この記事は個人ブログと同じ内容です
似たような傾向にあるデータを分類し、何らかの洞察を得たい。
データを一定の規則で分類し類似性を探る「クラスター分析」その中でも k-means 法を用いた非階層クラスター分析を行なってみます。
クラスター分析(クラスタリング)
クラスター分析は、ある集団を類似度によってグループ化(分類)する分析手法。クラスタリングとも呼ばれる。
データの構造に関する直感を得るために使用される最も一般的な探索的データ分析手法の 1 つ。
データを一定の規則で分類することで、そのデータの特性を把握しやすくなる。
(例えば、集団 A は肉が好き。集団 B は魚が好き。集団 C は肉も魚も好き。のような洞察を得られたりする)
- クラスター分析の種類
K-Means 法(K-Means algorithms)
K-Means 法は、予め定義された K 個の重複しないクラスタにデータセットを分割しようとする反復アルゴリズム。
- 指定されたクラスタ数で各データポイントをランダムにクラスタ分けする。
- 各クラスタの重心を算出する。
- 各データポイントを、算出された重心に近いところへクラスタ再分類する
- 再分類されたクラスタの重心を再計算し、重心を再配置する。
3, 4 を反復して行い、データポイントのクラスタ移動がなくなったら終了。
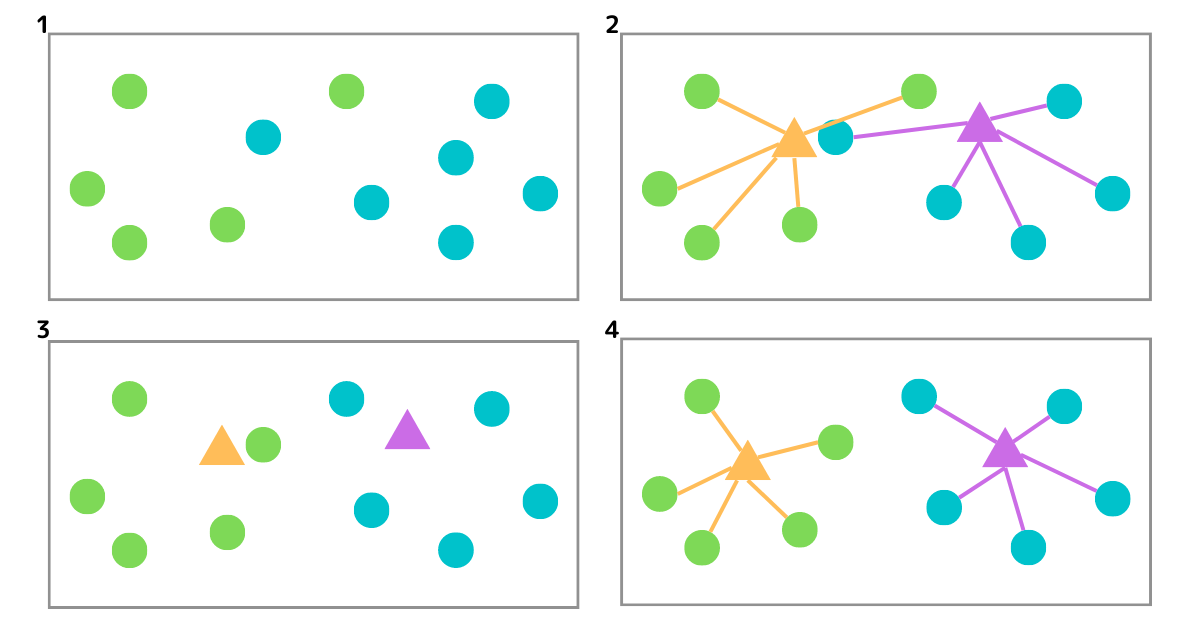
python でクラスター分析
それではクラスター分析を行なっていきます。
python の機械学習ライブラリ scikit-learn を用いて k-means 法による非階層クラスター分析を実施していきます。
卸売業者の顧客データ
サンプルのデータセットとして今回は、カルフォルニア大学(UC バークレー)から公開されている「卸売業者の顧客データ」を利用します。
UCI Machine Learning Repository: Wholesale customers Data Set
データ確認
データセットの中身を確認します。
import pandas as pd df = pd.read_csv('./wholesale_customers_data.csv') df.head()
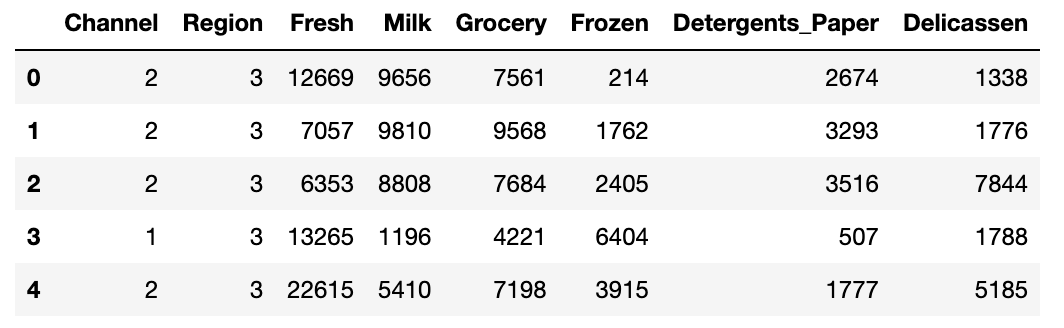
各カラムの意味は以下の通り
| column | 詳細 |
|---|---|
| Channel | 顧客チャネル - Horeca (ホテル/レストラン/カフェ) or 小売 |
| Region | 地域 |
| Fresh | 生鮮品の年間支出額 |
| Milk | 乳製品の年間支出額 |
| Grocery | 食料品の年間支出額 |
| Frozen | 冷凍食品の年間支出額 |
| Detergents_Paper | 洗剤・紙類の年間支出額 |
| Delicassen | 惣菜の年間支出額 |
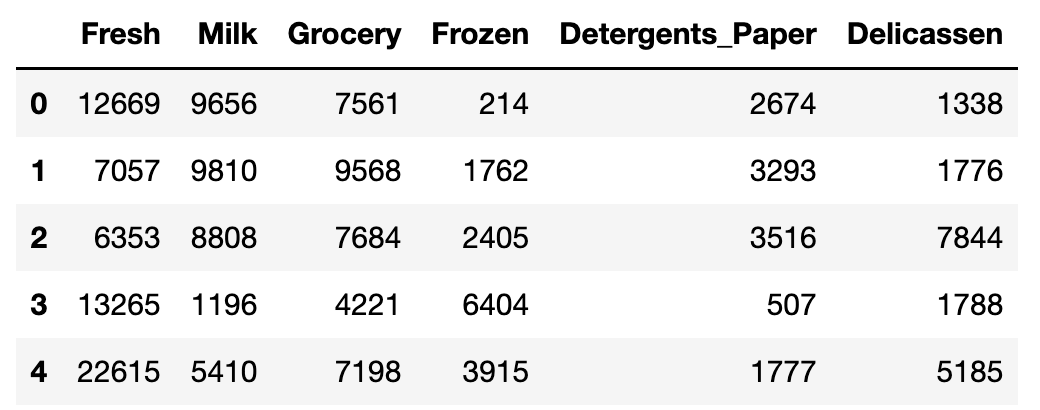
名義尺度である Channel と Region は外して、支出額でクラスタリングします。
df_train = df # Channel, Region カラムを除去 df_train = df_train.drop(['Channel', 'Region'], axis=1) df_train.head()
記述統計を確認します。
df_train.describe()
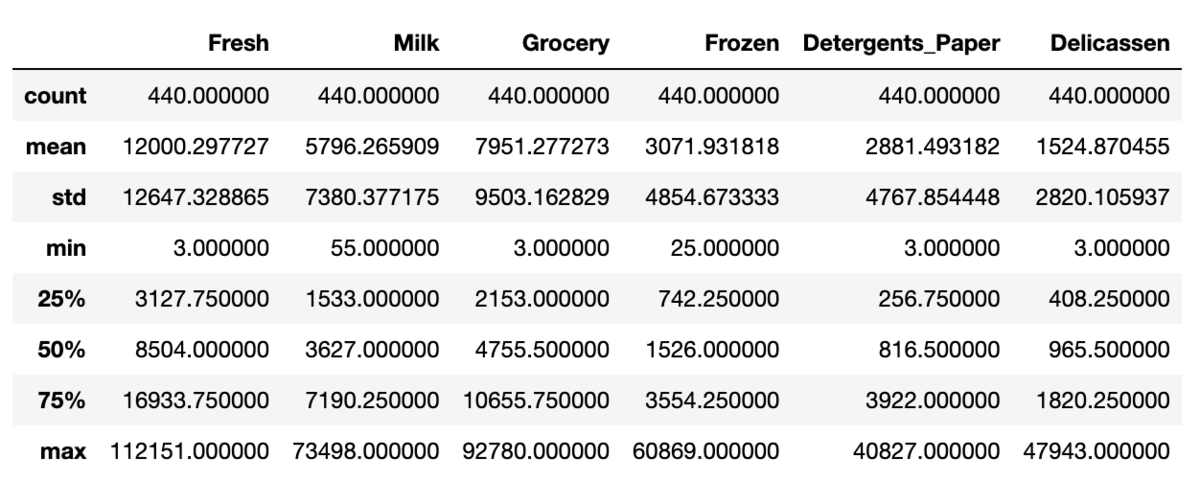
それぞれ min/max の幅が大きいので、度数分布表とヒストグラムを出力して各カラムにおけるデータの状況を確認しておきます。
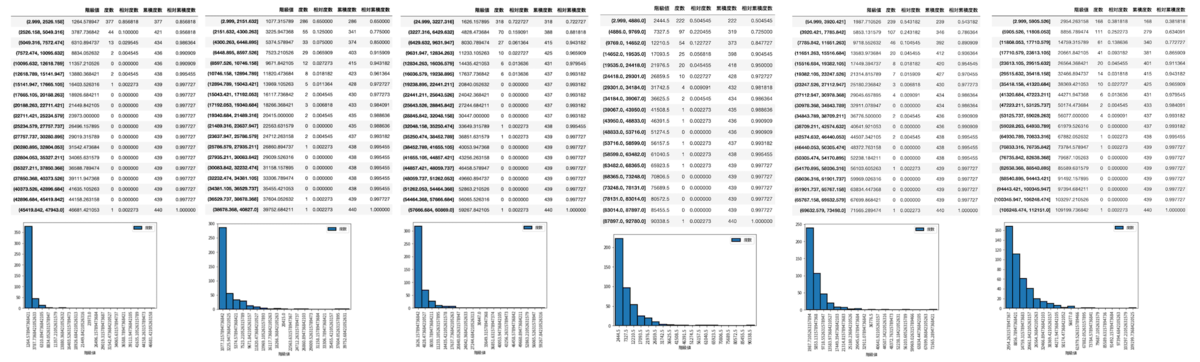
値が大きく、飛び抜けているデータが 1 件ありました。(飛び抜けてはいるが外れ値ではないと解釈し、データ自体は含めます。最終的にこの飛び抜けたデータもしっかり分類されていれば良し。)
支出額については上限(最大値)があるわけではないので、データは標準化してスケールしておきます。
標準化
飛び抜けている数値があったので、RobustScaler で標準化します。
Compare the effect of different scalers on data with outliers
# データを標準化 from sklearn import preprocessing rs = preprocessing.RobustScaler() rs.fit(df_train) arr_rs = rs.transform(df_train)
ペアプロット図で変数間の関係を見ておきます。
train_rs = pd.DataFrame(arr_rs, columns=df_train.columns.values) sns.pairplot(train_rs)
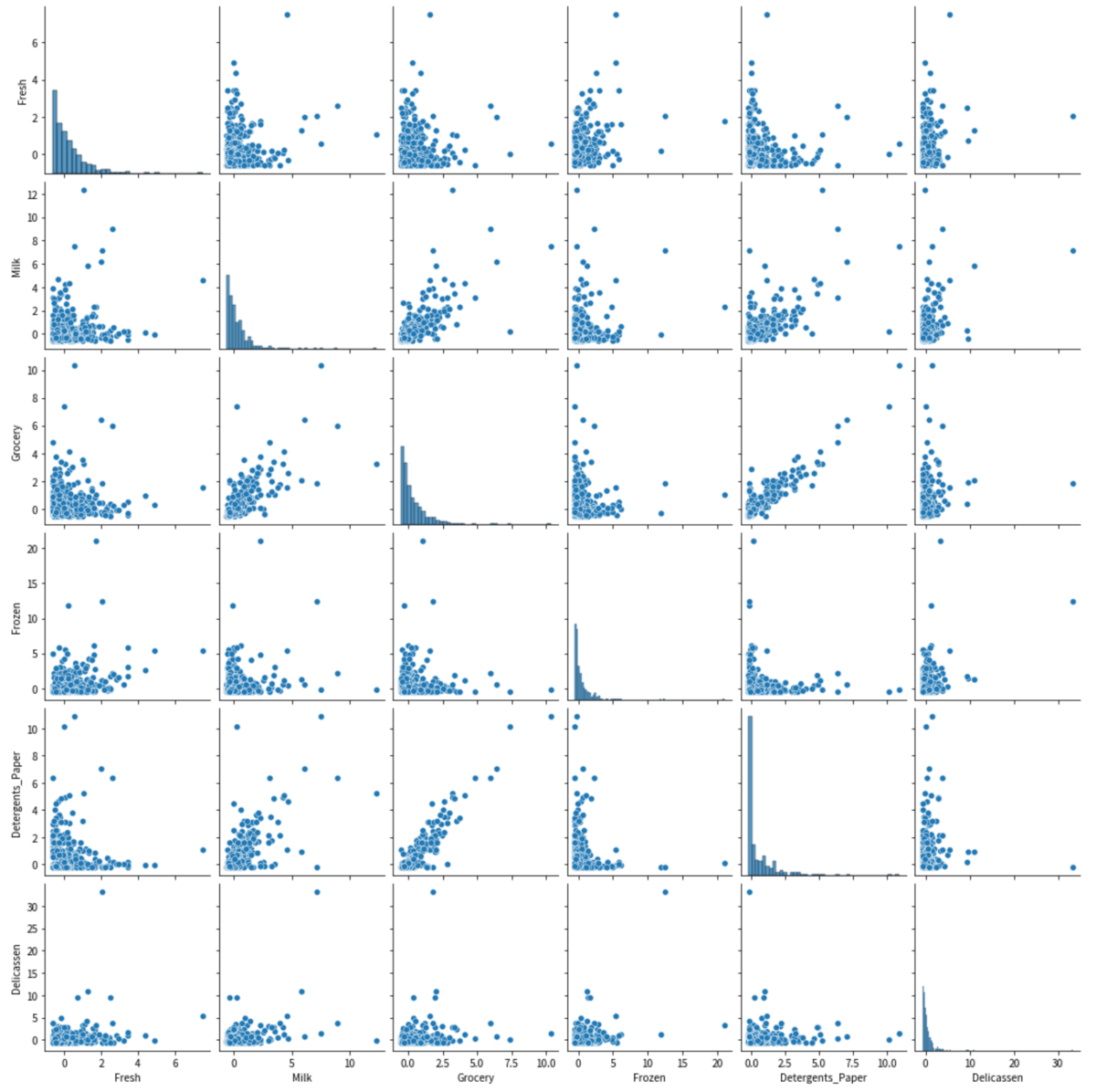
いくつか正の相関が見られるものがあります。今回は相関関係は関係ないですが、こういうところをさらっと見ておくだけでもデータを別の視点で探索していく上でのヒントになりそうです。
では、改めてデータと記述統計を確認します。
# データ確認 train_rs.head() # 記述統計 train_rs.describe()
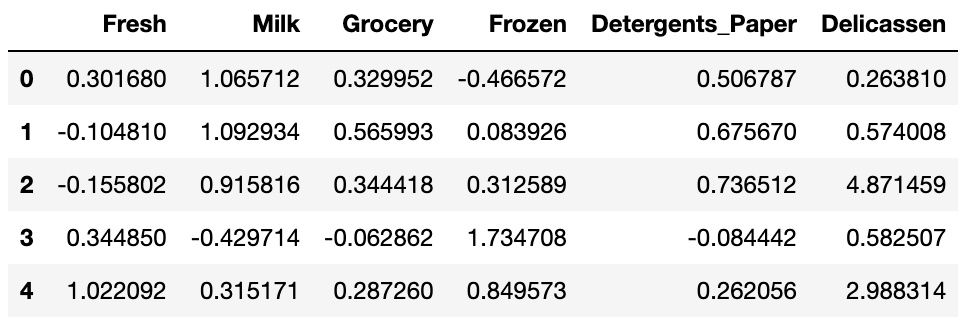
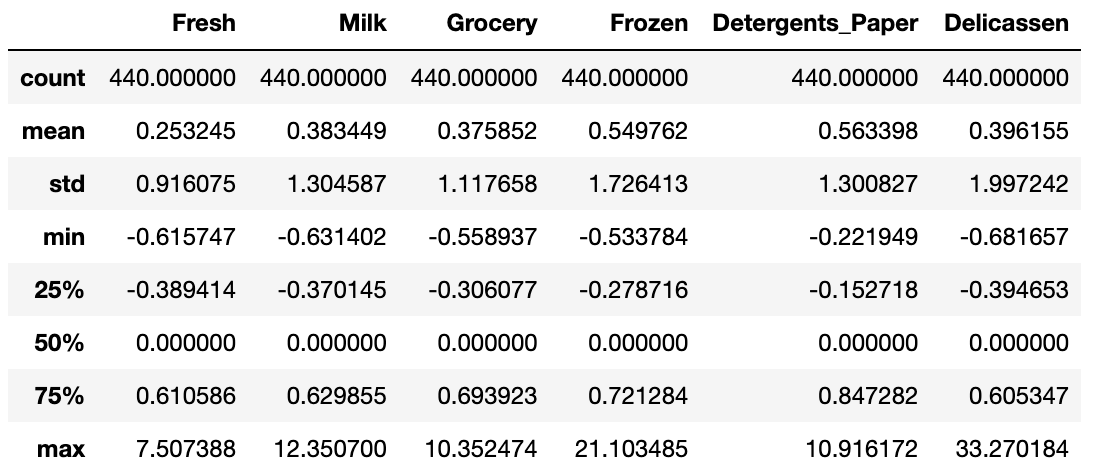
標準化されていることを確認できました。
次元削減
プロット解釈と処理高速化のために次元削減を行なっておきます。
PCA(主成分分析)でデータを 2 次元にまとめます。
from sklearn.decomposition import PCA # 次元削減 pca = PCA(n_components=2) pca.fit(train_rs) arr_2d = pca.transform(train_rs) train_2d = pd.DataFrame(arr_2d,columns=["pca_1","pca_2"])
次元削減後のプロットを見てみます。
sns.scatterplot( x='pca_1', y='pca_2', data=train_2d)
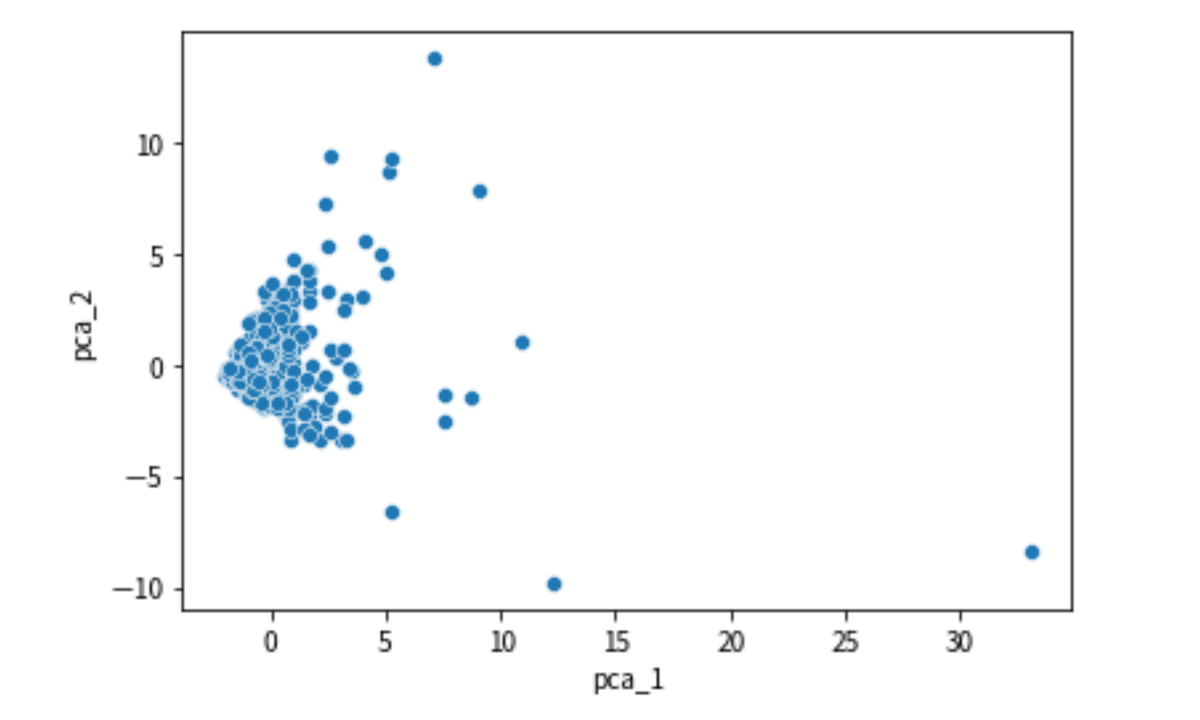
クラスタリング数の決定
非階層クラスター分析では、予めクラスター数を決めなければいけません。
k-means 法での最適なクラスター数を探るために、「エルボー法」を使って見てみます。
from sklearn.cluster import KMeans import matplotlib.pyplot as plt list_sse = [] for i in range(1,11): km = KMeans(n_clusters=i, random_state=0) km.fit(train_2d) list_sse.append(km.inertia_) plt.plot(range(1,11),list_sse,marker='o') plt.xlabel('Number of clusters') plt.ylabel('SSE') plt.show()

5, ないしは 6 あたりが最適そうです。
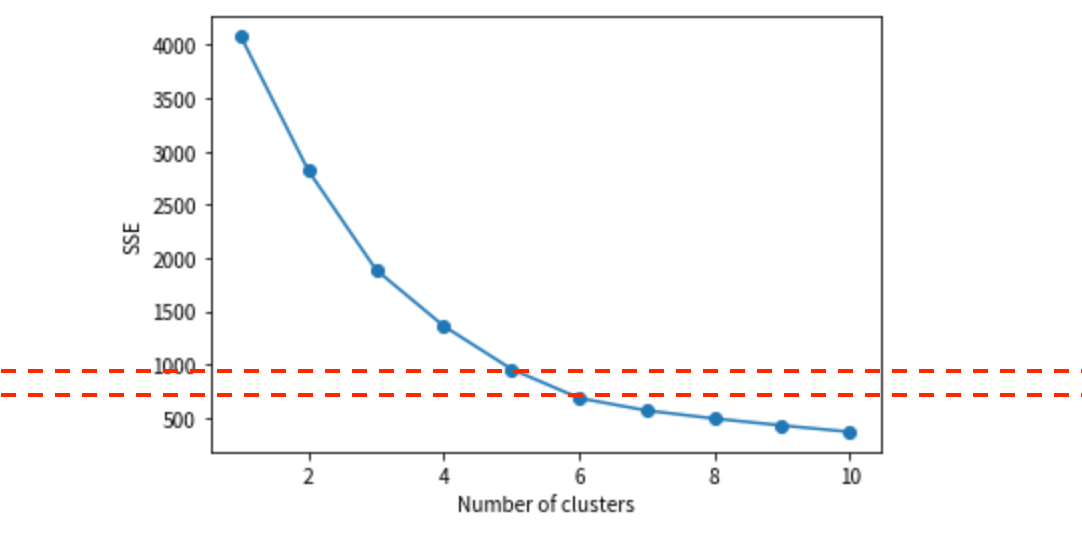
初めから増やしすぎてもクラスタの解釈が難しくなるため、クラスタ数は 5 でいきます。
クラスタリング
データの準備とクラスタ数の決定まで行い、クラスタリングの準備が整いました。
k-means 法で非階層クラスター分析を実行していきます。
from sklearn.cluster import KMeans # クラスタ数 number_cluster=5 kmeans = KMeans(n_clusters=number_cluster, random_state=0) kmeans.fit(train_2d) pred = kmeans.predict(train_2d)
クラスタリング結果を先ほどのプロットに反映して見てみます。
train_2d["label"] = pred train_2d["label"] = train_2d["label"].astype("int") # 可視化 sns.scatterplot( x='pca_1', y='pca_2', hue="label",data=train_2d,palette="Set1")
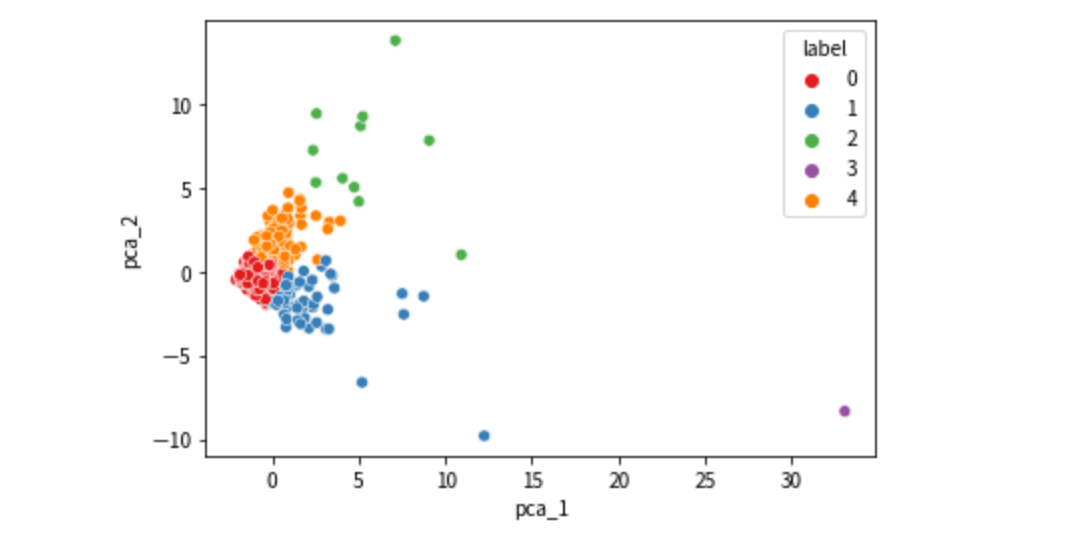
目視の限りでは、良い感じにクラスタリングできていそうです。
クラスタを分析
分類したデータを分析してみます。それぞれのクラスタごとに、各部門の支出額平均を積み上げてグラフで可視化してみます。
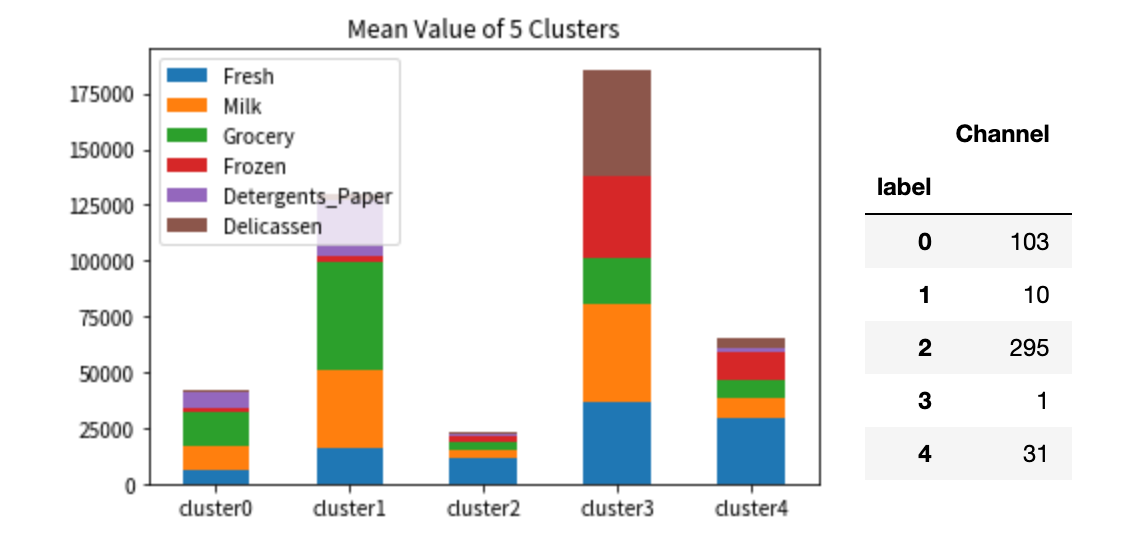
グラフの脇にそれぞれのクラスタの分類数を載せました。
クラスタ 1 と 3 は支出額が大きいですが、分類数が少ないため、大手の卸売業者かもしれません。
それらを除いたクラスタ 0, 2, 4 で見てみると、クラスタ 2 と 4 は支出の内訳が似ています。クラスタ 2 の規模が大きいグループがクラスタ 4 かもしれません。そしてこれらは、生鮮品の卸がメインであることがわかります。
クラスタ 0 は、支出額的にはクラスタ 2 と 4 の間にいますが、それぞれの支出配分を見ると、クラスタ 2 と 4 は生鮮品がメインであるのに対して、クラスタ 0 は食料品がメインであることがわかります。
こんな具合で、クラスタリングしたことでデータを一定のセグメントに分けられました。
ちなみにこのデータセットには卸売業者の販売チャネルもあったので、チャネルごとにクラスタリングしてみます。
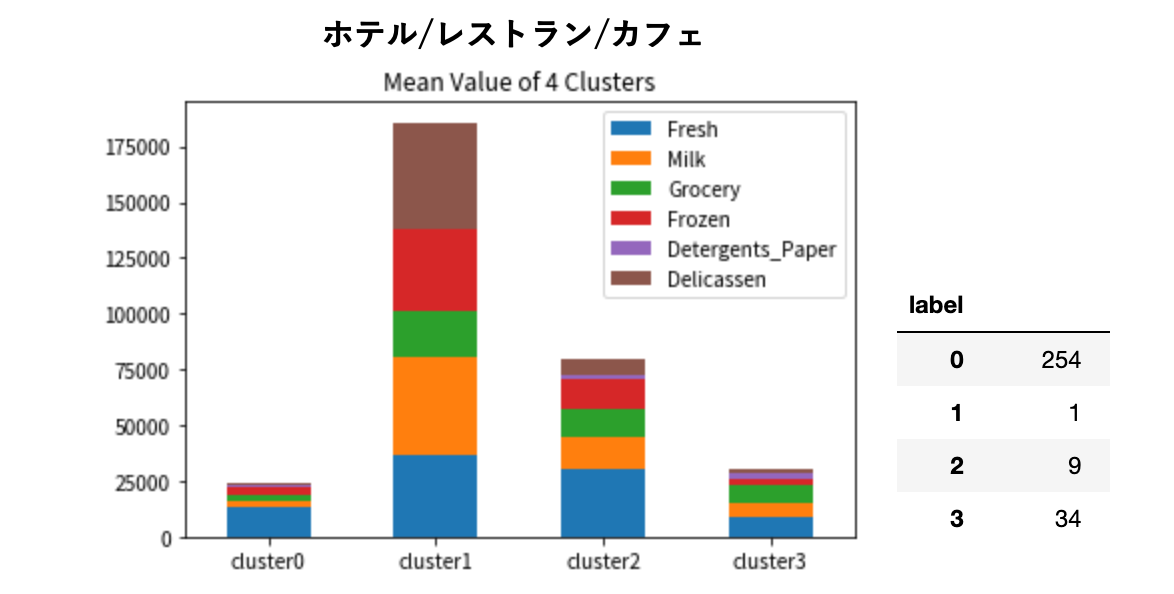
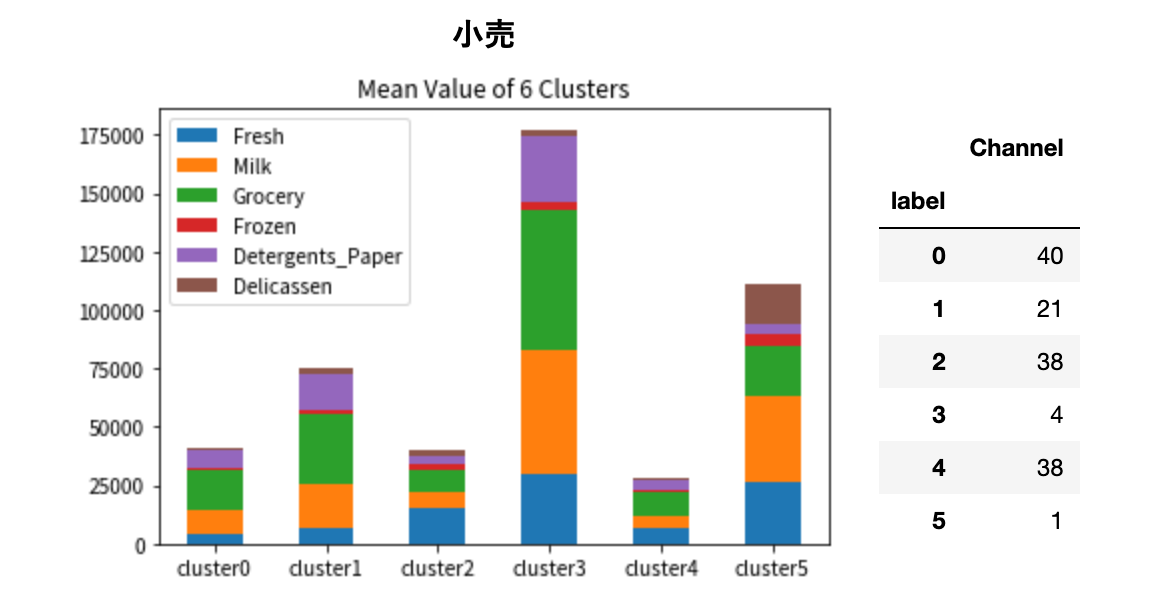
売上規模と支出内訳のパターンできれいにクラスタリングされていることがわかります。飲食と小売って結構別ものですから、セグメント分けたことでより明確に見て取れるようになりました。
データが意味を持つように
「顧客データが溜まってきたけれど、これらの顧客はどういった傾向にある顧客なのか。」
ただデータだけあって、そのデータから何もつかめていない。そんな時にこういったクラスター分析によってデータの一定の類似性を発見でき、それによってさらに深くデータを分析していくそのきっかけにできる。まさに「探索的データ分析手法」であり、データの構造に関する直感を得るために使用される。
「そのデータが意味を持つ瞬間」を体験でき、 クラスター分析で得られる知見を実感できました。
現在 back check 開発チームでは一緒に働く仲間を募集中です。 herp.careers herp.careers herp.careers