この記事は個人ブログと同じ内容です
www.ritolab.com
2021 年 5 月下旬 に AWS から App Runner というサービスがローンチされました。
今回は App Runner を使ってアプリケーションをデプロイしてみます。
AWS App Runner
AWS App Runner は、インフラストラクチャを管理せずに AWS にアプリケーションをデプロイするサービスです。
ソースコードまたはコンテナイメージを指定するだけで、App Runner がアプリケーションを自動的にビルドおよびデプロイし、ネットワークトラフィックの負荷を分散し、自動的にスケールアップまたはスケールダウンし、アプリケーションの状態を監視し、暗号化を提供します。
aws.amazon.com
- ソース(Github ソースコードまたはコンテナイメージ)が update されると自動でデプロイしてくれる(自動・手動は選択可)
- 自動でスケーリングが行われ、設定したしきい値に従って自動でスケールアップ・ダウンされる
- 公開されたアプリケーションはロードバランシングされており自動でトラフィックを分散してくれる
- 証明書(TLS)も管理されデフォルトで付与される URL は HTTPS でアクセス可能。更新も自動で行われる
aws.amazon.com
docs.aws.amazon.com
App Runner では 1 つのデプロイを「サービス」と呼び、サービスを作成するだけでアプリケーションを公開できます。
アプリケーションについて
App Runner では、アプリケーションソースを「Github のソースコード」または「コンテナイメージ」かのどちらかを選択する事ができます。
今回は ECR にコンテナイメージを設置して、それをデプロイしていこうと思います。
アプリケーションについては、以下 App Runner のワークショップで使われていた node のソースとコンテナを使用します。
www.apprunnerworkshop.com
App Runner を構築する
ここから実際に App Runner を使ってデプロイができるまで進めていきます。
いつもであれば構成は terraform で管理するのですが、App Runner は「サービス作成=デプロイ」となるため、App Runner の構成を terraform で管理する必要性がありませんでした。(terraform で予めサービスを作成しておいてそれを何かで起動したり... といった概念ではない)
なので、最低限だけ terraform で作成して、ECR への image の push と、App Runner のサービス作成は Github Actions で行っていきます。
先述のアプリケーションと併せて、最終的には以下のファイル構成になります。
root/
├── .github
│ └── workflows
│ └── deploy.yml
├── Dockerfile
├── index.js
├── package.json
├── source-configuration.json.template
└── terraform
├── main.tf
└── terraform.tfvars
ECR Repository 作成
コンテナイメージを設置する ECR Repository を作成します。
main.tf
# variables
variable "aws_id" {}
variable "aws_access_key" {}
variable "aws_secret_key" {}
variable "aws_region" {}
provider "aws" {
access_key = var.aws_access_key
secret_key = var.aws_secret_key
region = var.aws_region
}
# ECR Repository
resource "aws_ecr_repository" "app" {
name = "sample_node_for_app_runner"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
}
ECR リポジトリを作成しているだけです。当然空っぽなので、コンテナイメージについては後で Github Actions で push していきます。
ポイントとしては自動デプロイを有効にしたい場合、イメージのタグは固定する必要があるため、image_tag_mutability は MUTABLE である必要がありました。(サービス作成時にイメージのタグも指定するため)
App Runner の IAM Role 作成
App Runner に付与する IAM Role を作成します。
App Runner が ECR にアクセスできるようにするロールです。
main.tf
# IAM Role for AppRunner
## AWS管理ポリシー
data "aws_iam_policy" "AWSAppRunnerServicePolicyForECRAccess" {
arn = "arn:aws:iam::aws:policy/service-role/AWSAppRunnerServicePolicyForECRAccess"
}
## IAM Role - for AppRunner
resource "aws_iam_role" "for_app_runner" {
name = "tf-AppRunnerECRAccessRole"
description = "This role gives App Runner permission to access ECR"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Sid = ""
Principal = {
Service = [
"build.apprunner.amazonaws.com"
]
}
},
]
})
}
## Attach Policy to Role
resource "aws_iam_role_policy_attachment" "app_runner" {
role = aws_iam_role.for_app_runner.name
policy_arn = data.aws_iam_policy.AWSAppRunnerServicePolicyForECRAccess.arn
}
ポリシー自体は AWS で管理しているものを使用しています。
デプロイ用 IAM User 作成
Github Actions から ECR への image の push と App Runner のサービス作成を行なうために、デプロイ用の IAM User を作成します。
main.tf
# deploy user
## IAM User
resource "aws_iam_user" "deploy_app_runner" {
name = "deploy_app_runner"
}
## IAM Policy
resource "aws_iam_policy" "for_deploy_app_runner" {
name = "deploy-app-runner-policy"
description = "ECR push and App Runner operations Policy."
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload",
"ecr:PutImage",
"apprunner:ListServices",
"apprunner:CreateService",
"iam:PassRole",
"iam:CreateServiceLinkedRole",
]
Resource = "*"
}
]
})
}
## attach Policy
resource "aws_iam_user_policy_attachment" "deploy_app_runner" {
user = aws_iam_user.deploy_app_runner.name
policy_arn = aws_iam_policy.for_deploy_app_runner.arn
}
ポリシーは「ECR への push」と「App Runner のサービス作成」のためのミニマムの権限を付与しています。
terraform で IAM User を作成しましたが、アクセスキーは AWS コンソール画面から手動で生成します。
ECR への image 登録と App Runner サービス作成
ここからは Github Actions で ECR への image 登録と App Runner サービス作成を行っていきます。
deploy.yml
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}
- name: Amazon ECR "Login" Action for GitHub Actions
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1
- name: Build, tag, and push image to Amazon ECR
id: build-image
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
ECR_REPOSITORY: ${{ secrets.AWS_ECR_REPOSITORY }}
run: |
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:latest .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:latest
- name: Create App Runner Service if no exist.
env:
AWS_ID: ${{ secrets.AWS_ID }}
AWS_REGION: ${{ secrets.AWS_REGION }}
SERVICE_NAME: sample_node
run: |
SERVICE=`aws apprunner list-services --query "length(ServiceSummaryList[?ServiceName=='$SERVICE_NAME'])"`
if [ $SERVICE -eq 0 ]; then
sed -e "s/<AWS_ID>/${AWS_ID}/" -e "s/<AWS_REGION>/${AWS_REGION}/" ./source-configuration.json.template > ./source-configuration.json
aws apprunner create-service --cli-input-json file://source-configuration.json
fi
App Runner に関しては、既にサービスが作成されているかチェックし、存在しなければサービスを作成する。という処理にしています。
実際のところ、AWS CLI を使えばコマンド一発でサービスは作成できます。
docs.aws.amazon.com
今回でいうとここです
aws apprunner create-service --cli-input-json file://source-configuration.json
サービスを作成する際に、設定項目を渡す必要があるので、それは Github Actions の中で json ファイルを作成しています。
アプリケーションのソースに json ファイルのテンプレートを作成しておいて、 Github Actions で必要な設定値を入れているだけです。
source-configuration.json.template
{
"ServiceName": "sample_node",
"SourceConfiguration": {
"ImageRepository": {
"ImageIdentifier": "<AWS_ID>.dkr.ecr.<AWS_REGION>.amazonaws.com/sample_node_for_app_runner:latest",
"ImageConfiguration": {
"Port": "3000"
},
"ImageRepositoryType": "ECR"
},
"AutoDeploymentsEnabled": true,
"AuthenticationConfiguration": {
"AccessRoleArn": "arn:aws:iam::<AWS_ID>:role/tf-AppRunnerECRAccessRole"
}
},
"HealthCheckConfiguration": {
"Protocol": "TCP",
"Interval": 10,
"Timeout": 5,
"HealthyThreshold": 1,
"UnhealthyThreshold": 5
},
"AutoScalingConfigurationArn": "arn:aws:apprunner:<AWS_REGION>:<AWS_ID>:autoscalingconfiguration/minimum_setting/1/xxxxxxxxxxxxxxxxxxxxxxxxxxx"
}
この辺の項目は AWS コンソール画面でのサービス作成時に出てくるものとほぼ一緒なので、最初はコンソール画面からサービス登録してみるとイメージが掴みやすいと思います。
ちなみに今回は、スケール設定に関してはミニマムの設定にしておきたかったので、デフォルトのものではなくて予め作成した設定を指定しています(minimum_setting)
動作確認
一通りの設定は完了したので、terraform で AWS のリソースを作成したら Github Actions からデプロイすると、App Runner のサービスが作成されます。
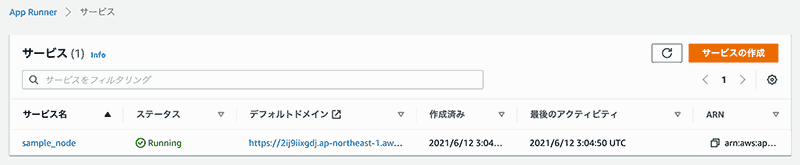
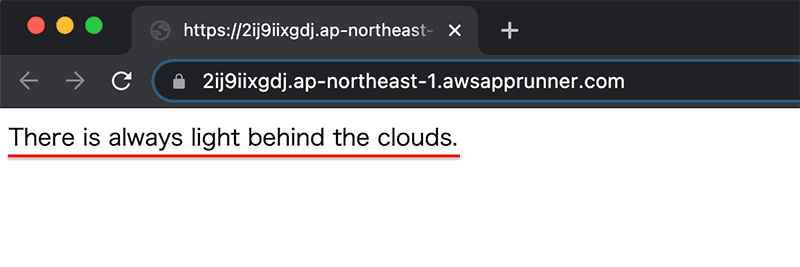
デフォルトドメインに表示されている URL にブラウザからアクセスすると、アプリケーションが公開されていることが確認できます。
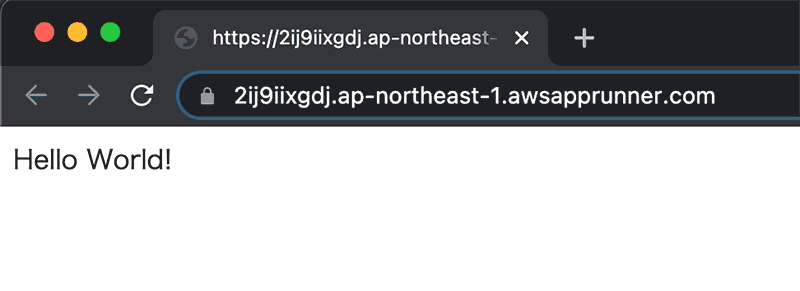
また、コンテナイメージが更新される(アプリケーションのソースコードを更新してイメージを再 pushする)と、自動的にデプロイが走ります。
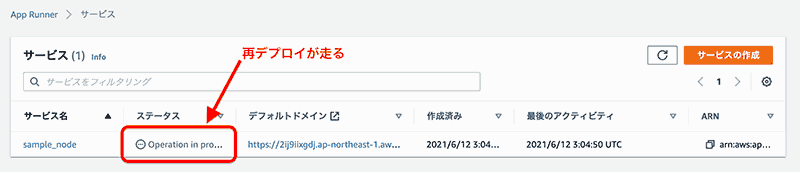
ソースが更新されるとサービスも更新されることが確認できました。
まとめ
簡単にデプロイできて、ネットワーク周りやスケーリングを気にしなくて良いのは便利だなと思いました。
ただし、コンテナイメージでも github リポジトリでも、1つのソース(イメージ・リポジトリ)しか選択できないので、フロントエンドとバックエンドがソースとして別れている場合はすべてを 1 つのサービスで一撃構築!みたいな用途では使えない。(nginx と php-fpm 2コンテナ兄弟みたいなやつも同じくダメ)
ネットワークからスケーリングまでフルマネージドである特性上、全部のせアプリケーションでないと成立しないっていうのには納得。(片側だけ動かすとかなら良いかも)
Github リポジトリを使う場合も、AWS コンソール画面から App Runner のサービス作成をやってみましたが、サービス作成画面で AWS と Github のリポジトリを連携させるだけなので操作は簡単でした。
ちなみにサービス作成してから構築完了までは約 5 分ほど、削除に関してはおよそ 1 分以内程度かかりました。
AWS からは便利なサービスがどんどん出てきますが、特性を知って必要な時に選択肢の一つとして出せるようになっておきたいですね。