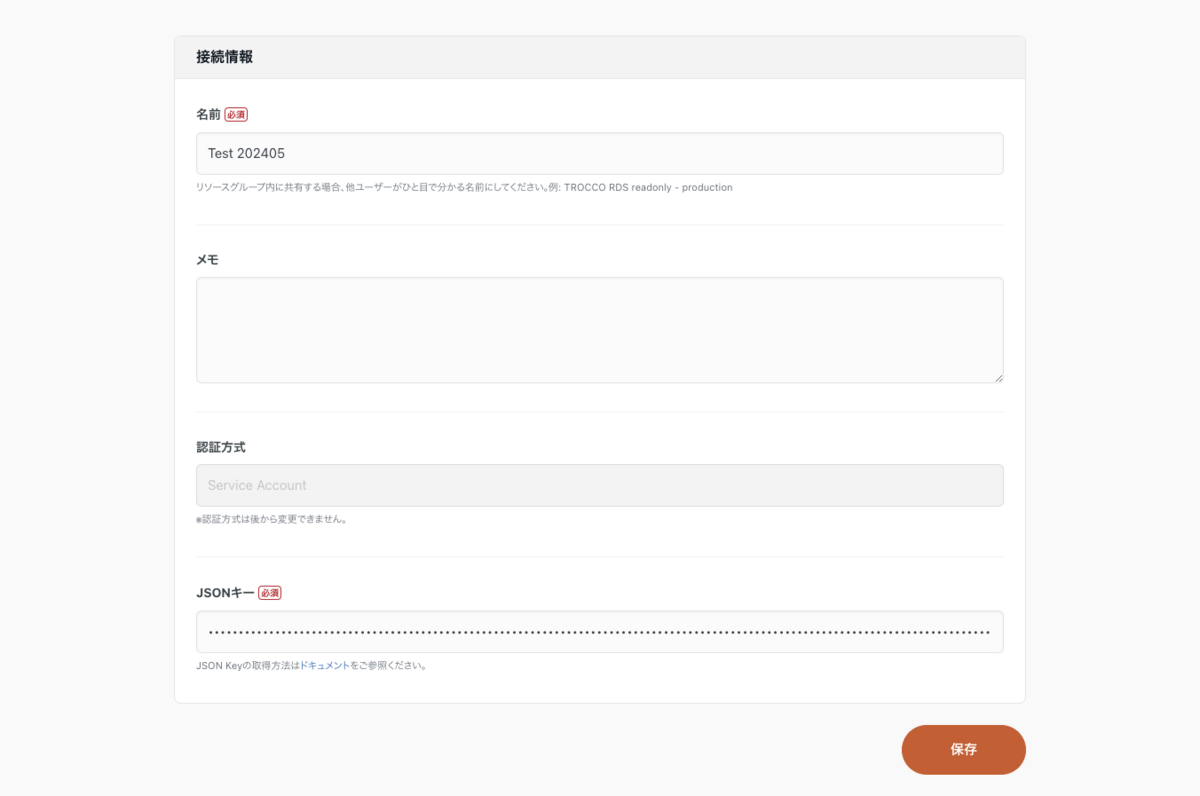
保存ボタンを押下し、接続情報を登録します。
BigQuery 接続情報
Google Spreadsheets 接続情報の登録と同じ要領で、BigQuery への接続情報も登録します。
DWH を押下すると、BigQuery が表示されますので、これを押下します。
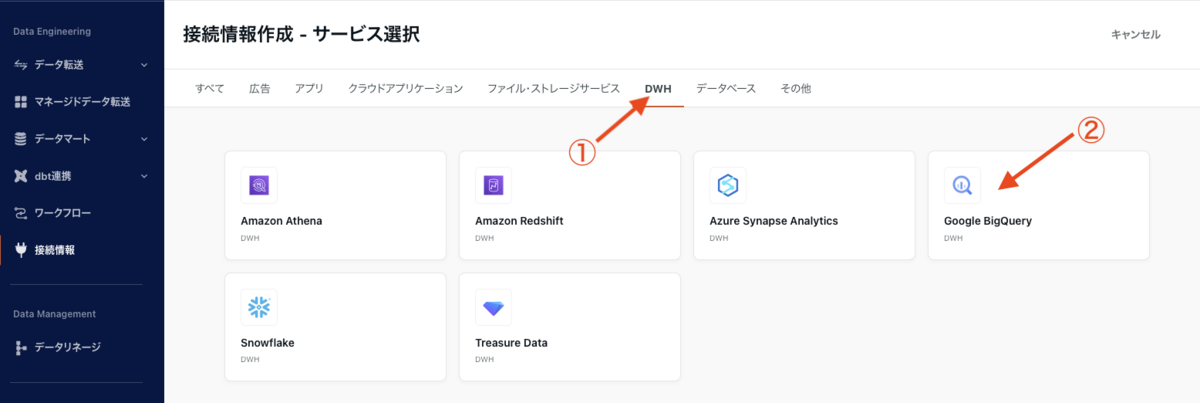
こちらも先ほど同じく、認証方式は JSON を選択し、JSON Key には、GCP で TROCCO 接続用のサービスアカウントを作成した際にダウンロードした JSON ファイルの中身を全てコピーし、ここにペーストします。
入力できたら、「接続を確認」ボタンを押下してみましょう。接続結果に正しく接続が行えたか表示されます。
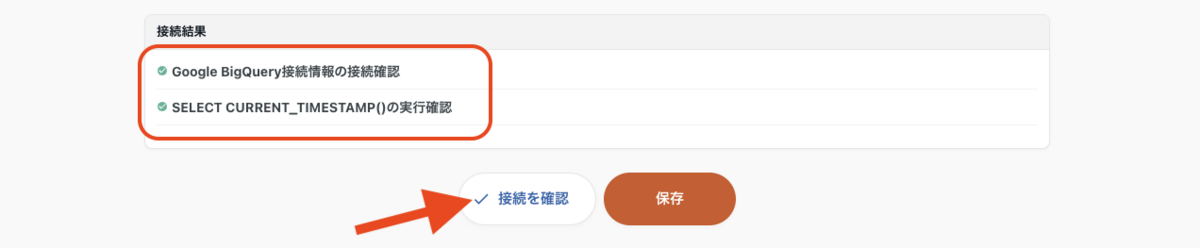
接続確認ができたら、保存ボタンを押下し、接続情報を登録します。
以上で接続情報の登録は完了です。
これで一通りの事前準備が完了しました。
サンプルデータ
今回は、外部データソースとして Google Spreadsheets を用いますが、そこに収録するデータとして、以下を利用します。
(これらのデータに関してや、BigQuery に関しては BigQuery やさしいはじめの一歩〜実際に触って理解するデータ操作ワークショップ〜 を参照してください)
自分のアカウント上にスプレッドシートを作成し、上記のデータをコピーしてください。そして、作成したスプレッドシートをサービスアカウントに共有します。
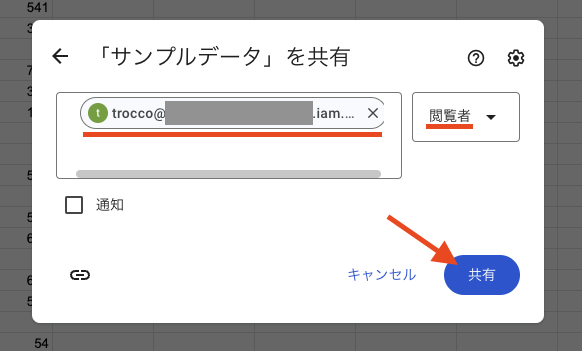
共有先ですが、ダウンロードしたサービスアカウントの JSON ファイルに client_email の記載がありますので、これを指定します。権限は閲覧者で問題ありません。
データ転送設定
それでは実際に分析基盤にデータの取り込みを行ってみましょう。TROCCO の「データ転送」画面から「新規転送設定作成」ボタンを押下します。
転送元は Google Spreadsheets, 転送先は BigQuery を選択して「この内容で作成」ボタンを押下します。
遷移後の転送設定の新規作成画面では、以下を入力していきます。
- 概要設定
- 名前: 転送設定に任意の名前をつけます。ここでは「sample_ice_cream__ice_cream_sales」としています。
- 転送元 Google Spreadsheetsの設定
- Google Spreadsheets接続情報: 作成した接続を指定します。
- シートのURL: 自分のアカウント上に作成したサンプルデータのスプレッドシート URL を入力します。
- シート名: 取り込みたいシート名を入力します。
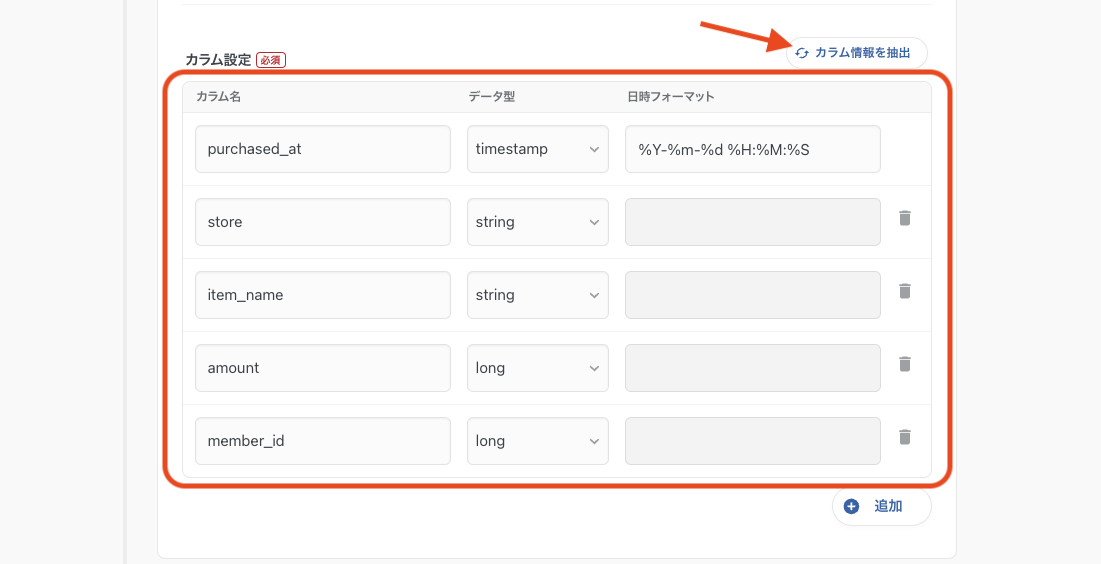
- カラム設定: 「カラム情報を抽出」ボタンを押下します。スプレッドシートに接続できれば、自動でカラム情報を取得してくれます。
- 転送先 Google BigQueryの設定
- Google BigQuery接続情報: 作成した接続を指定します。
- データセット: sample_ice_cream と入力します。
- テーブル: ice_cream_sales と入力します。
- データセットのロケーション: お住まいの地域に近いロケーションを指定します。東京が最寄りなら asia-northeast-1(東京)を指定します。
- データセットの自動生成オプション: 「dataset を自動で生成する」を選択します。
- 転送モード: 全件洗い替え(REPLACE)を選択します。
- 接続確認: 「接続を確認」ボタンを押下して、接続が正常に行えるか確認しましょう。エラーが出なければ正常に接続できています。

全て入力できたら、画面最下部にある「次の STEP へ」 ボタンを押下します。
次の「データプレビュー・詳細設定」では、実際に BigQuery に転送されるデータのプレビューやカラム定義、フィルターや文字列変換、マスキング設定など細かい設定が行えます。
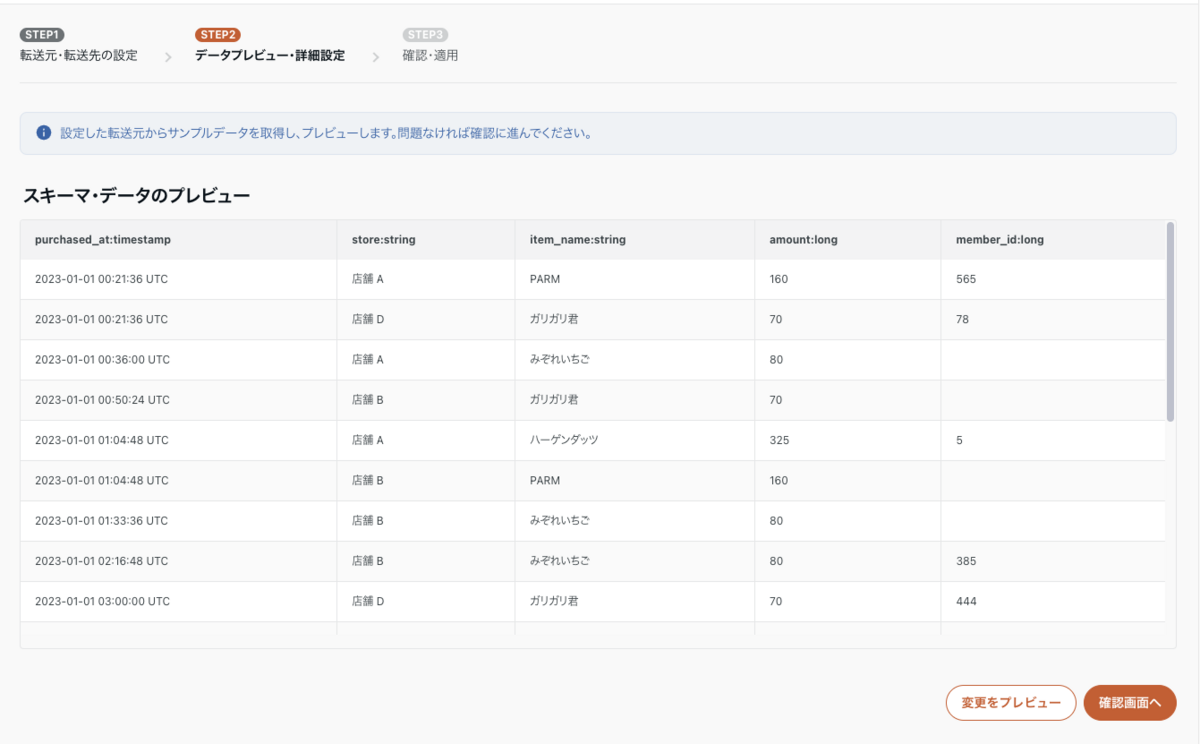
今回は特に変換処理は設定しませんので、プレビューが正常に表示されたら、「確認画面へ」ボタンを押下し先に進みます。
遷移先の「内容の確認」画面は、これまで設定した情報の確認です。問題なければ「保存して適用」ボタンを押下すると、データ転送設定が登録されます。
データ転送実行
では、登録した転送設定を使用して、スプレッドシートのデータを BigQuery に転送してみましょう。作成したデータ転送画面の右上にある「実行」ボタンを押下します。
「新規転送ジョブの実行」画面に遷移するので、そのまま「実行」ボタンを押下すれば、データ転送が開始されます。
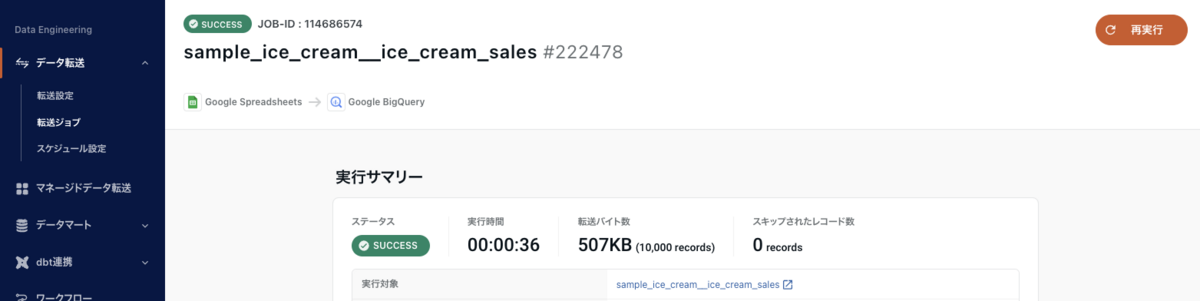
ステータスが SUCCESS になれば、転送は成功です。
実際に BigQuery を確認してみましょう。データセット「sample_ice_cream」に、テーブル「ice_cream_sales」が作成されていることが確認できます。
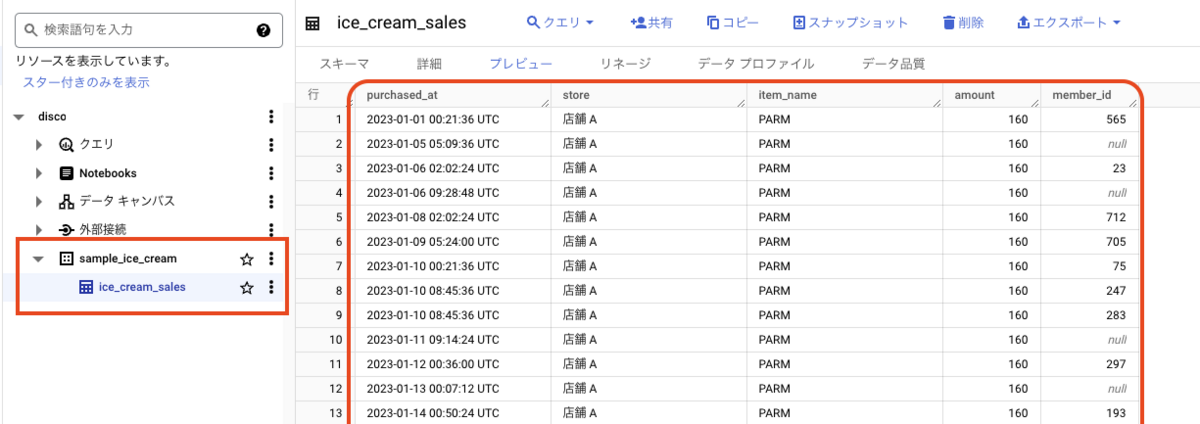
おつかれさまでした。これで、外部データソースからのデータの取り込みができました。
次に進む前に
同じ要領で、「ポイントメンバー会員」データについても、データ転送設定を作成し、データ取り込みまで行ってください。この後のデータマート作成で、これら 2 つのテーブルを使用します。
- 転送設定名: sample_ice_cream__members
- データセット: sample_ice_cream
- テーブル: members
データマート作成
前章で、外部のデータソースを分析基盤に取り込むことを行っていきました。
ここでは、分析基盤に既にあるテーブルから、さらに新しいテーブルを作成するための設定を行います。
現在、sample_ice_cream データセットには 2 つのテーブル「ice_cream_sales」と「sample_ice_cream」があります。この 2 つのテーブル使用して、「各商品ごとの男女購入比率」を算出した新しいテーブルを作成します。
テーブルのレコードとしては、以下になる想定です。
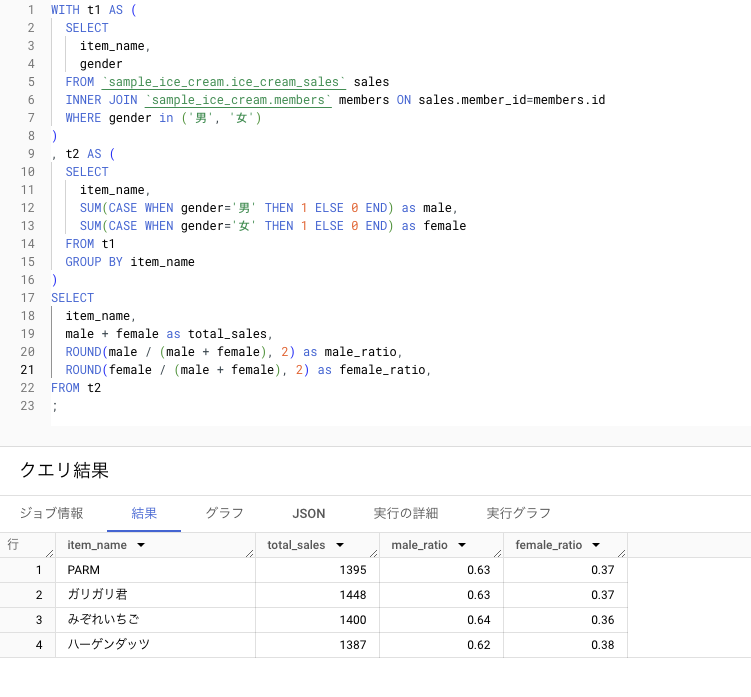
WITH t1 AS ( SELECT item_name, gender FROM `sample_ice_cream.ice_cream_sales` sales INNER JOIN `sample_ice_cream.members` members ON sales.member_id=members.id WHERE gender in ('男', '女') ) , t2 AS ( SELECT item_name, SUM(CASE WHEN gender='男' THEN 1 ELSE 0 END) as male, SUM(CASE WHEN gender='女' THEN 1 ELSE 0 END) as female FROM t1 GROUP BY item_name ) SELECT item_name, male + female as total_sales, ROUND(male / (male + female), 2) as male_ratio, ROUND(female / (male + female), 2) as female_ratio, FROM t2 ;
データマート定義
それでは TROCCO で設定を行っていきます。
「データマート定義」より、「新規データマート定義作成」ボタンを押下します。
データマート定義の新規作成画面に遷移するので、BigQuery を押下します。

データマート定義の新規作成フォームが表示されたら、以下を入力していきます。
- 概要設定
- データマート定義名: データマート定義に任意の名前をつけます。ここでは「sample_ice_cream__item_gender_sales_ratio」としています。
- 基本設定
- Google BigQuery接続情報: 作成した接続を指定します。
- クエリ設定
- クエリ実行モード:「データ転送モード」を選択します。
- クエリ: 前項のクエリをペーストします。
- フォームの右上に「プレビュー実行」ボタンがあるので押下します。クエリが正常に実行できれば、プレビュー結果が表示されます。
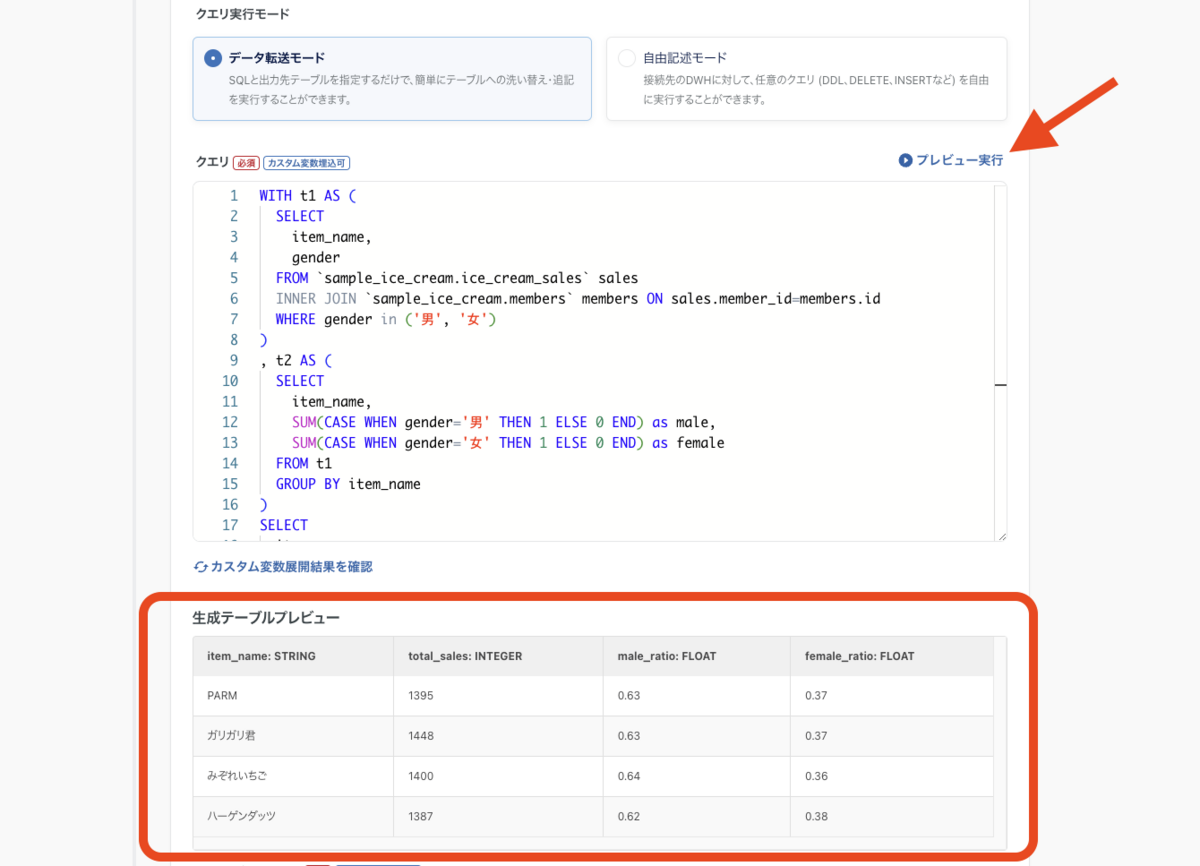
- 出力先データセット: sample_ice_cream と入力します。
- 出力先テーブル: item_gender_sales_ratio と入力します。
- 書き込みモード: 「全件洗い替え」を選択します。
入力が完了したら、確認画面へ進み、適用ボタンを押下します。これでデータマート定義が作成できました。
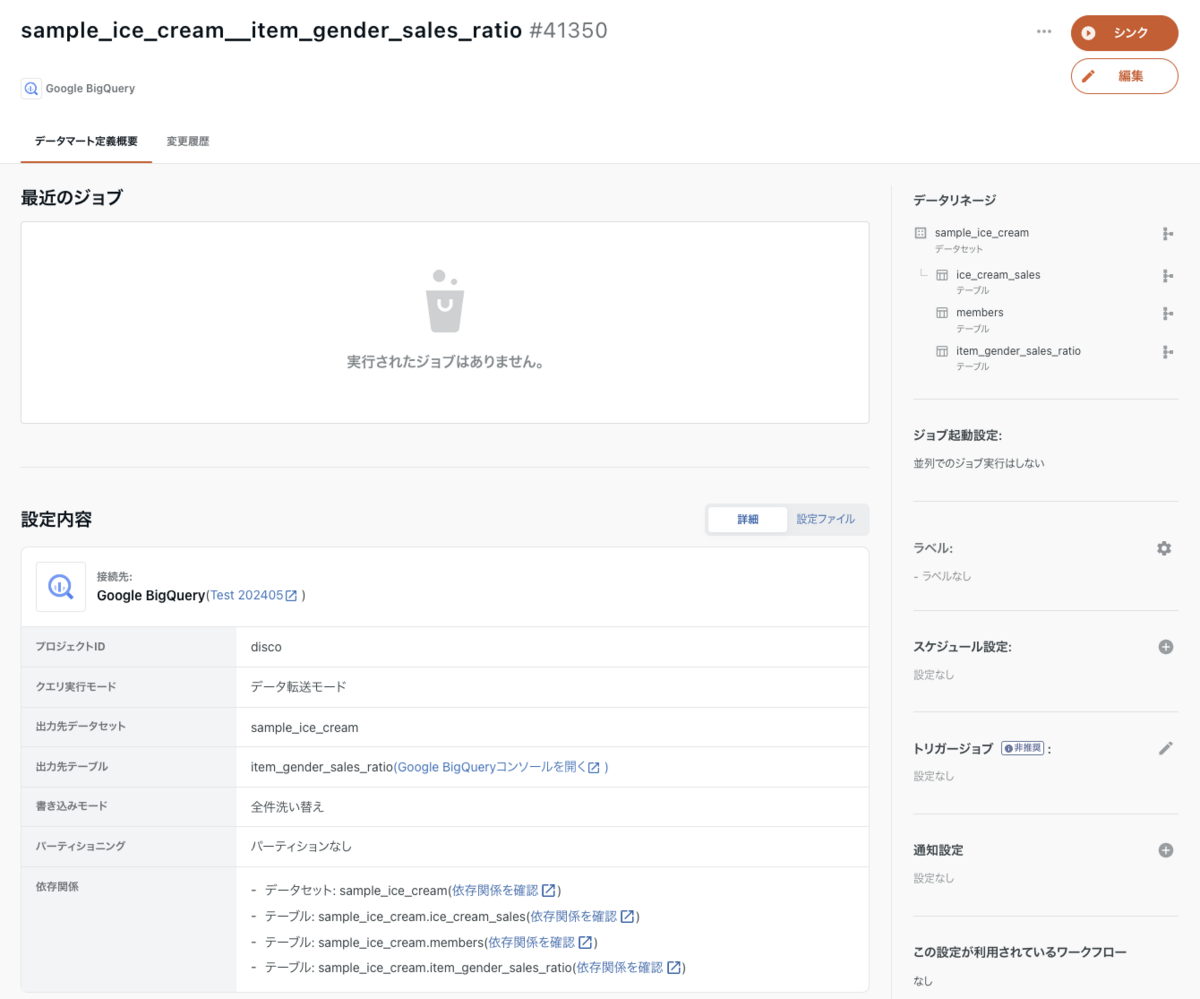
データマート作成実行
では、登録したデータマート定義を使用して、BigQuery にテーブルを作成してみましょう。右上にある「シンク」ボタンを押下します。
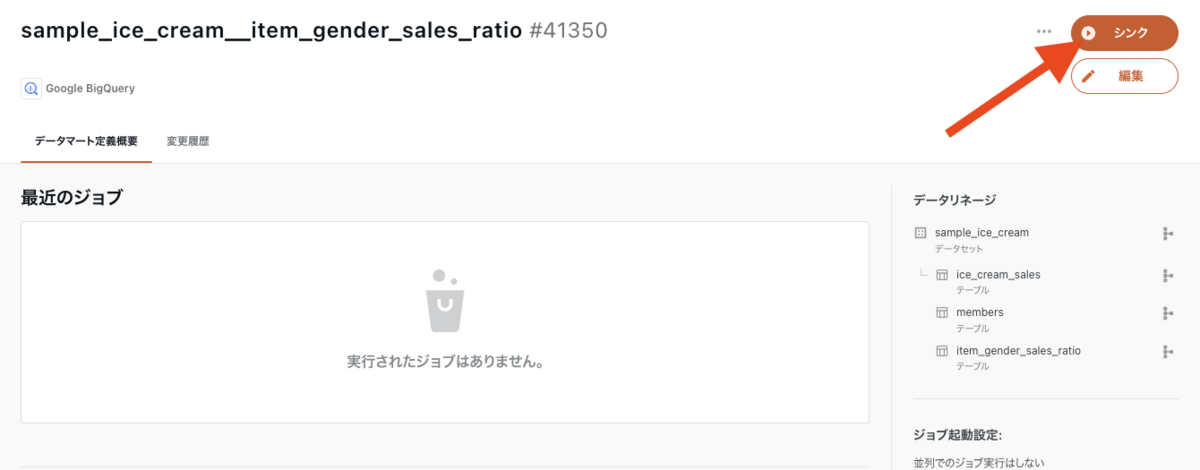
「新規シンクジョブの実行」画面に遷移するので、そのまま「シンクジョブを実行」ボタンを押下すれば、データマート作成が開始されます。
ステータスが SUCCESS になれば、作成は成功です。
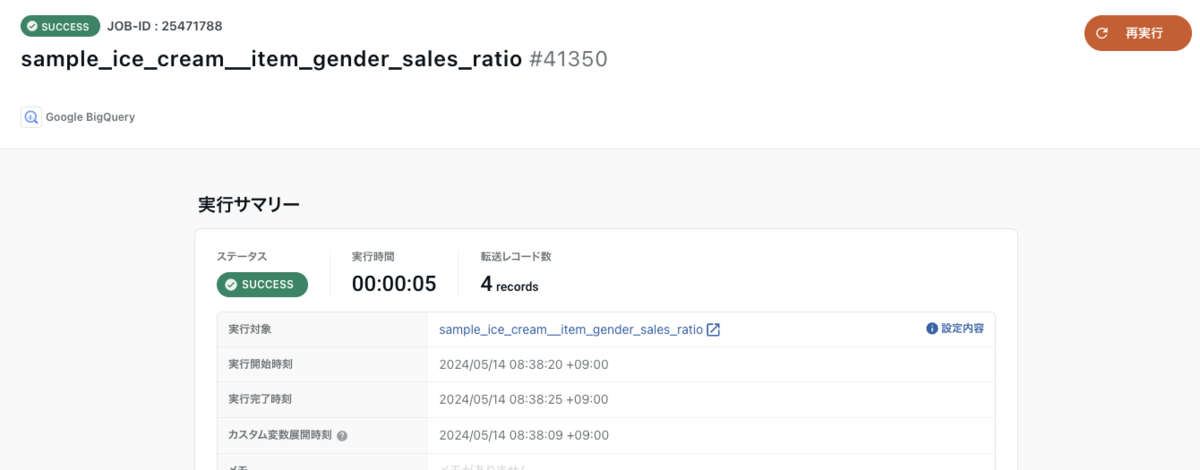
BigQuery を確認してみましょう。データセット「sample_ice_cream」に、新たなテーブル「item_gender_sales_ratio」が作成されていることが確認できます。

おつかれさまでした。これで、データマートの作成が完了しました。
ワークフロー
ここまで、「外部データソースの取り込み」そして「データマートの作成」を行ってきました。
TROCCO のような ETL ツールの役割は、これらの一元管理はもちろんのこと、定期的にデータの最新化を行うことも重要な役割の一つです。
つまり、外部のデータソースから定期的に新しいデータを取得し、それを使ってデータマートのデータも最新化していきます。
これらを行うために、ワークフローを定義して、一連のデータの処理の流れを自動化します。
具体的には、TROCCO でこれまで作成してきた以下の 3 つのデータ処理を一連のフローとして定義し、定期的にこれらを自動で実行できるようにします。
- スプレッドシートを読み込み BigQuery に ice_cream_sales テーブルを作成する
- スプレッドシートを読み込み BigQuery に members テーブルを作成する
- BigQuery の ice_cream_sales テーブル、members テーブルから、item_gender_sales_ratio テーブルを作成する
ワークフロー定義
ワークフロー定義 より、画面右上にある「新規ワークフロー作成」ボタンを押下します。
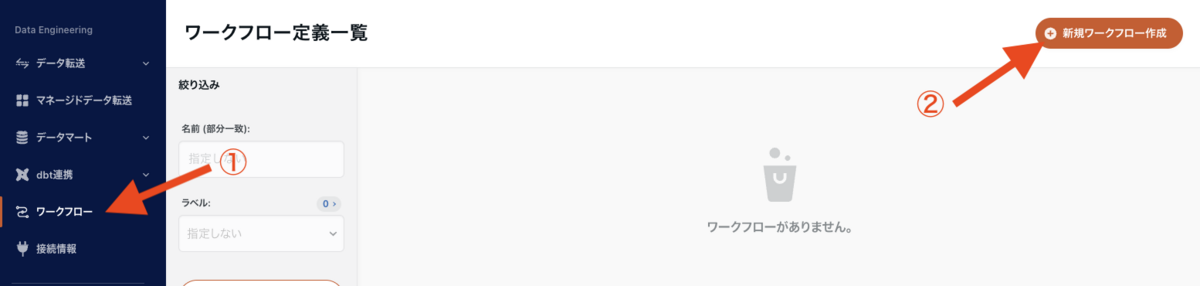
ワークフロー定義の新規作成画面に遷移したら、以下を入力していきます。
- 概要設定
- ワークフロー名: ワークフローに任意の名前をつけます。ここでは「ice_cream_sales_workflow」としています。
- ジョブ実行設定
- タスク同時実行上限数: 2
- タイムアウト設定: 有効, 3 分
- リトライ回数: 0
- ジョブの重複実行: 許可する
入力したら「保存」ボタンを押下します。
フロー編集
フロー編集画面に遷移したら、「TROCCO転送ジョブ」を押下します。

モーダルが表示されるので、「sample_ice_creamice_cream_sales」「sample_ice_creammembers」両方にチェックを入れ、「追加」ボタンを押下します。
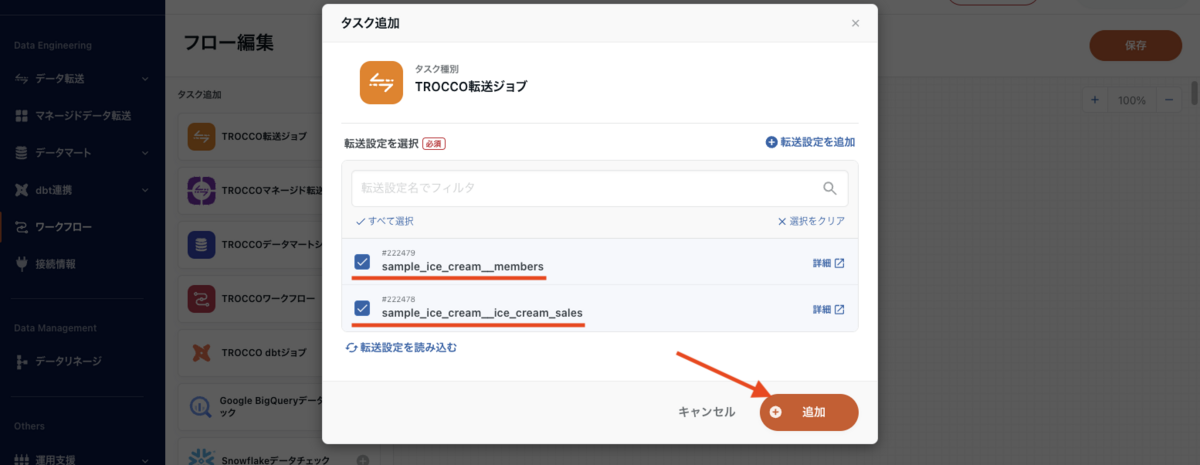
「sample_ice_creamice_cream_sales」と「sample_ice_creammembers」を、それぞれ「START」から矢印をドラッグして並列につなぎます。それぞれのオブジェクトに点(ポイント)があるので、そこからドラッグすると以下のように START と転送設定を矢印で繋げられます。
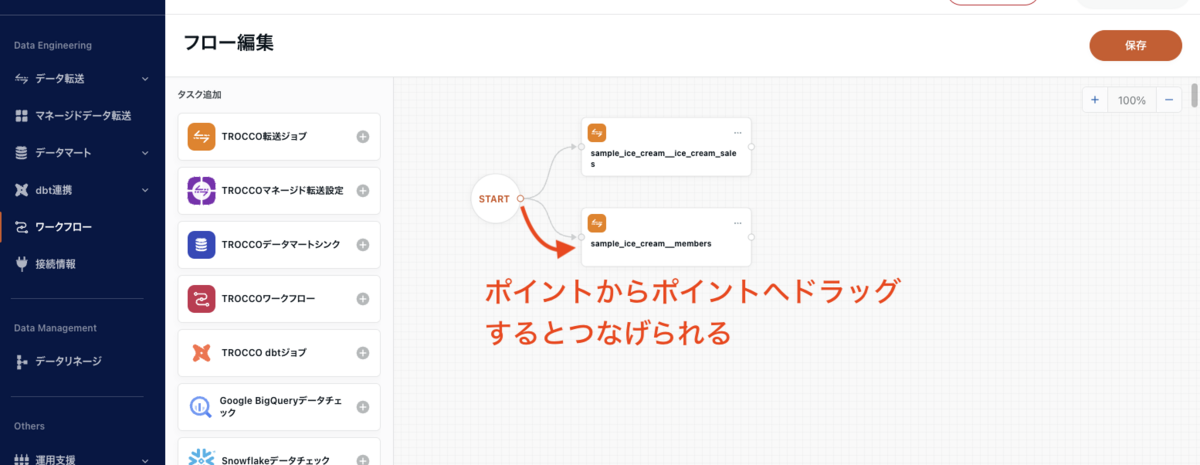
次に、「TROCCOデータマートシンク」を押下します。
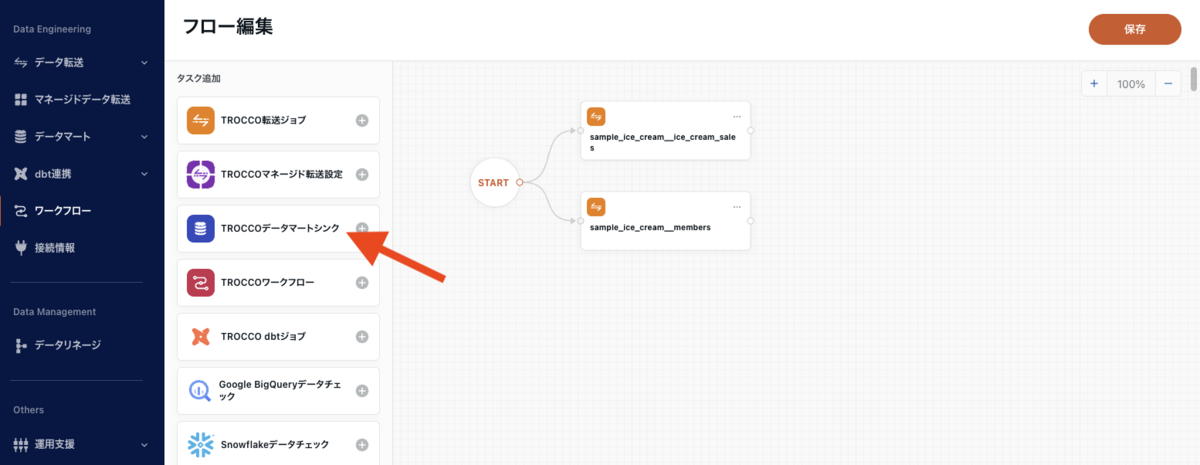
モーダルが表示されるので、「sample_ice_cream__item_gender_sales_ratio」にチェックを入れ、「追加」ボタンを押下します。
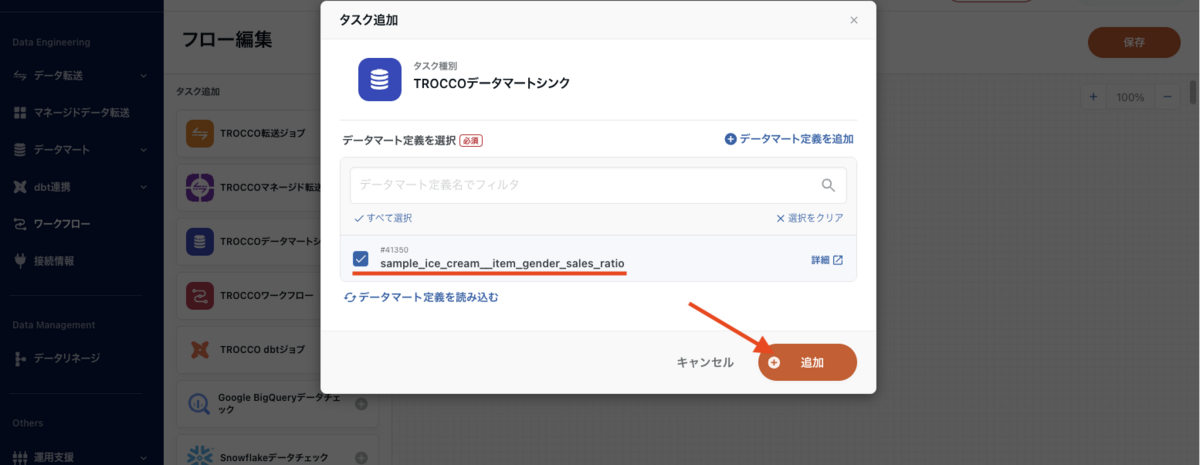
新しく追加された「sample_ice_creamitem_gender_sales_ratio」のオブジェクトを、それぞれ「sample_ice_creamice_cream_sales」「sample_ice_cream__members」から矢印でつなぎます。
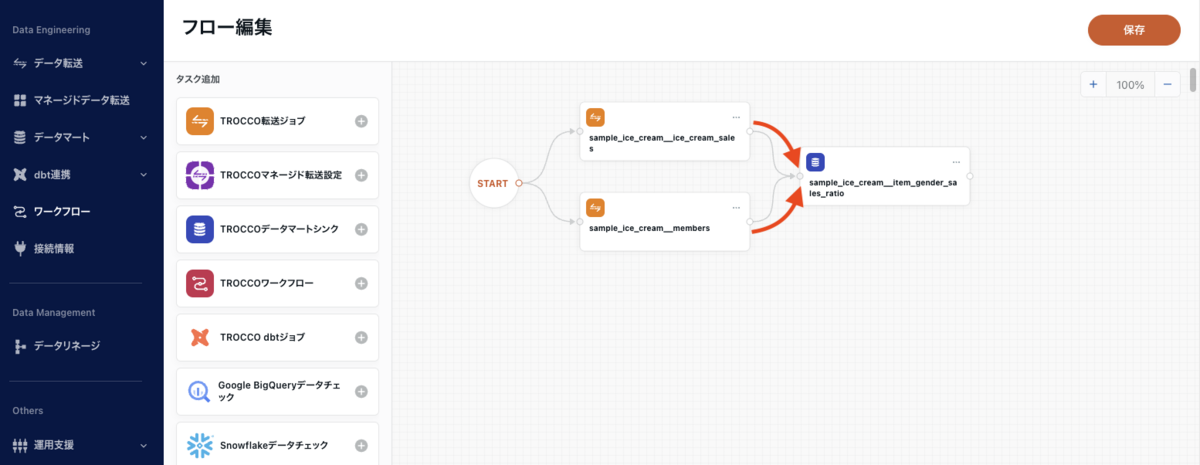
こうすることで、データ転送の 2 つが完了したら、データマート作成を行う。という依存関係も定義できます。元のデータが両方最新化されていなければ、データマートを作成してもデータが不十分ですから、こうして依存関係を定義することで、データの不整合を防ぐことができます。
ここまで設定できたら、画面右上の「保存」ボタンを押下してワークフロー定義を保存します。
ワークフロー実行
ワークフローを実行してみましょう。画面右上の「実行」ボタンからワークフローを実行できます。
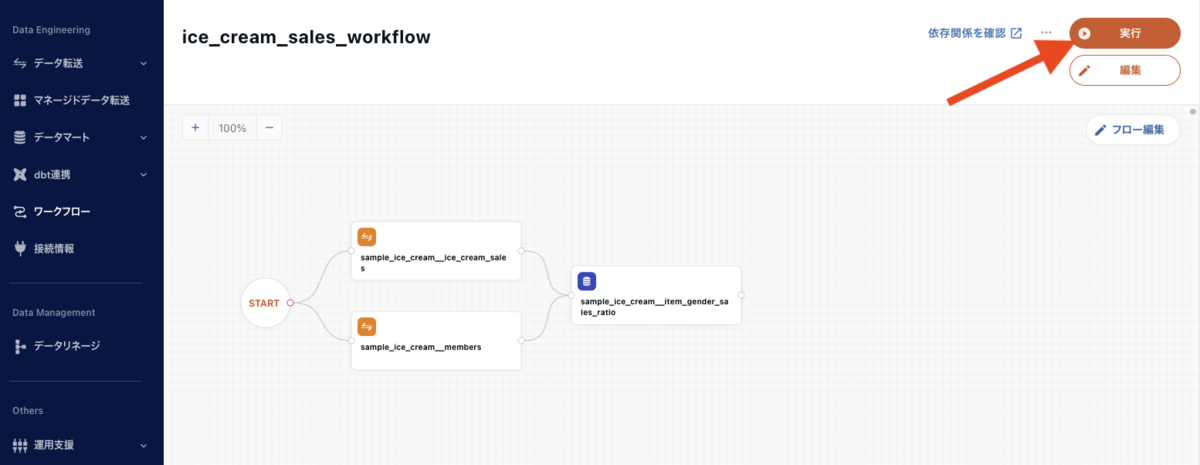
ステータスが SUCCESS になれば、ワークフローの実行は成功です。
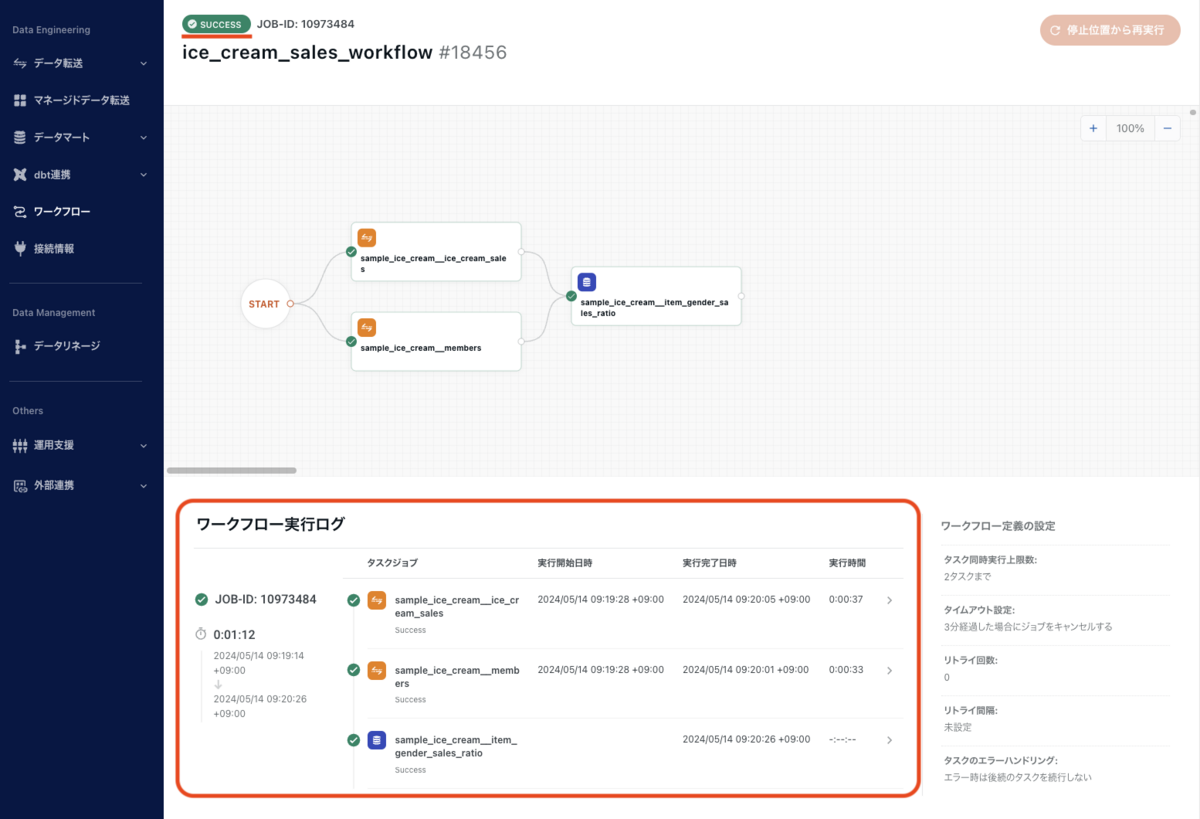
ワークフローの実行によって、外部データソースからのデータ取り込み、そして既存テーブルを利用した新たなデータマートの作成までが一気通貫で行えるようになりました。
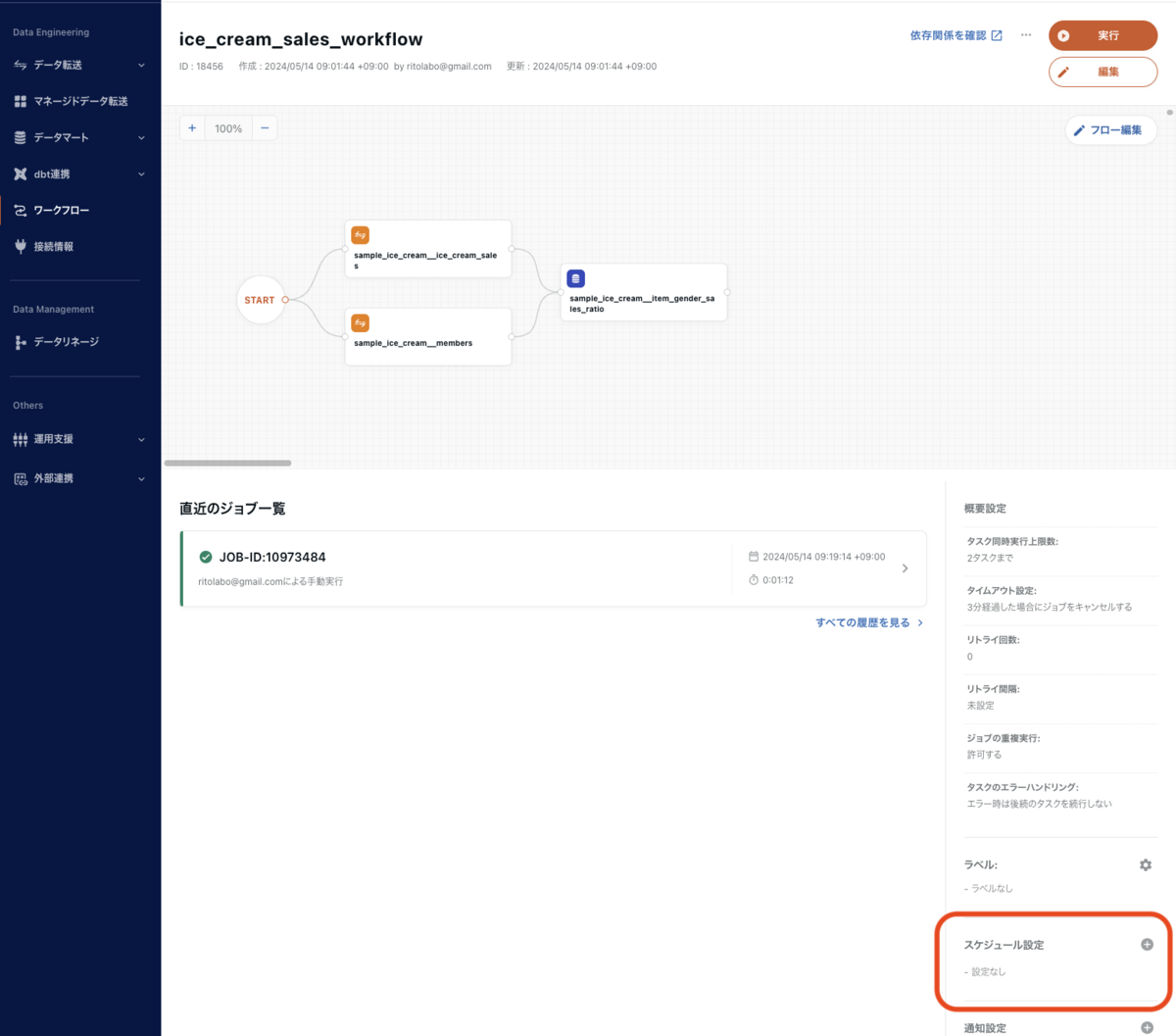
ワークフローのスケジュール設定
ワークフローを定期的に実行することで、外部データソースのデータが更新されても定期的に取り込めるようになり、分析基盤を最新の状態に保つことができます。
ワークフローのスケジュール設定は、概要設定から行えますので、興味があれば設定してみてください。
まとめ
本記事では、TROCCO と BigQuery を使って、外部データソースからのデータ取り込みから、データマートの作成、そしてワークフローによる一連の処理の自動化までを体験してきました。
ETL ツールを使うことで、データエンジニアリングの作業を効率化し、データ分析基盤を強化することができます。TROCCO は、直感的な操作性とワークフロー機能により、データの取り込みからデータマート作成までを一元管理できる便利なツールです。
今回は、サンプルデータを使った簡単な例でしたが、実際のビジネスにおいては、様々なデータソースから大量のデータを取り込み、複雑な変換処理を行うことが求められます。そのような場合でも、TROCCO を活用することで、データエンジニアリングのタスクを効率的に進められるでしょう。
データ活用が進むにつれ、データエンジニアリングの重要性はますます高まっています。TROCCO のような ETL ツールを上手に活用し、データ分析基盤を強化していくことが、ビジネスの意思決定の質を高め、競争力を向上させる鍵となるでしょう。
ぜひ、TROCCO を使ってみて、データエンジニアリングの世界に触れてみてください。データの力を活用し、ビジネスの可能性を広げていきましょう。