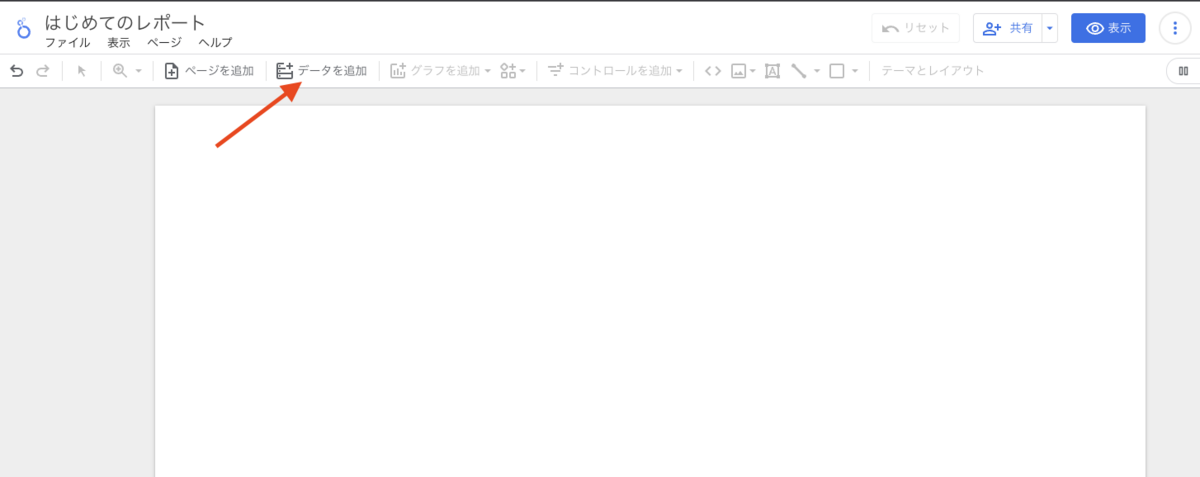
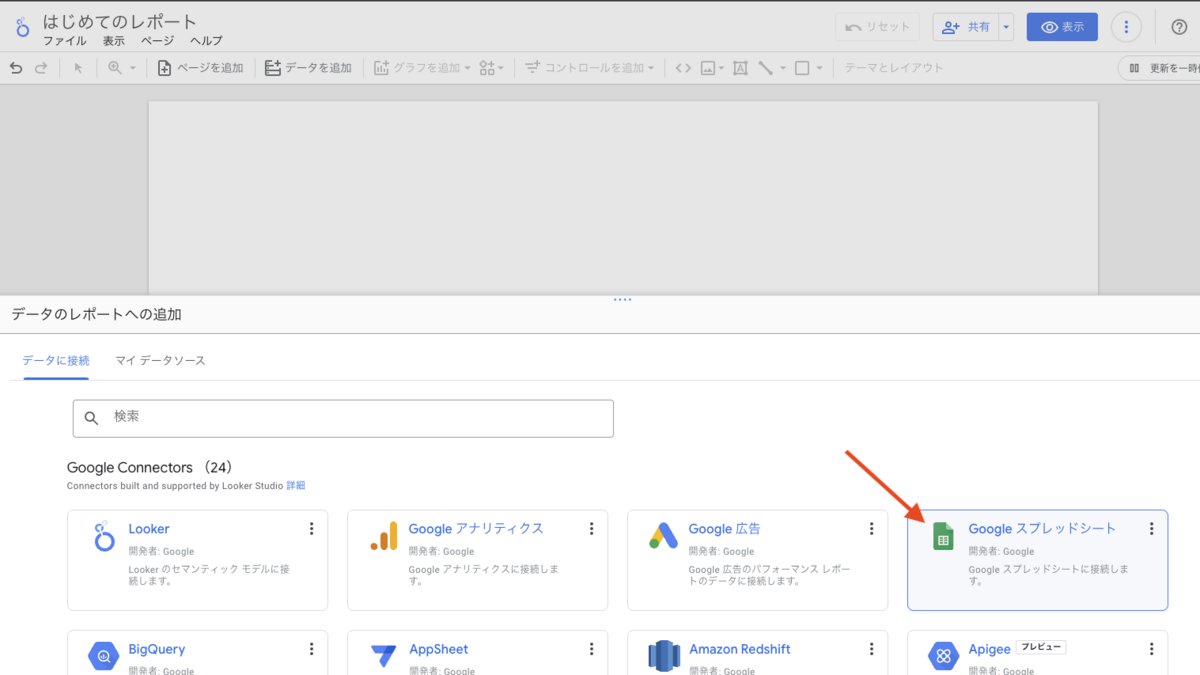
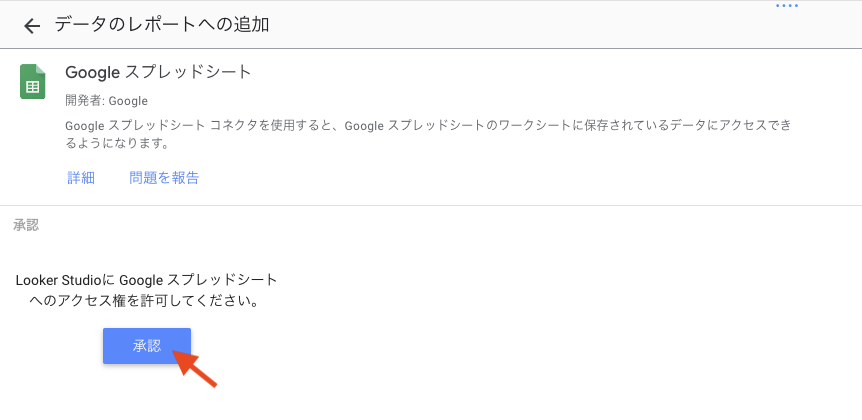
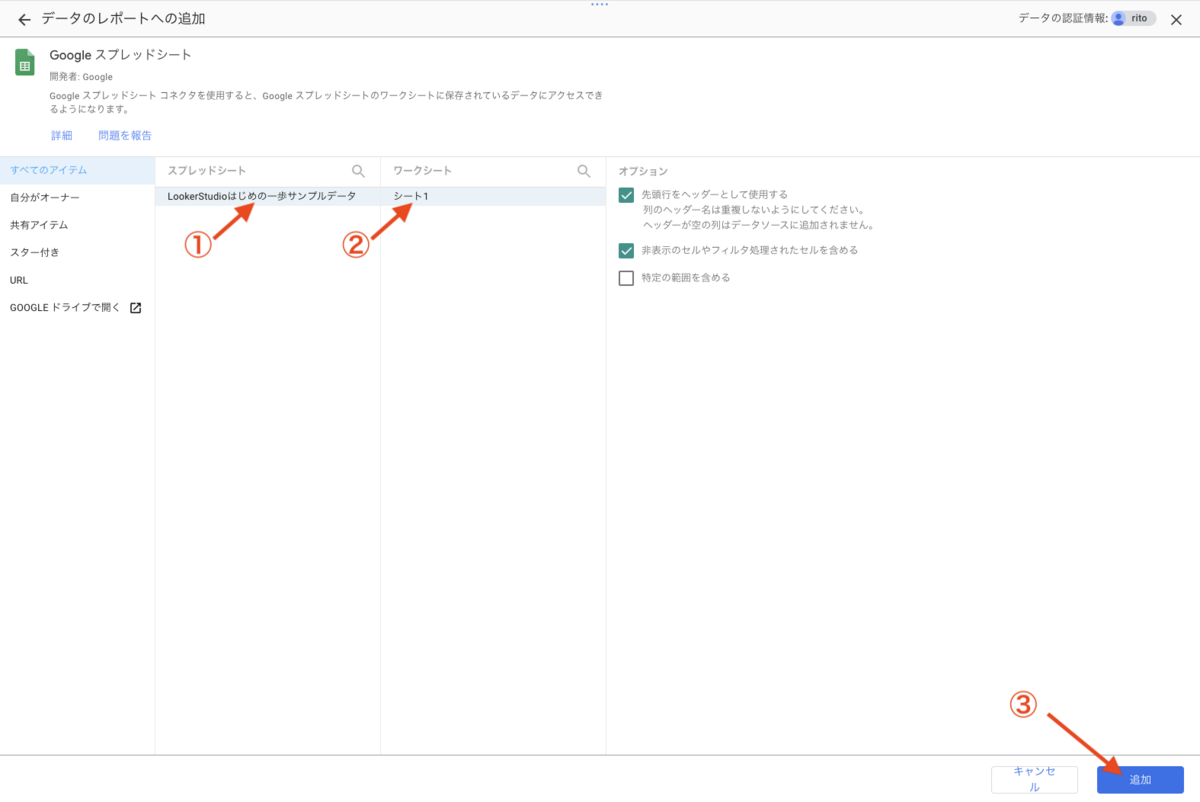
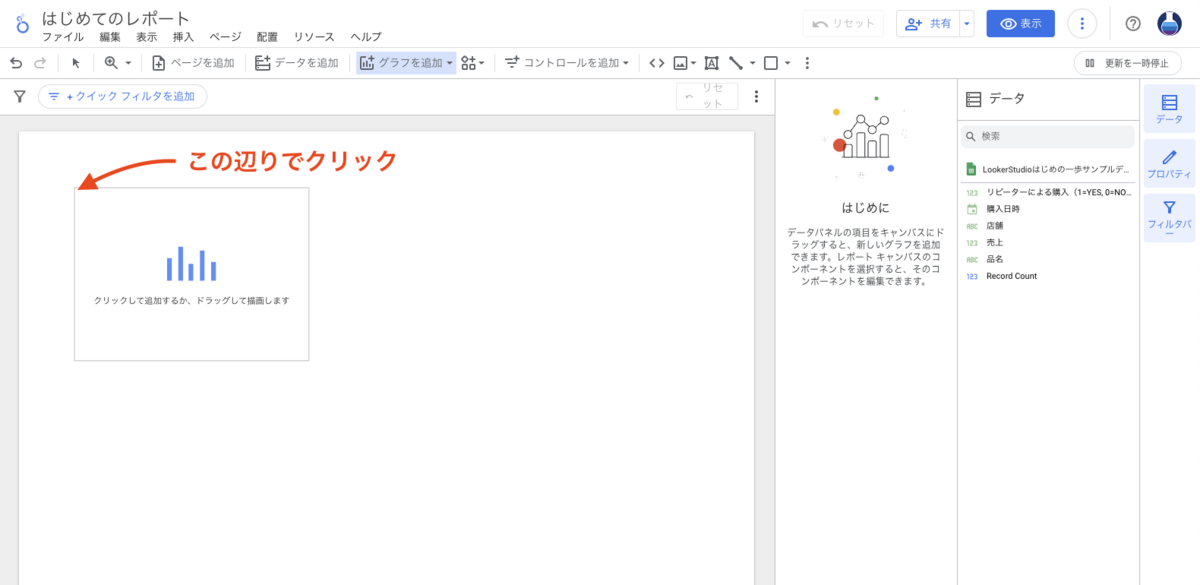
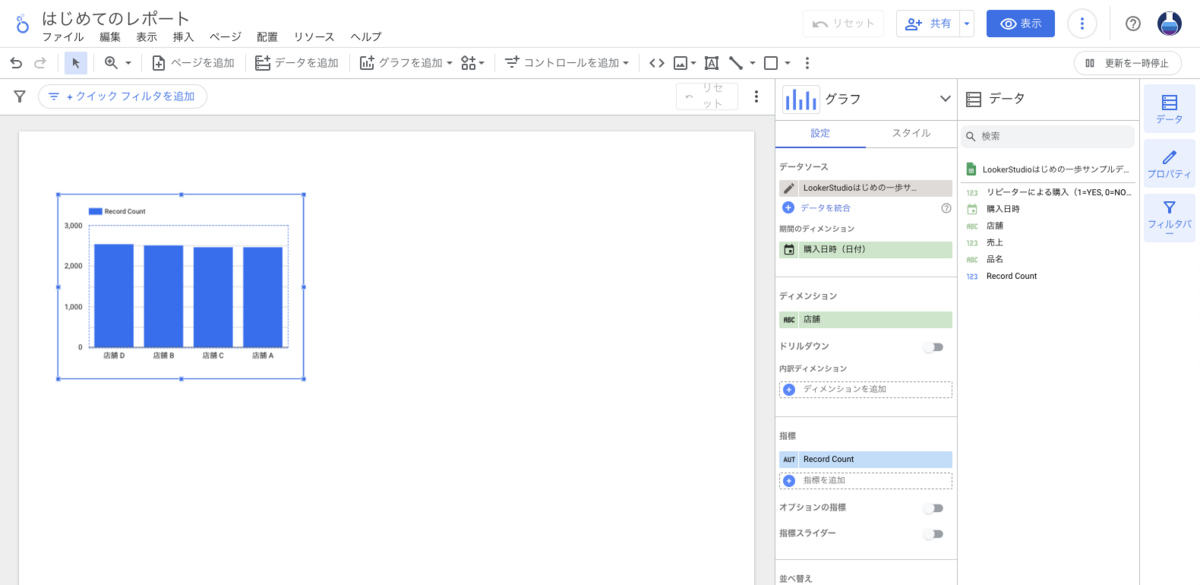
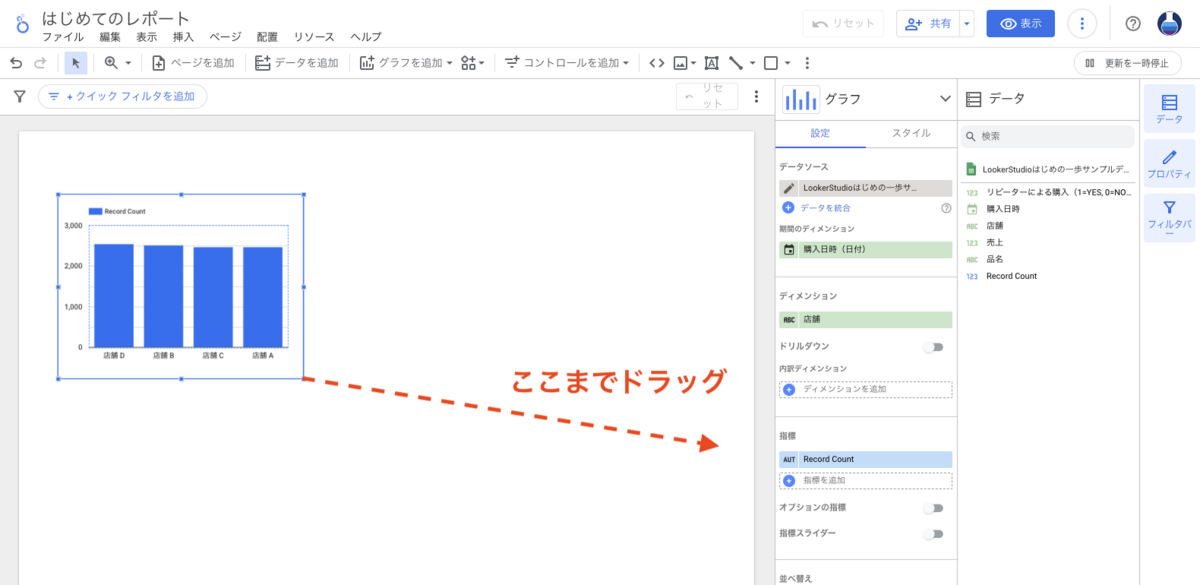
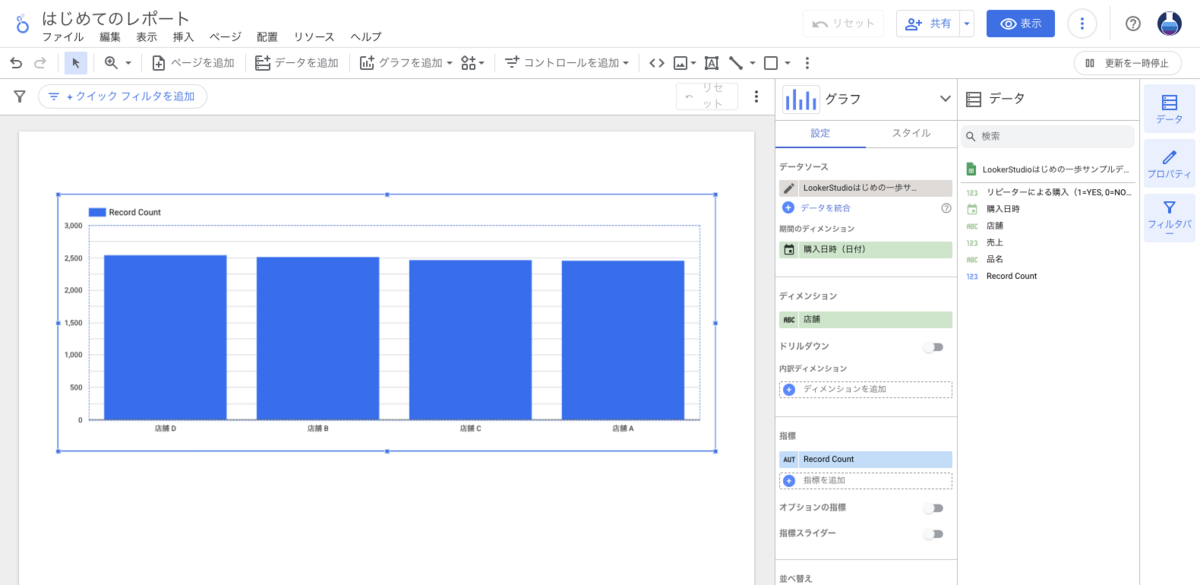
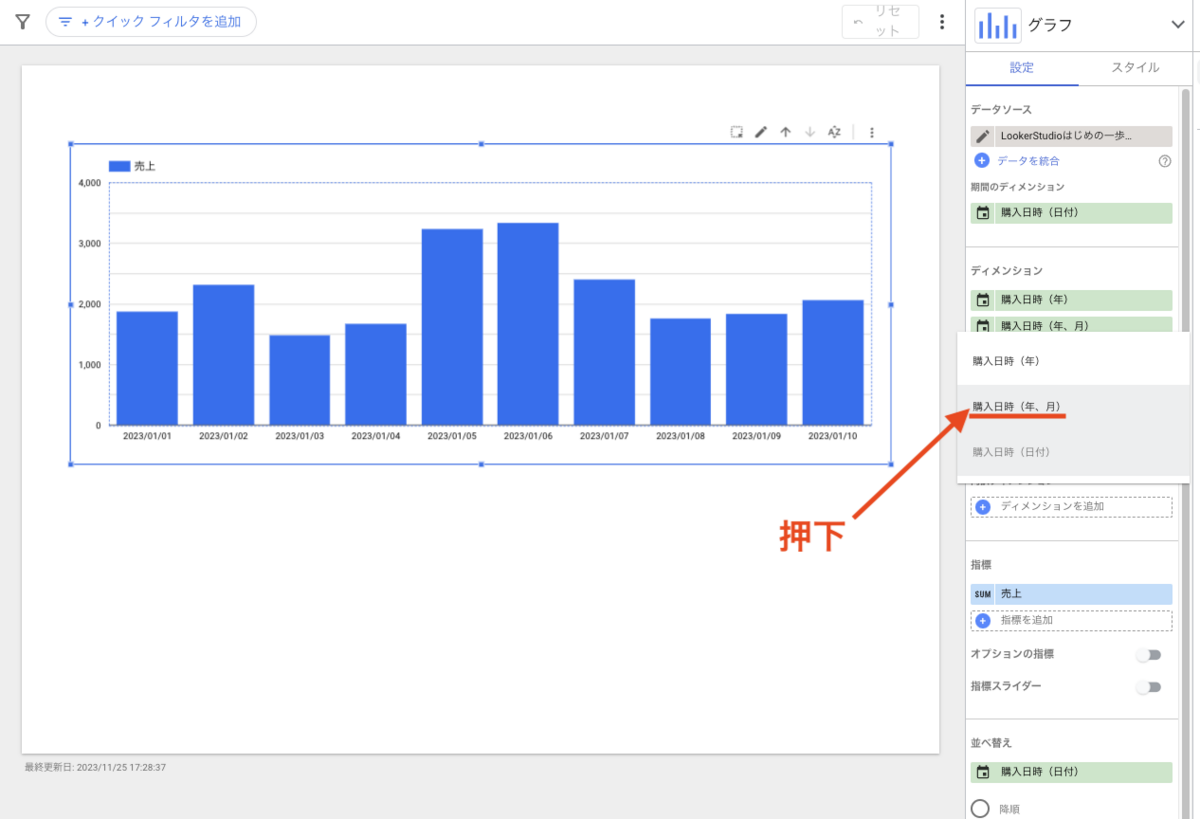
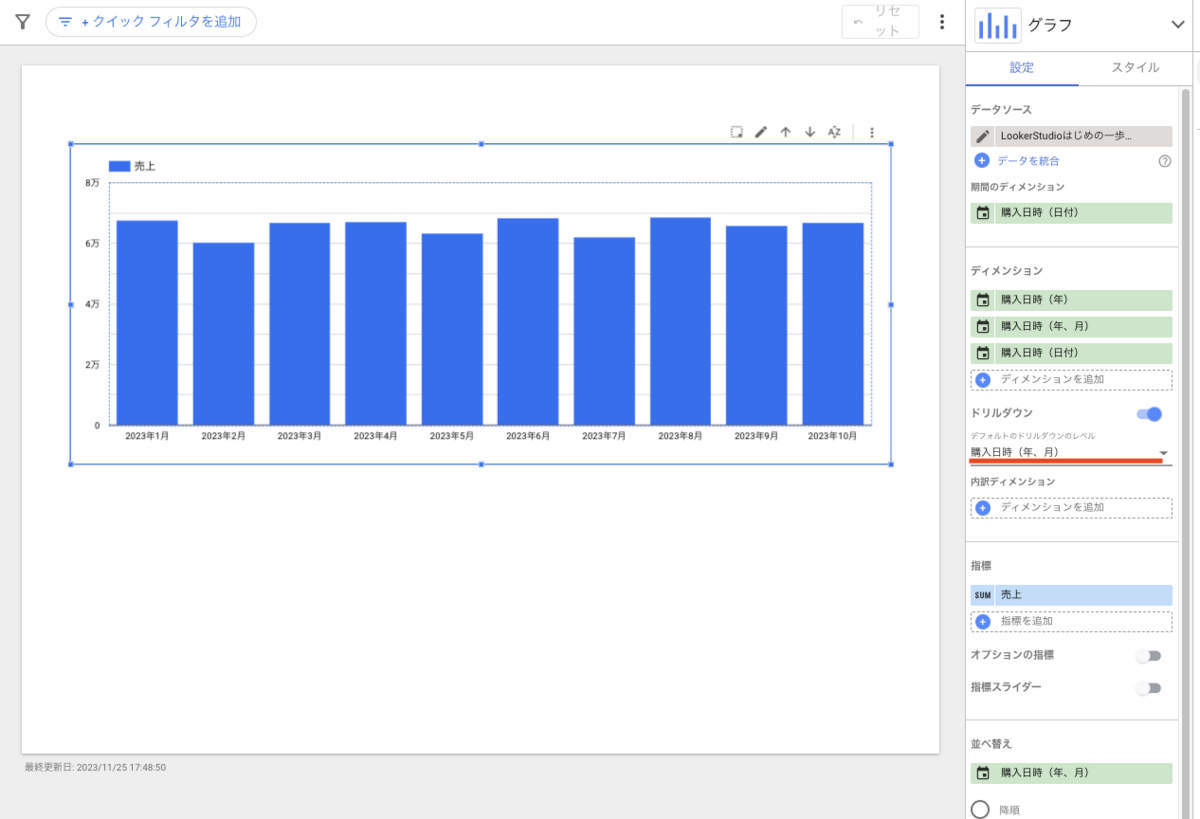
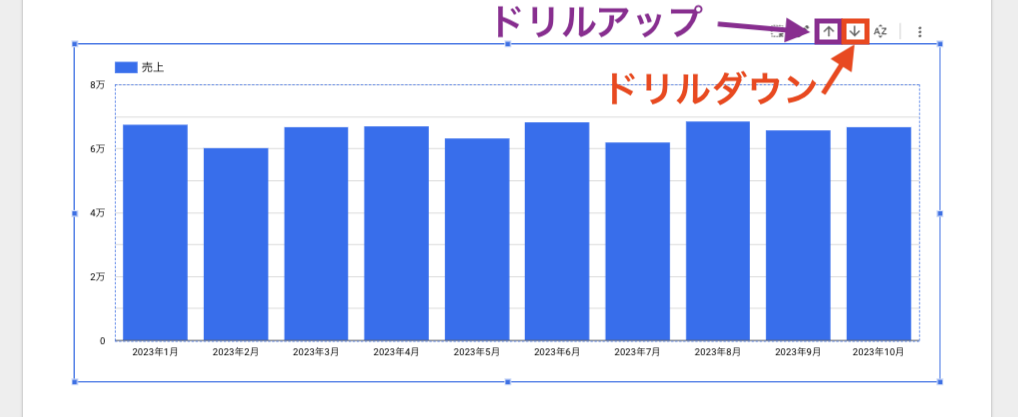
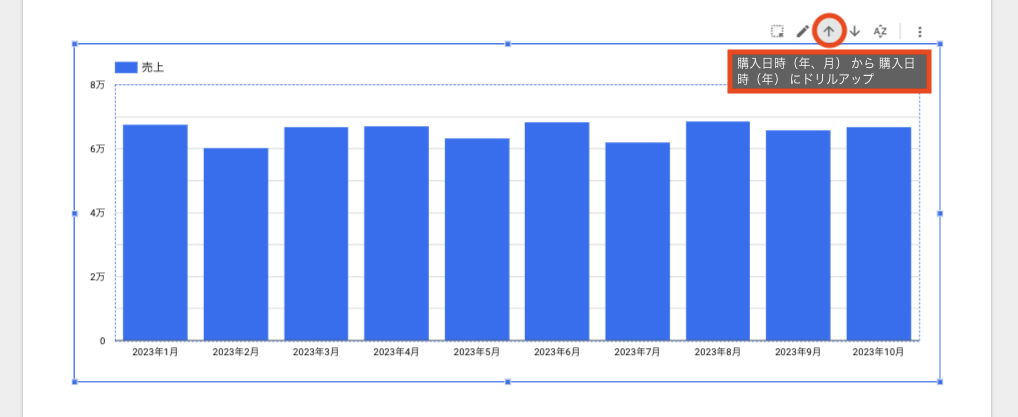
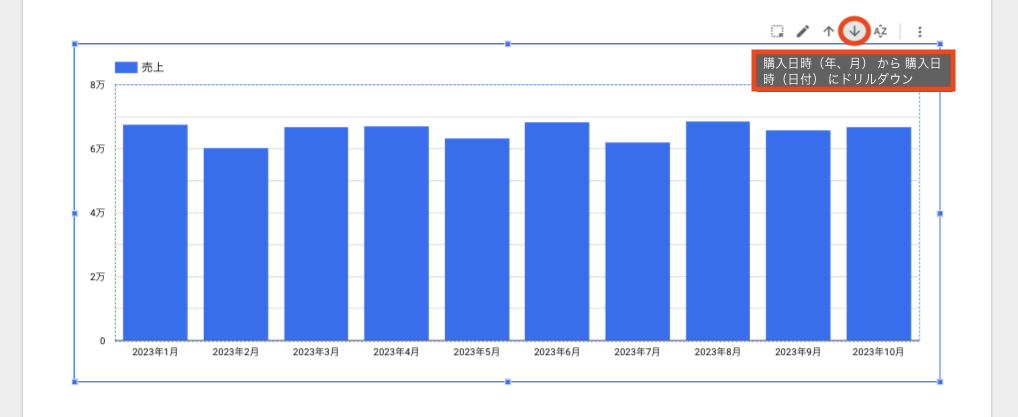
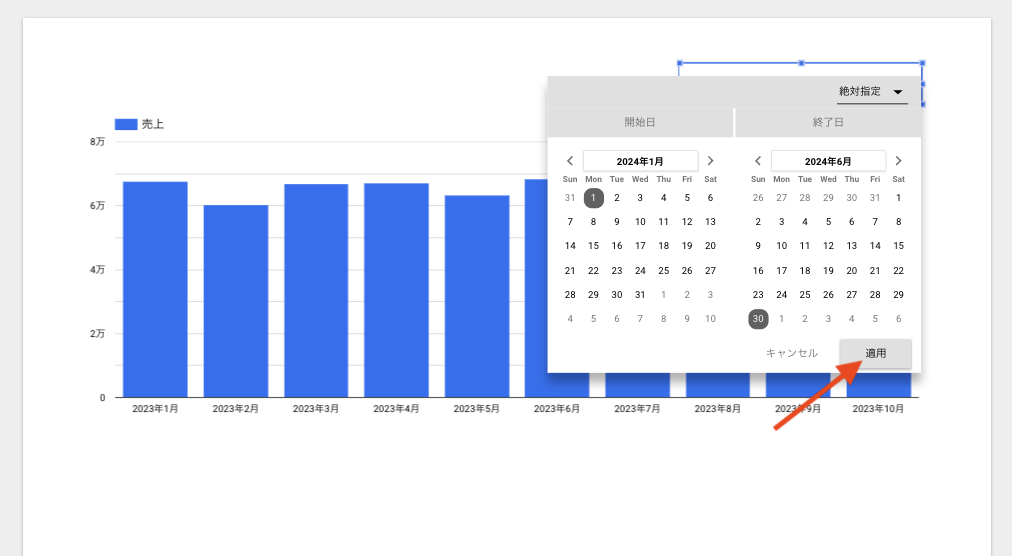
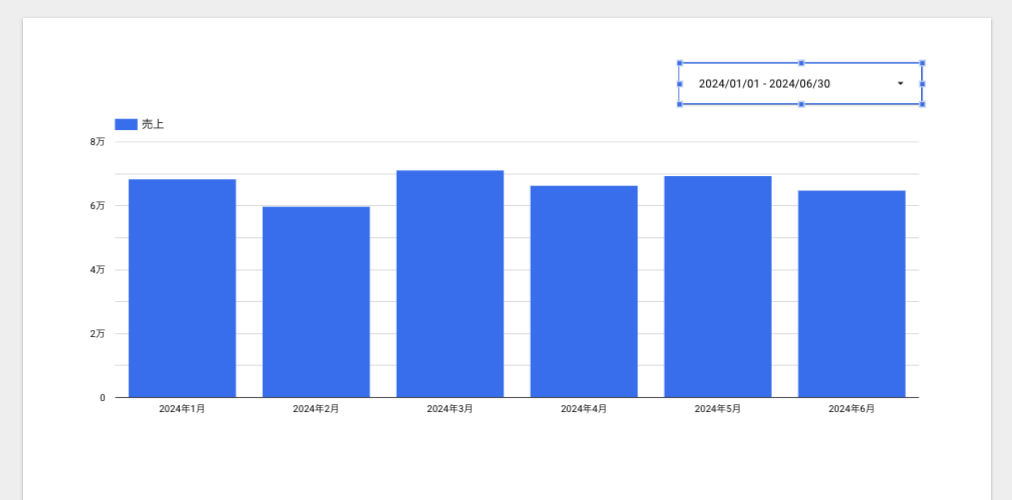
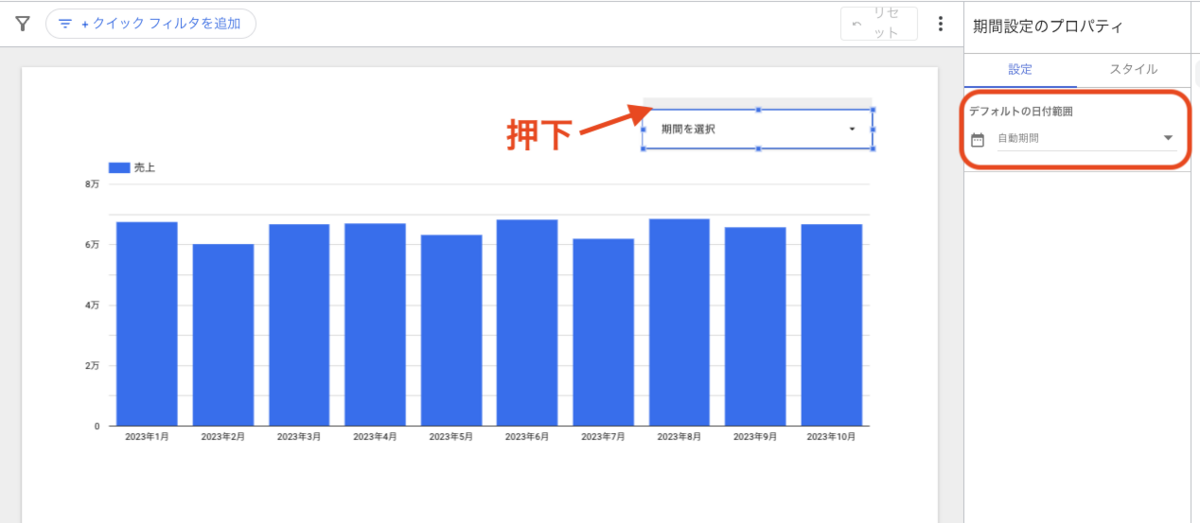
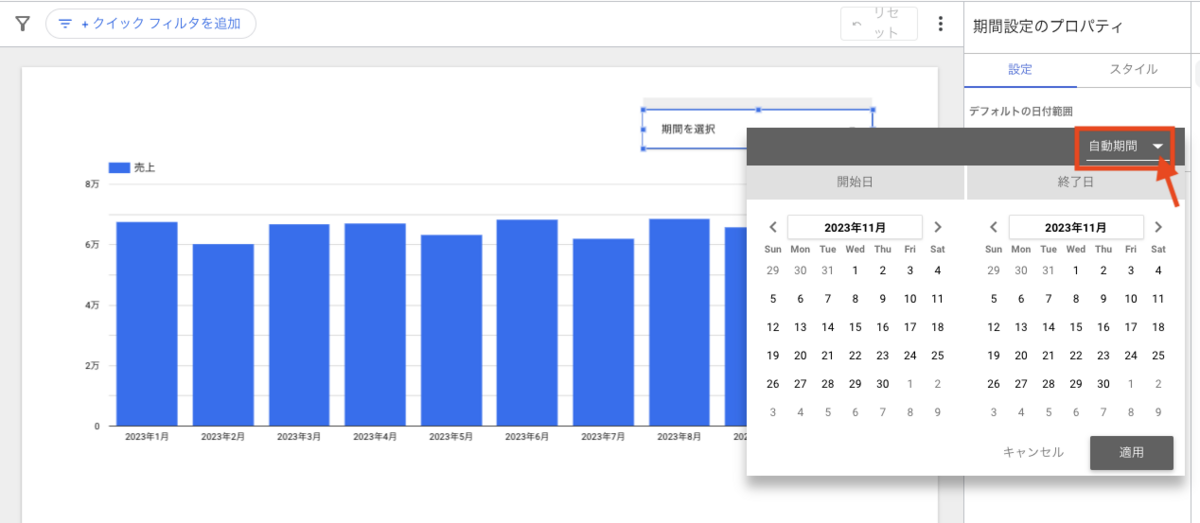
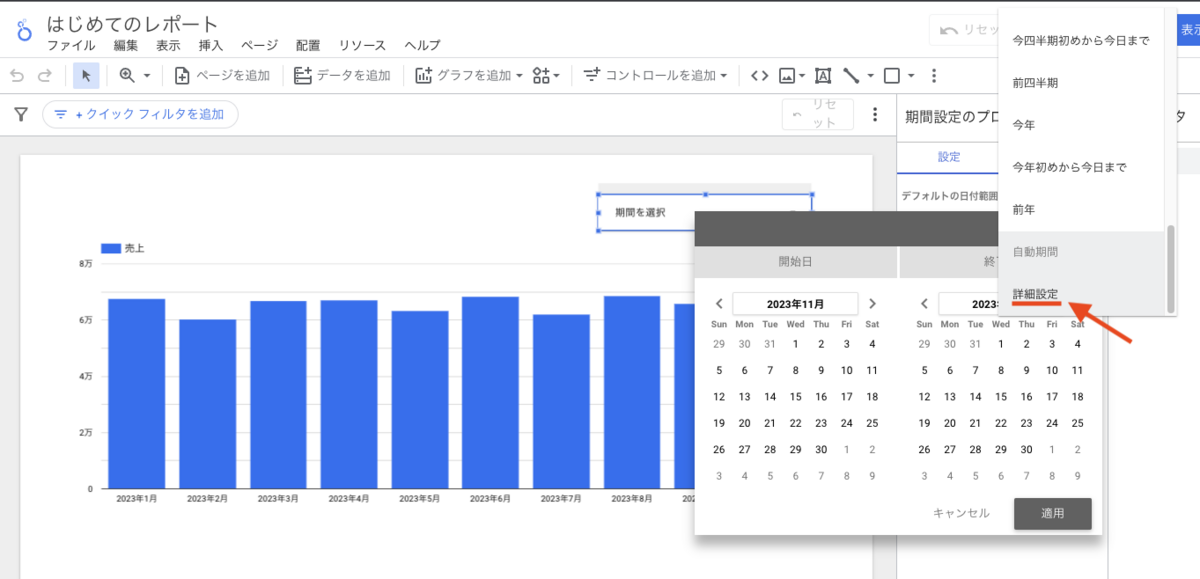
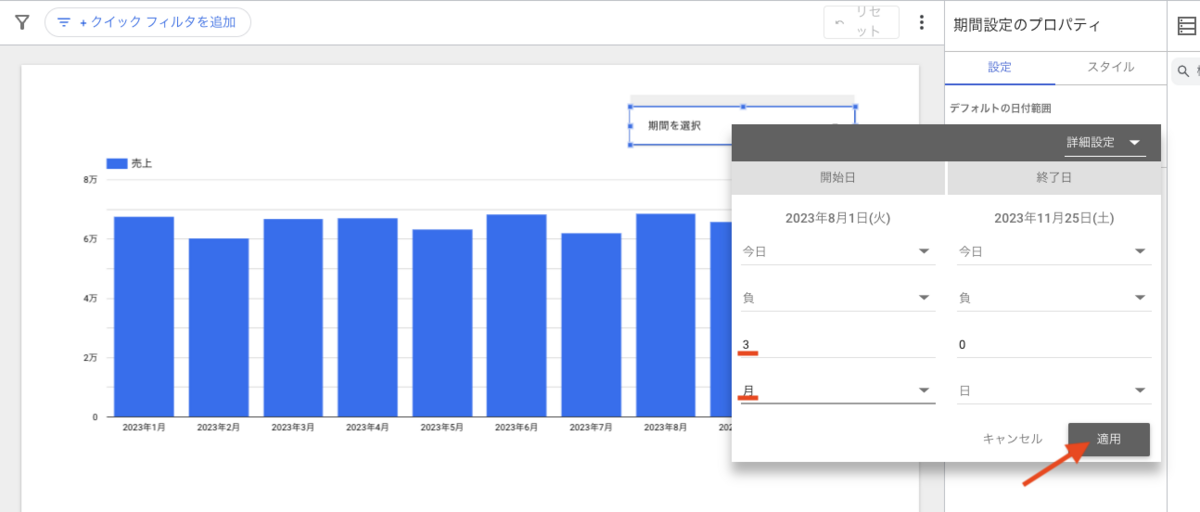
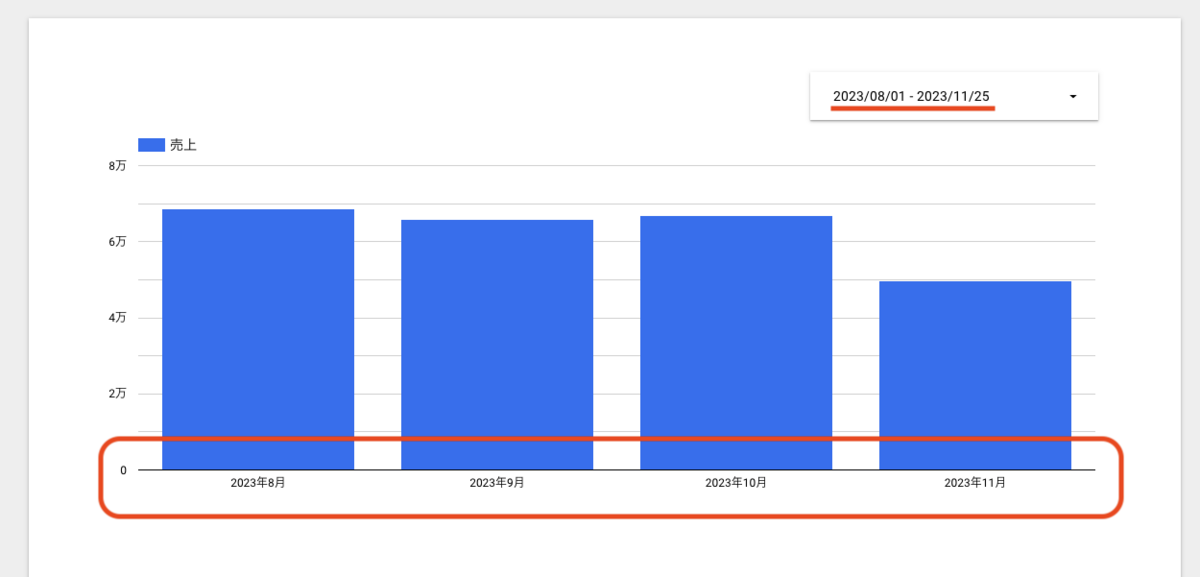
この記事は個人ブログと同じ内容です
www.ritolab.com
BigQuery
BigQueryは、Google Cloud Platform(GCP)が提供するフルマネージドのサーバーレスデータウェアハウスです。膨大な量のデータを高速に分析することが可能で、データ分析やビジネスインテリジェンス(BI)の分野で広く利用されています。
BigQuery では、データに対してクエリを実行することで、ほしいデータに絞って取得したり、集計したりなど、データを分析することができます。
BigQuery - Google Cloud
対象
本記事は、BigQuery を用いてデータの操作を行いたい人が対象です。
- 本記事はワークショップ(ハンズオン)形式で構成しており、実際に手を動かしながら、記事の通りにデータ操作を行っていくことで、BigQuery に関する基礎的な理解を深められます。
- 非エンジニアで、データ操作が初めてのひとを対象にしています。
BigQuery の料金体系と無料枠
まずはじめに大切なお金のことから。BigQuery は、全てを無料で利用できるものではありません。まずは料金体系について知っておきましょう。(本記事は無料枠内で実施します)
BigQuery の料金体系は、大きく分けて以下の2つがあります。
- ストレージ料金
- 分析料金
- クエリでスキャンされたデータに対して課金されます。
また、BigQuery には無料枠が用意されています。
つまり、10GB 以内のデータを保存し、合計 1TB 以内のクエリを実行する場合、無料枠の範囲内であれば、料金は発生しません。
(BigQuery は、デフォルトでオンデマンド分析料金が適用されます。オンデマンド分析料金は、クエリでスキャンされたデータに対して課金されます。)
BigQuery の料金 - Google Cloud
BigQuery サンドボックスで利用を開始する
Google アカウントにログインした状態で以下の URL にアクセスすると、サンドボックスモードで BigQuery を利用できます。(クレジットカードの登録不要)
https://console.cloud.google.com/bigquery
アクセス後の BigQuery コンソール画面です。
BigQuery でのデータ管理
BigQuery には、「プロジェクト」「データセット」「テーブル」という分類があり、それぞれが階層になりリソース(データ)を分類します。
これらの分類を以てリソースを管理します。プロジェクトとは、BigQuery の最も最上階の分類です。
例えば、以下のように分類を分けて、データの管理を分かりやすくしましょうというお話です。
- 練習用(プロジェクト)
- アイスクリームの売上(データセット)
- 店舗売上データ(テーブル)
- 地域天気データ(テーブル)
- 人件費データ(テーブル)
- 模試の成績(データセット)
- 学校データ(テーブル)
- 生徒データ(テーブル)
- 模試結果データ(テーブル)
プロジェクト・データセット・テーブルは複数作成できます。
なお、プロジェクトやデータセットは必須のため、データを操作する前に、これから以下の作業を行います。
- プロジェクトを作成する
- データセットを作成する
- テーブルを作成する(データのインポート)
プロジェクトを作成する
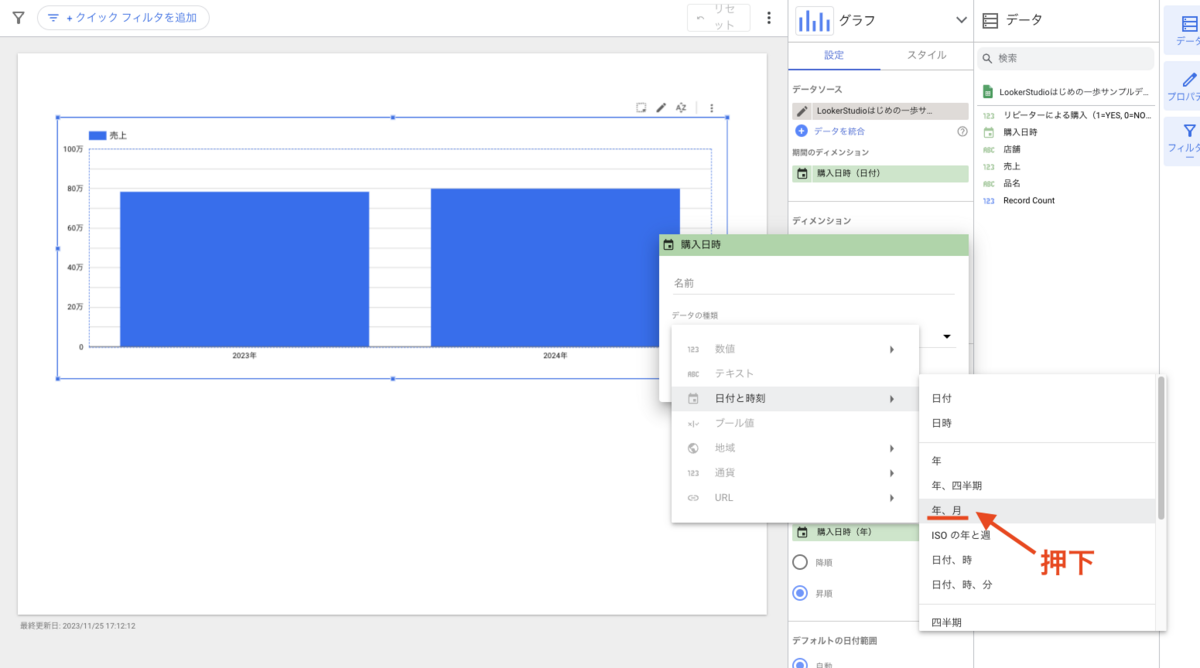
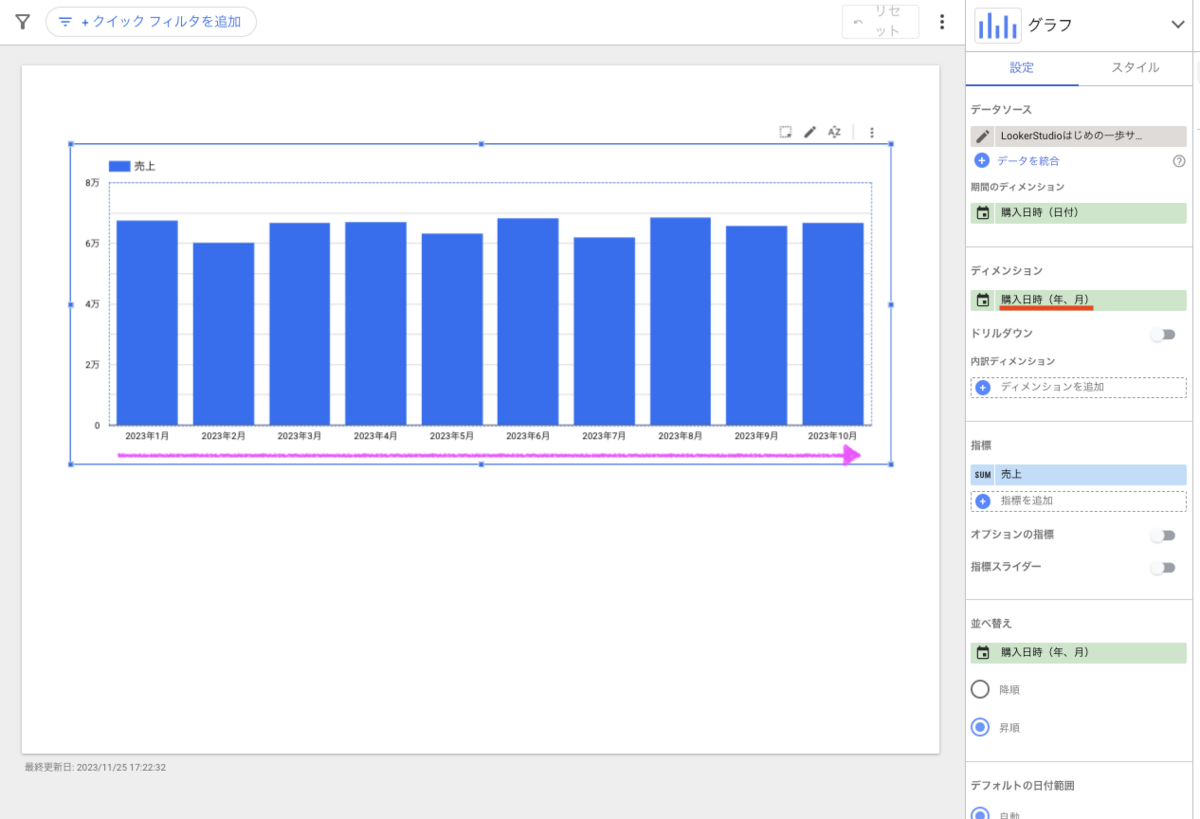
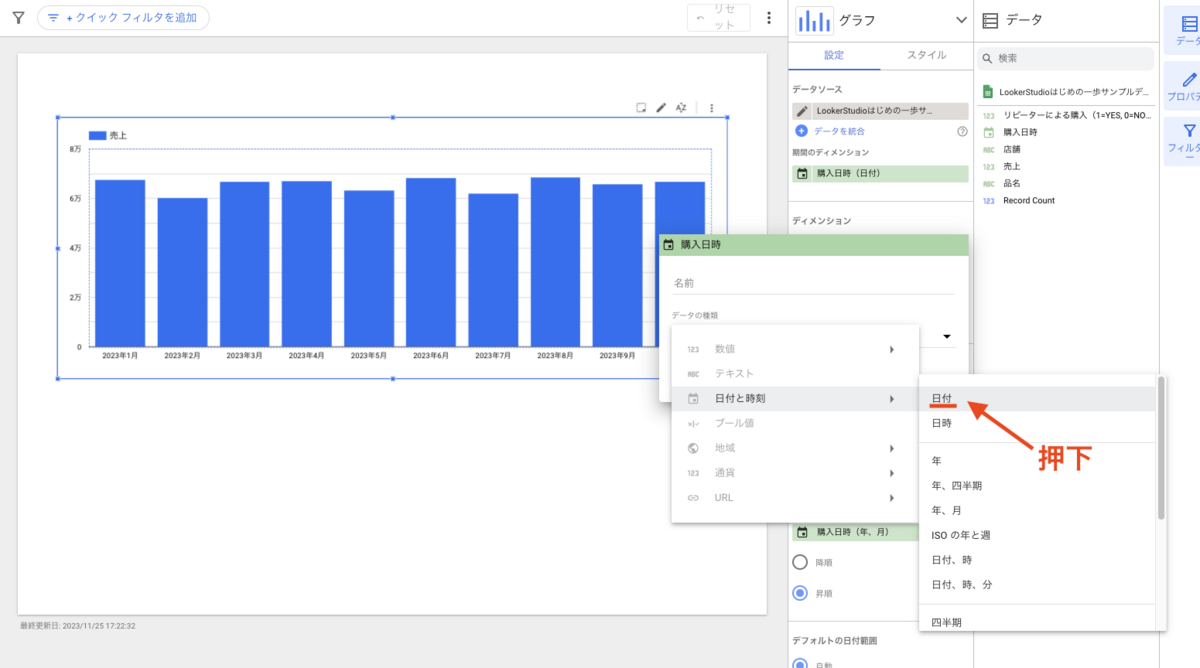
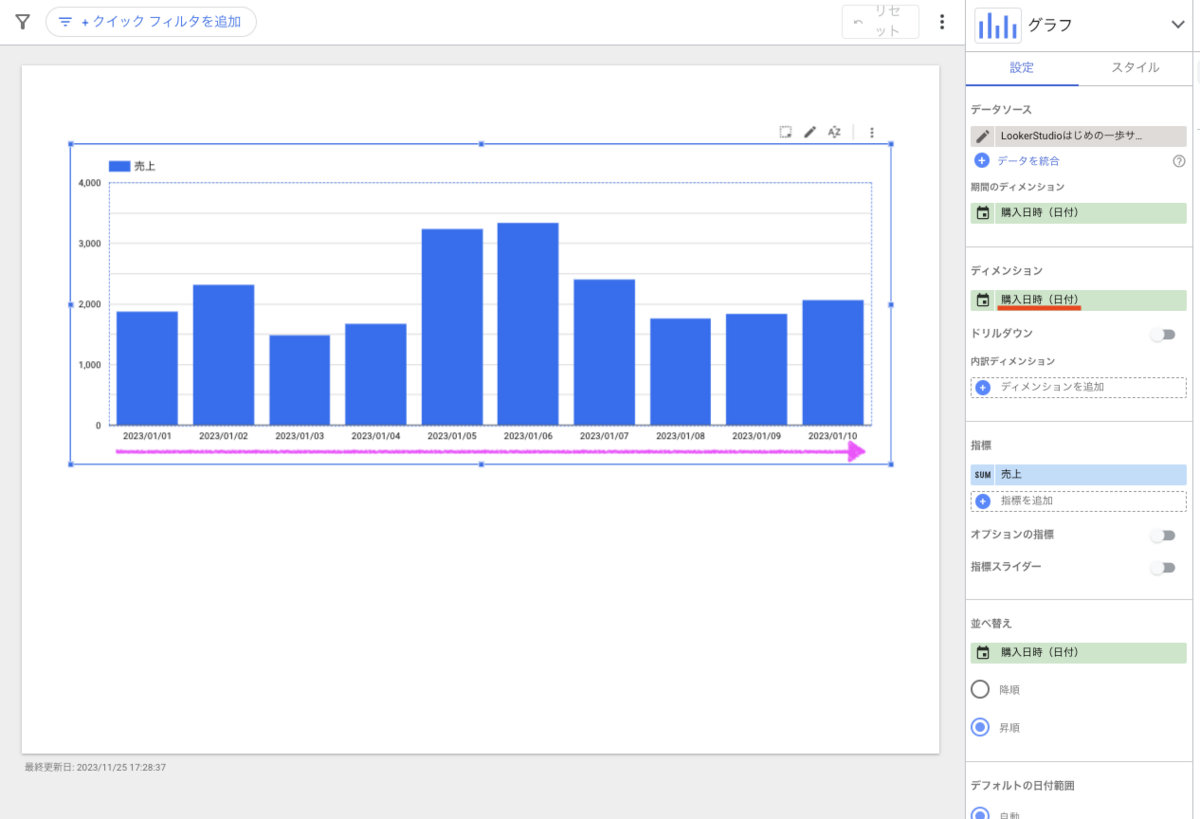
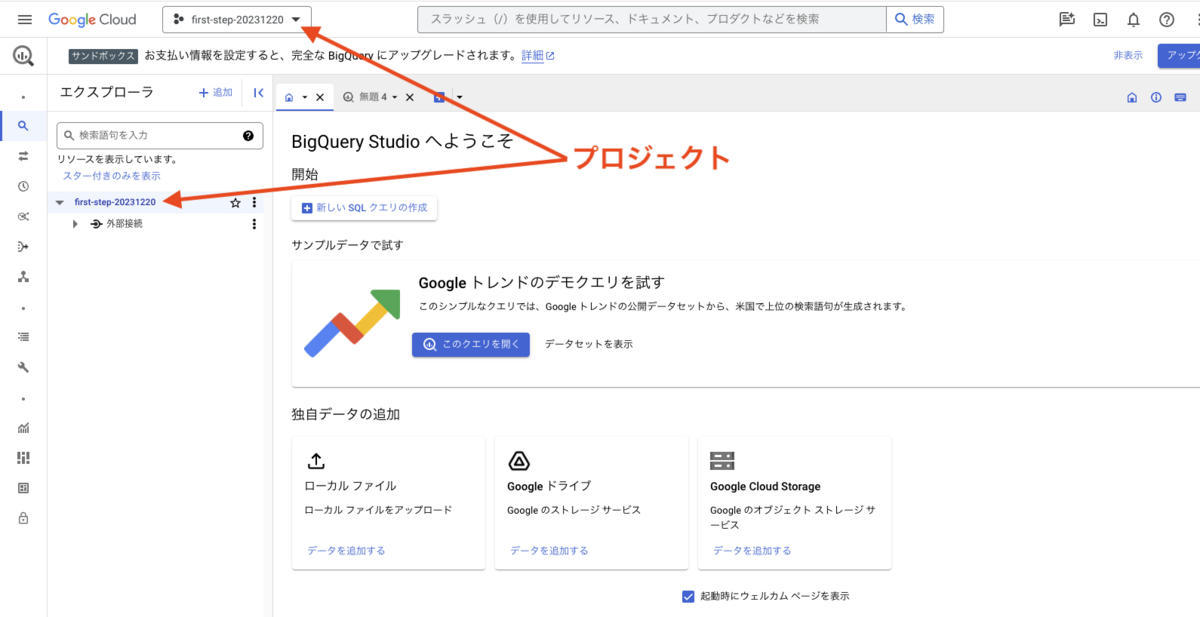
プロジェクトを作成します。[プロジェクトを作成] を押下します。
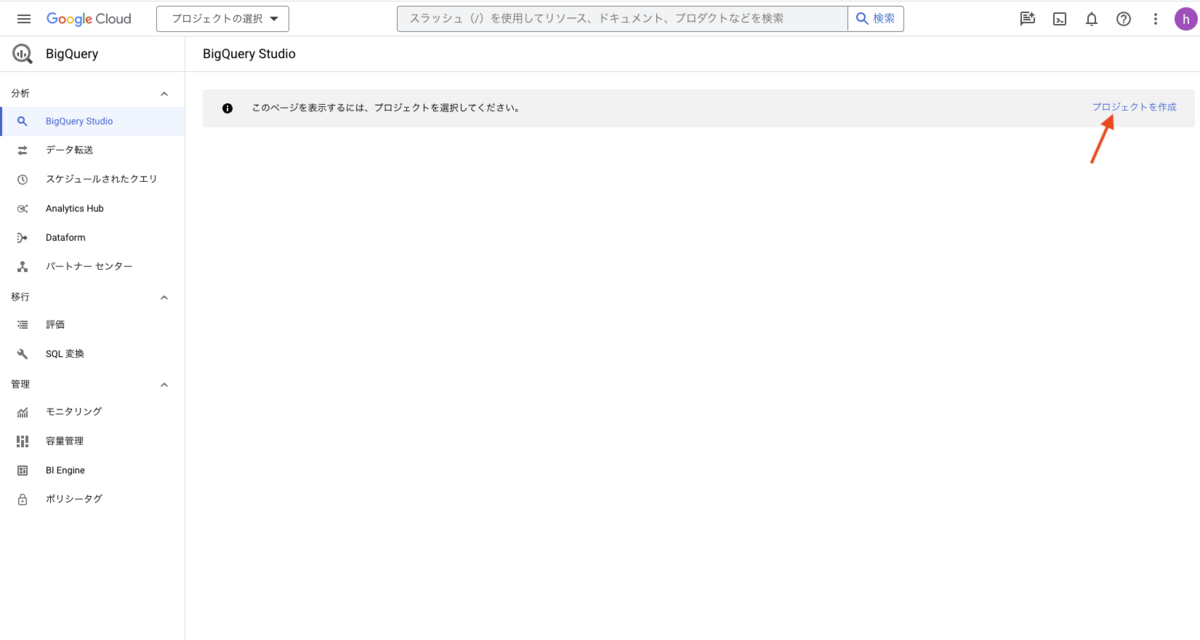
プロジェクト名には任意の名前を入力し、[作成] ボタンを押下します。
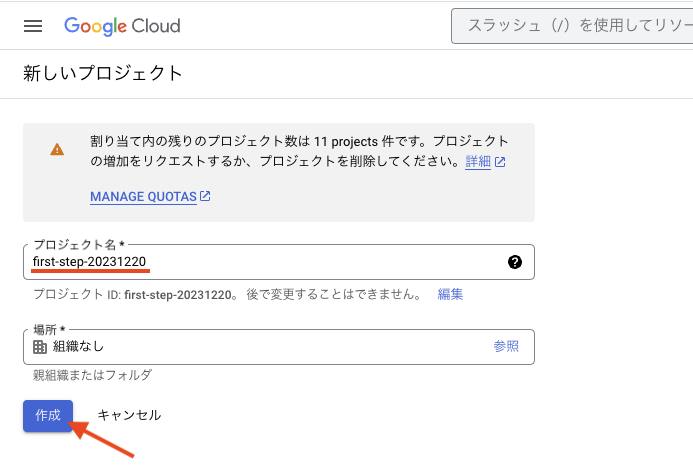
プロジェクトの作成に成功すると、BigQuery API の有効化画面に遷移するので、[有効にする] ボタンを押下して有効にします。
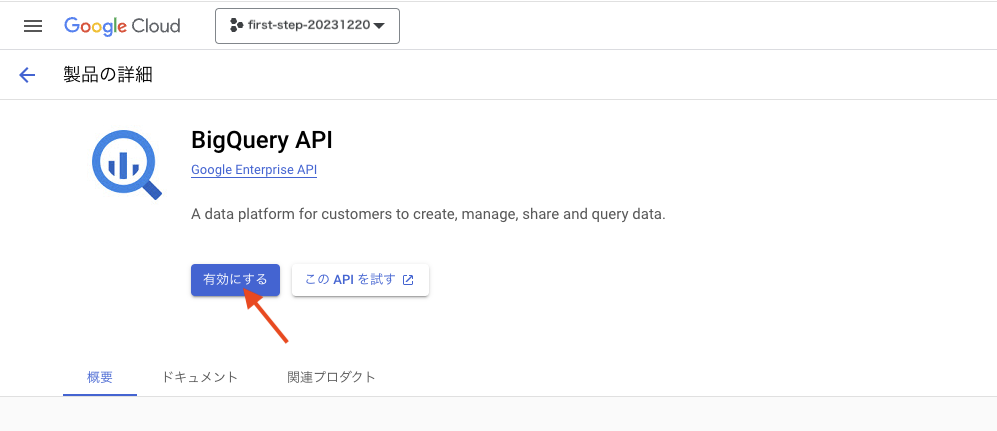
しばらくするとコンソール画面に戻ってきます。これでプロジェクトの作成は完了です。作成したプロジェクト名が表示されています。
次に、データセットを作成します。
データセットとは、これからプロジェクトの中に作成していく、いくつかのテーブル(表データ)をグループ分けするものだと考えてください。
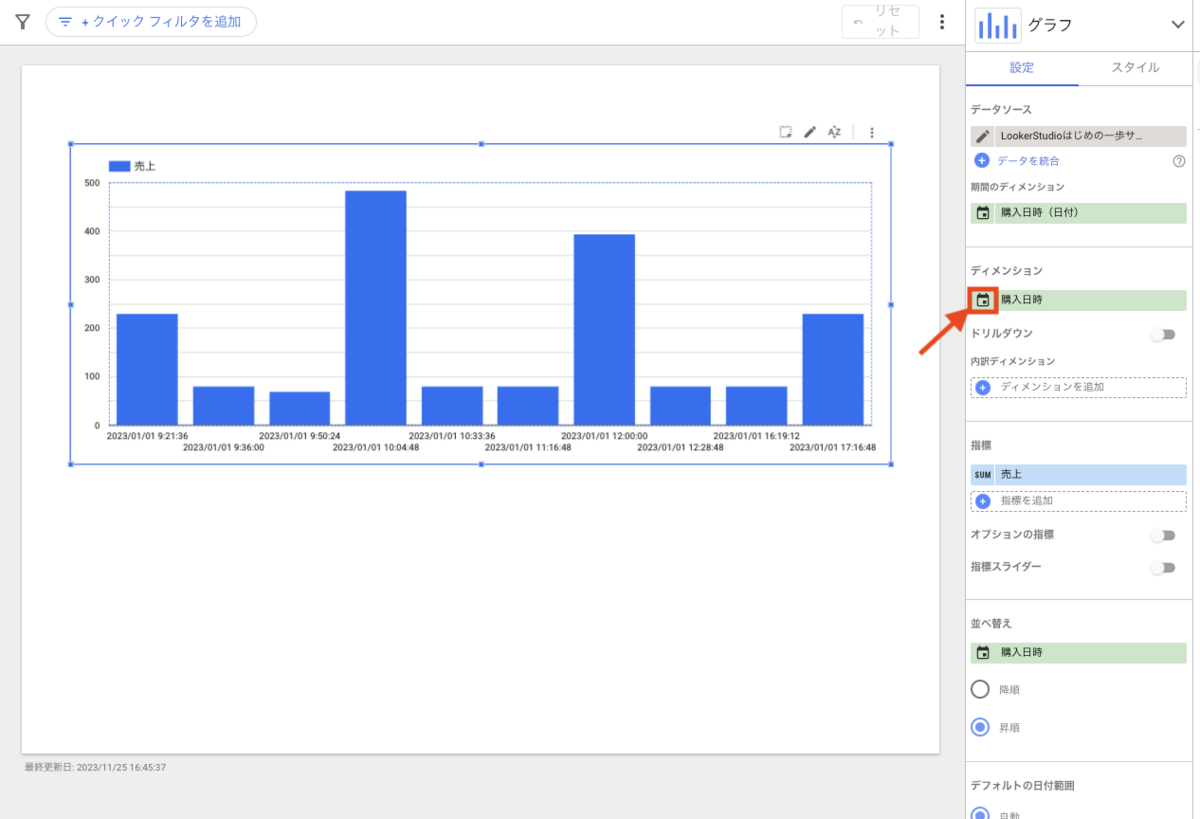
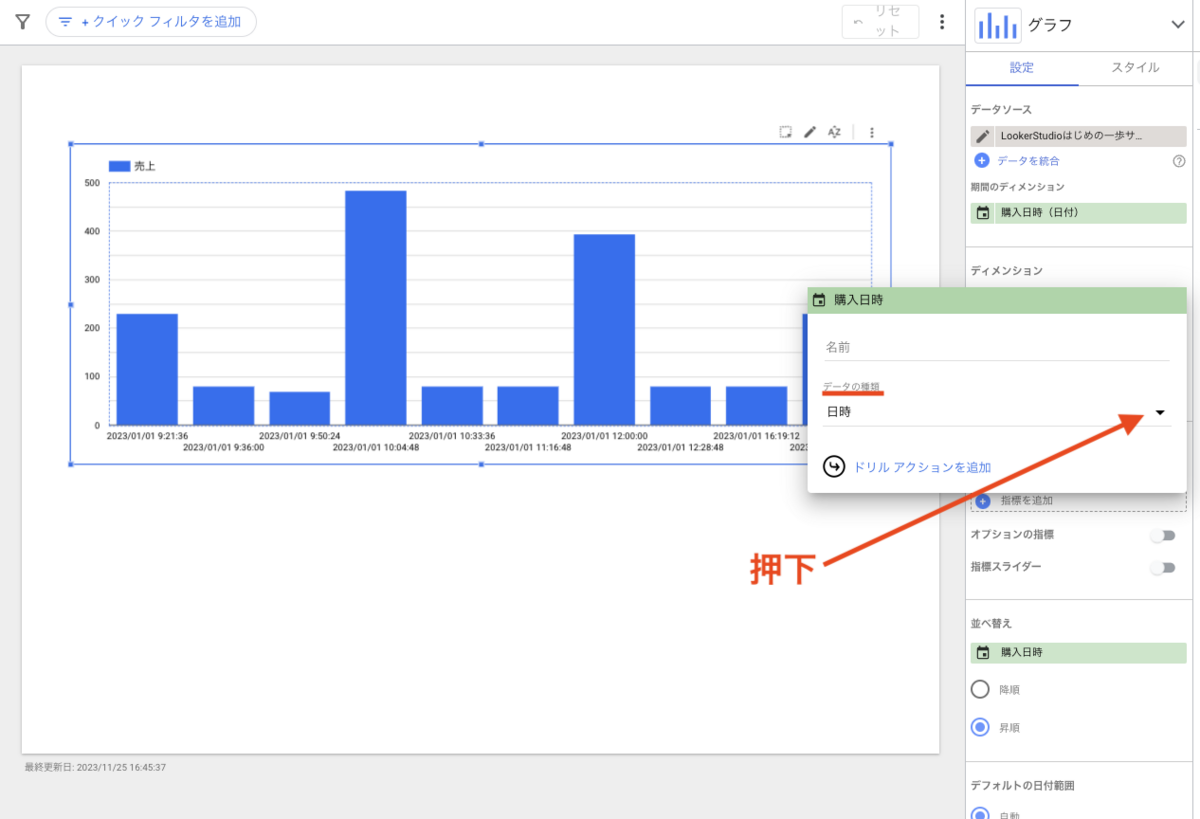
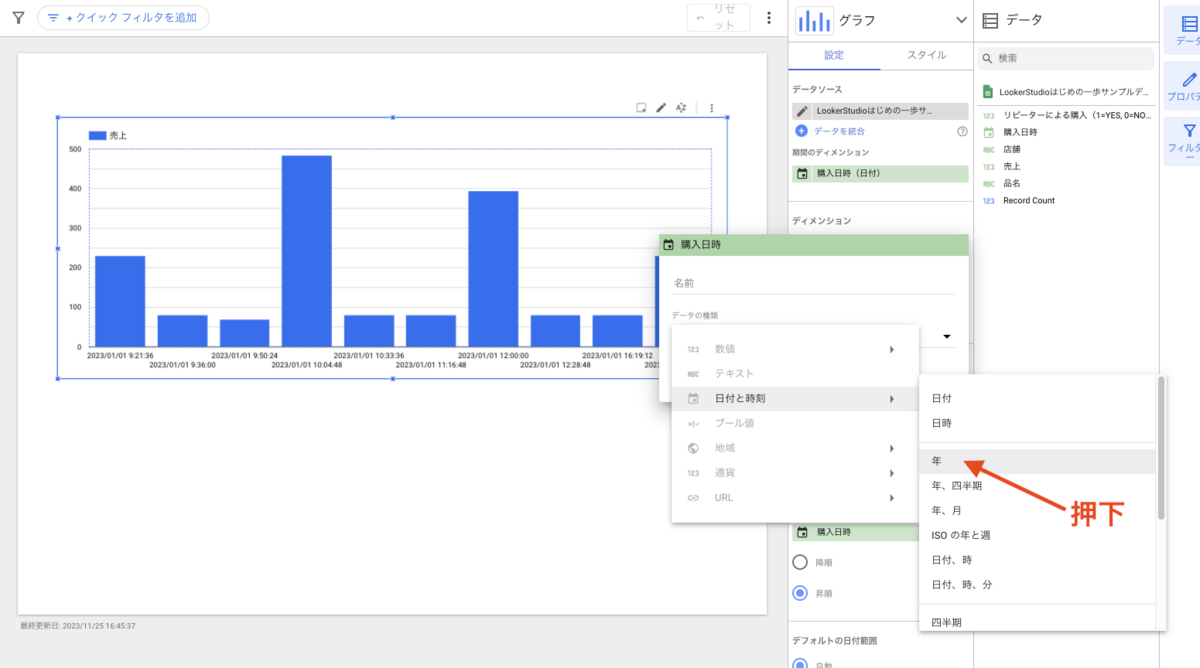
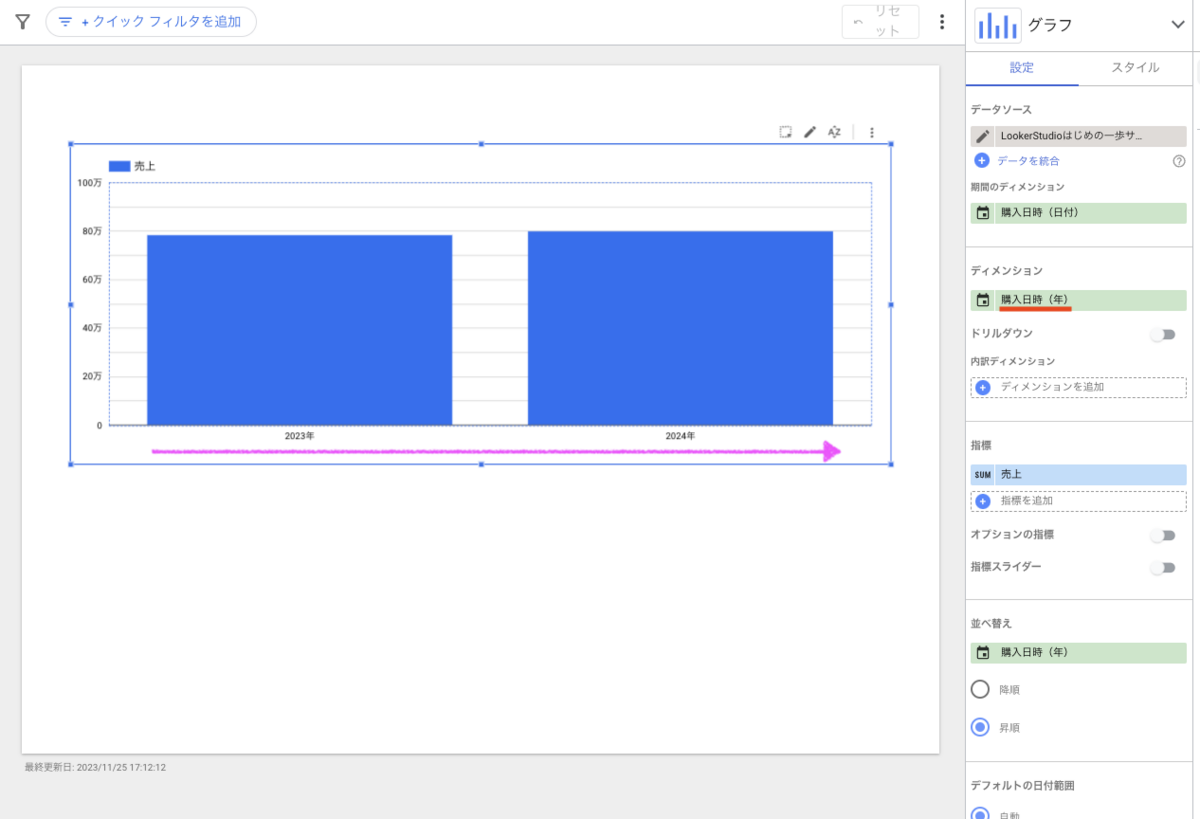
左メニューに表示されているデータセット名の左側に、三角のアイコンがあるので押下してみてください。
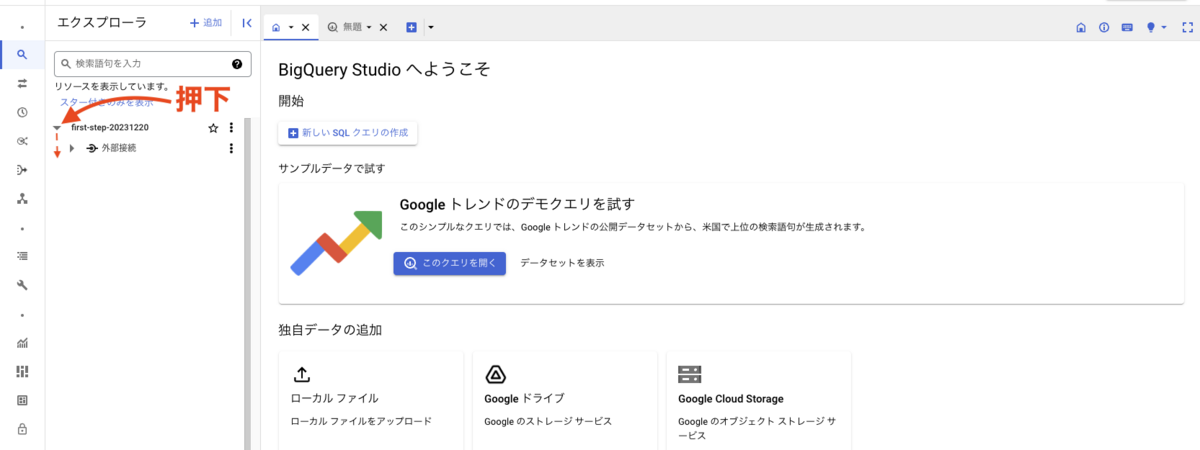
現在はまだデータセットを作成していない状態のため、プロジェクト以下を見ても「外部接続」という表示しかありません。
データセットを作成すると、ここに新しいグループが作成されます。
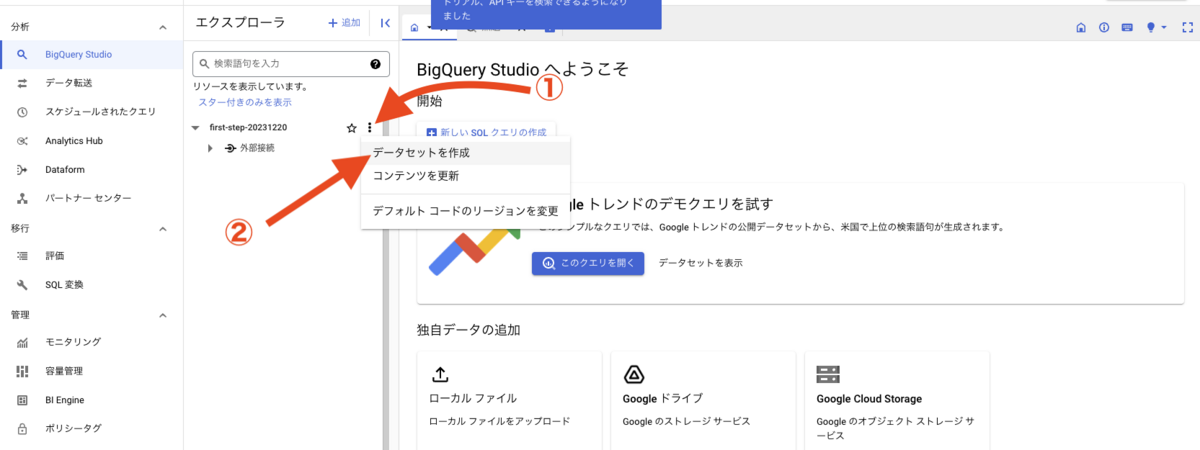
それでは、データセットを作成します。プロジェクト名の右側にある三点リーダーを押下し、表示されるメニューから「データセットを作成」を押下します。
データセット作成フォームが表示されるので、それぞれ以下のフォームに入力を行います。
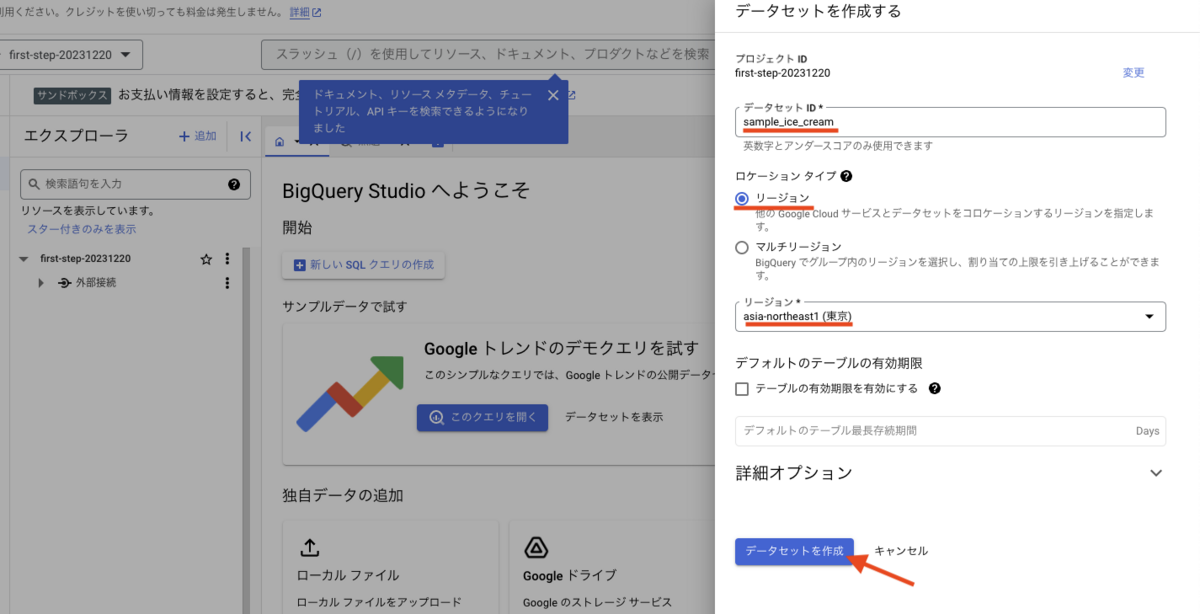
- データセット ID
- データセットの名前です。英数字とアンダースコアを使って任意の名前をつけましょう。ここでは sample_ice_cream としています。
- ロケーション タイプ
- リージョン を選択します。
- リージョン: あなたがもし日本で作業しているのならば asia-northeast1(東京) を選択します。
入力が完了したら [データセットを作成] ボタンを押下します。
作成が完了すると、プロジェクト配下にデータセットが表示され、新たなデータセットが作成されたことを確認できます。
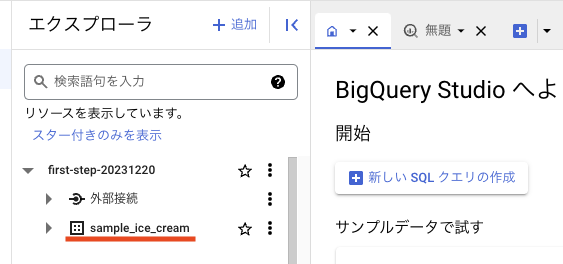
これでデータセットの作成は完了です。
テーブルを作成する(データのインポート)
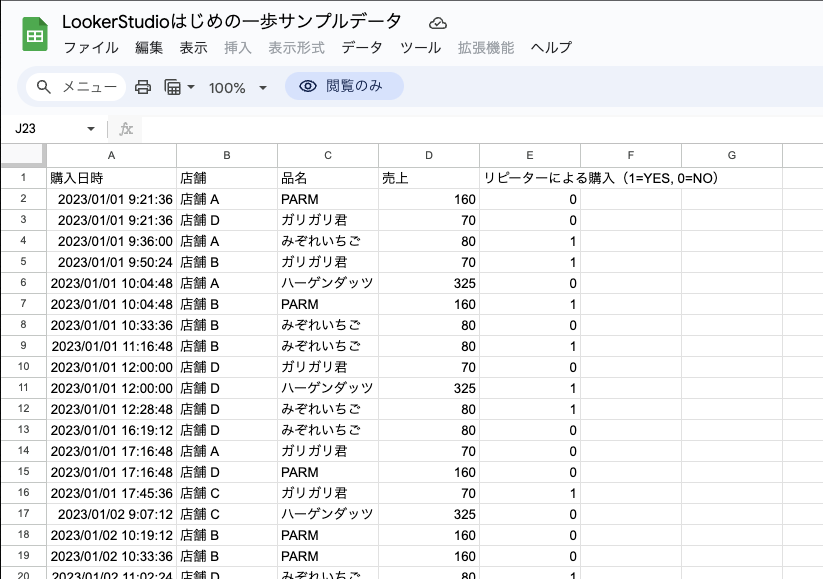
分析する対象となるデータをインポート(読み込み)し、テーブルを作成してみましょう。テーブルとは、例えばスプレッドシートやエクセルでいうところの表データです。
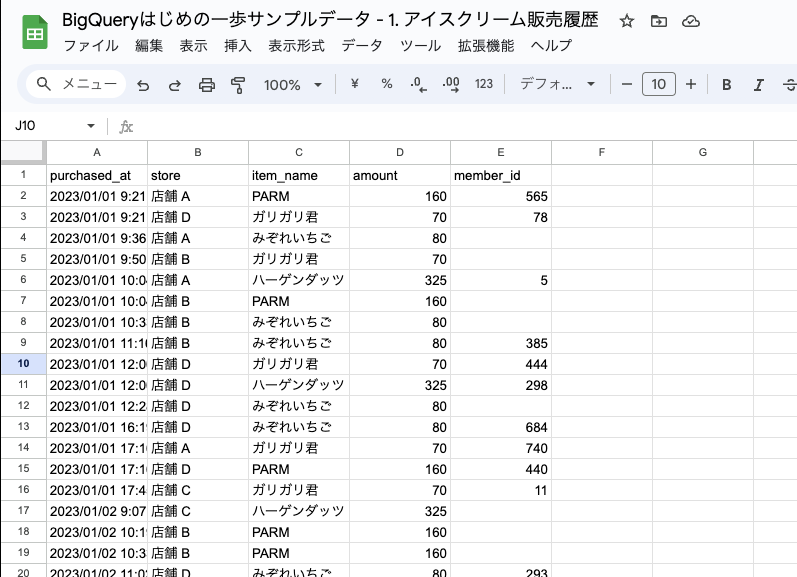
データを読み込みテーブルを作成すると、上のキャプチャ画像のスプレッドシートのように、行と列で構成されたデータがそのまま BigQuery のデータベース上に入るとイメージしてください。
練習用データ
今回使用するのは、練習用のデータとして作成した「とある店舗でのアイスクリーム販売履歴」です。
データ概要
- データ日時範囲:
- 2023/01/01 〜 2024/12/31 までの 2 年間
- データ件数:
- カラム(列)
- purchased_at: 購入日時
- store: 店舗
- item_name: 品名
- amount: 金額
- member_id: ポイントメンバー会員 ID
練習用データは公開しているので誰でもアクセスできます。
BigQueryはじめの一歩サンプルデータ - 1. アイスクリーム販売履歴(スプレッドシート)
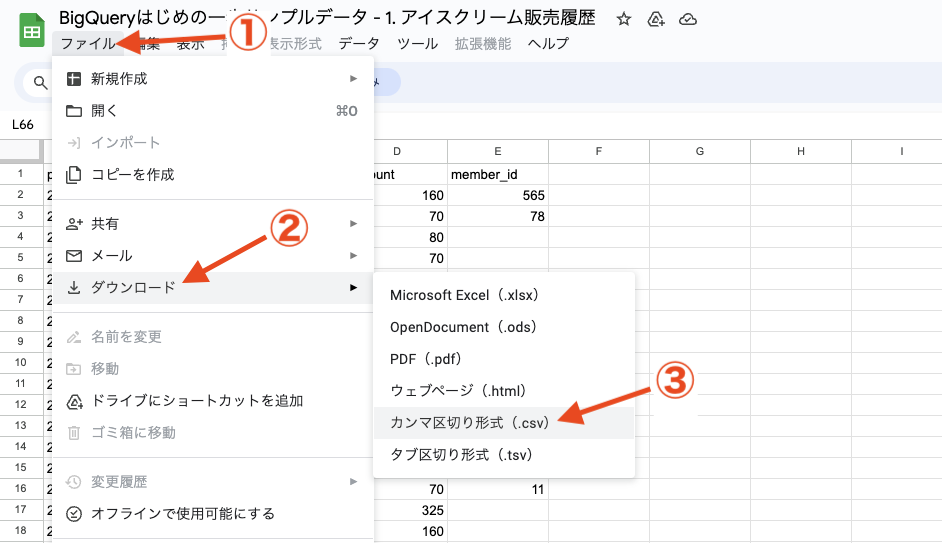
データの読み込みは CSV ファイルで行いますので、練習用データのスプレッドシートを CSV ファイルとしてダウンロードしてください。
ファイル > ダウンロード > カンマ区切り形式(.csv)
テーブル作成
それではデータをインポートしテーブルを作成します。
コンソール画面「独自データの追加」から「ローカル ファイル」にある [データを追加する] を押下します。
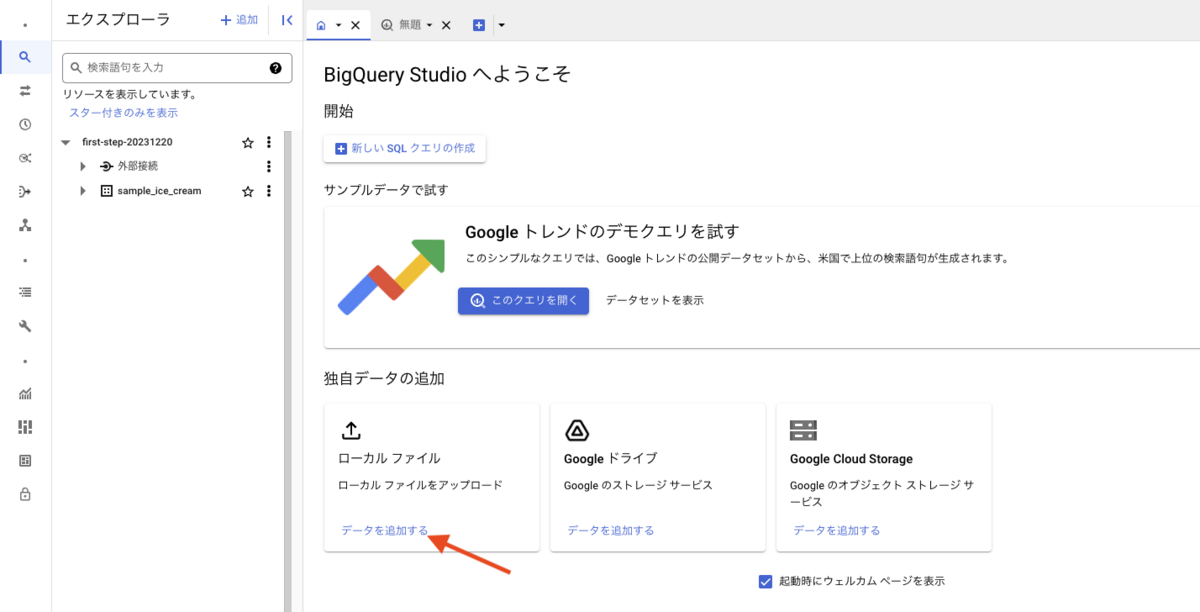
テーブル作成フォームが表示されるので、それぞれ以下のフォームに入力を行います。少し入力が多いですが頑張ってください。

- ファイルを選択
- ダウンロードした練習用 CSV ファイルを選択します。
- ファイル形式
- ファイルを選択すると自動的に CSV になります。CSV にならない場合は選択してください。
- データセット
- 先程作成したデータセット名を入力します。ここでは sample_ice_cream としています。
- テーブル
- 読み込むデータの名前です。英数字とアンダースコアを用いて任意の名前をつけましょう。アイスクリームの販売履歴なので、ここでは ice_cream_sales としています。
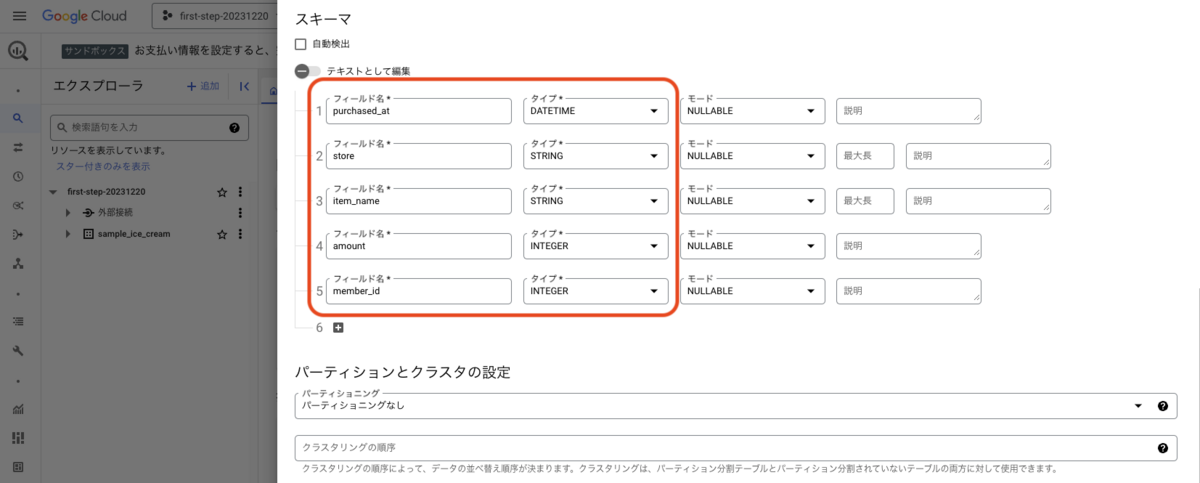
- スキーマ
- 以下を入力しましょう。モードと説明はデフォルトのままで構いません。
- [1] フィールド名: purchased_at, タイプ: DATETIME,
- [2] フィールド名: store, タイプ: STRING,
- [3] フィールド名: item_name, タイプ: STRING,
- [4] フィールド名: amount, タイプ: INTEGER,
- [5] フィールド名: member_id, タイプ: INTEGER,
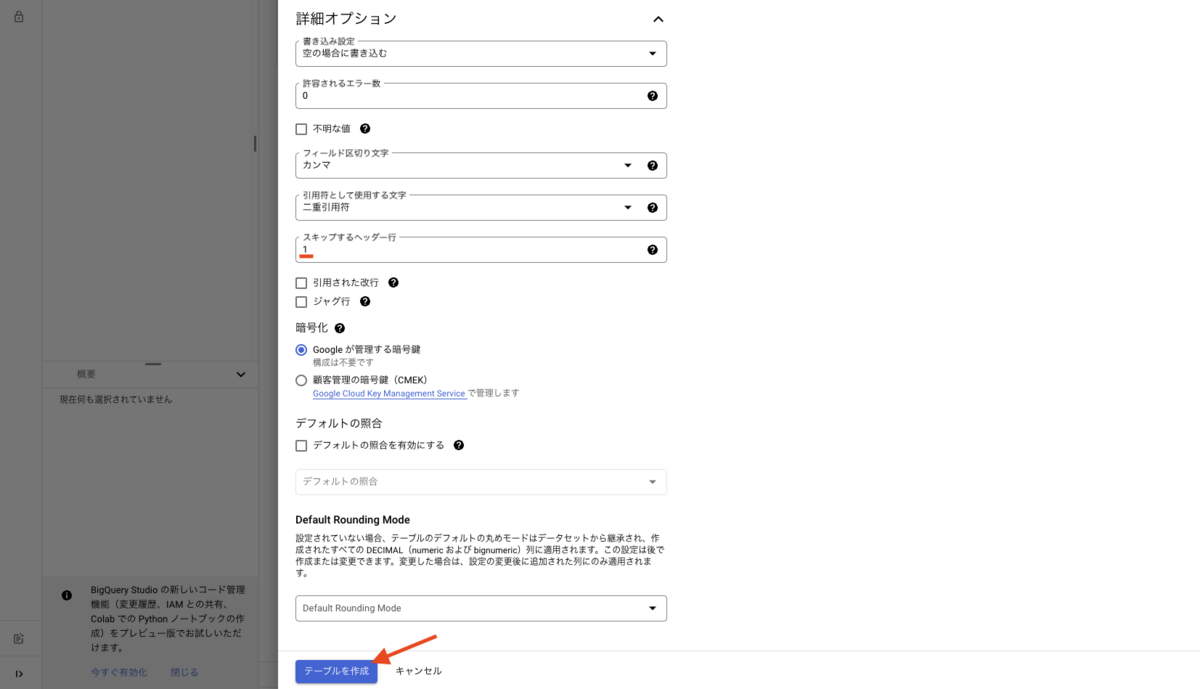
- 詳細オプション
- スキップするヘッター行
- 練習用データの先頭行にはカラム(列)名が入っているため、1 を入力します。
全て入力できたら、[テーブを作成] ボタンを押下します。
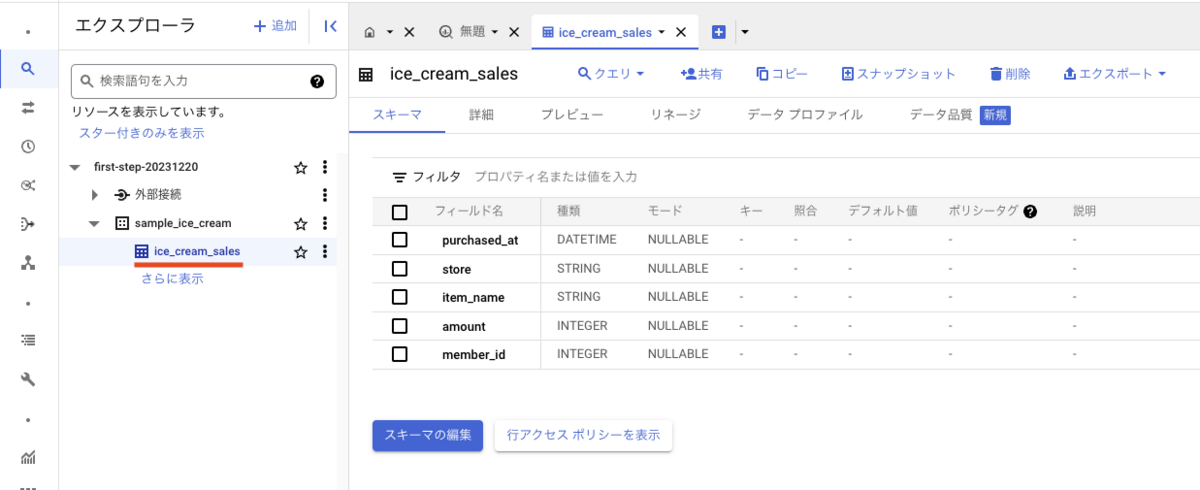
テーブルの作成が完了すると、BigQuery コンソール画面にテーブルが表示されます。sample_ice_cream データセット配下に、ice_cream_sales テーブルが作成されたことが確認できます。
プレビューというタブを押下すると、ice_cream_sales テーブルに入っているデータを確認できます。
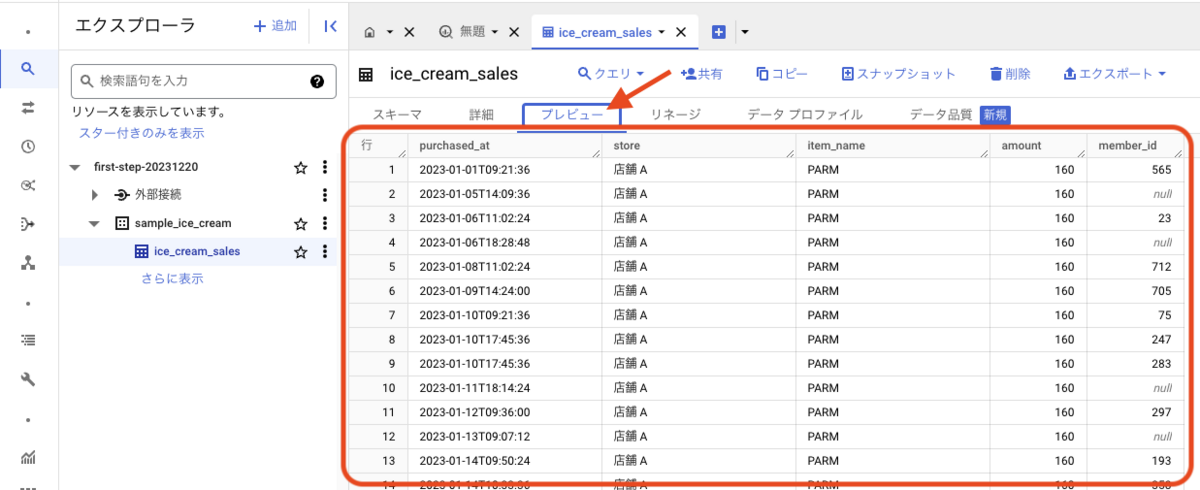
これでテーブルの作成(データのインポート)は完了です。
次の章から、実際にクエリを実行してみましょう。
データベースと会話する
これは先程作成した、アイスクリームの販売履歴のテーブルのデータです。
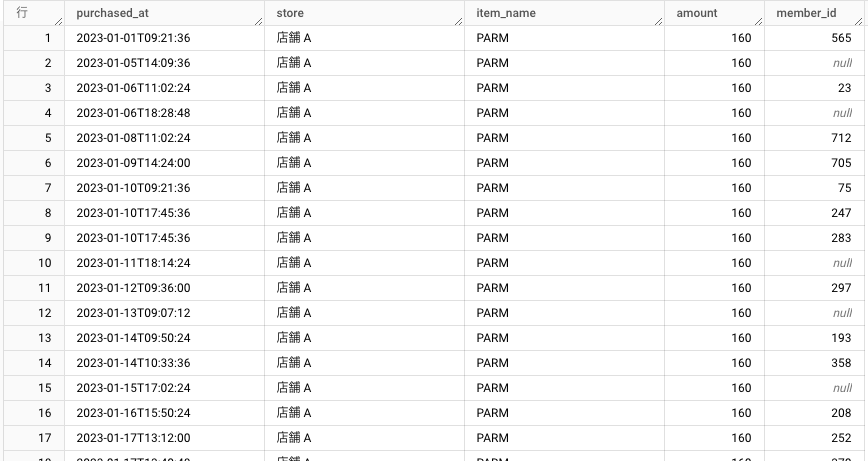
こういった、スプレッドシートやエクセルのように、行と列で構成されるテーブルを持つデータベースを「リレーショナルデータベース」と呼びます。
リレーショナルデータベースの詳細についてはここでは重要ではないので割愛します。
そして文字が長いので、本記事では「リレーショナルデータベース」を「データベース」と呼ぶことにします。
データベースの種別はリレーショナルデータベース以外にも存在しますが、本記事で「データベース」と言ったらリレーショナルデータベースのことだと思ってください。
さて。
BigQuery に限らず、データベースからほしいデータに絞ってを取得したり、データを集計したりなど加工したりするには、SQL という言語を使います。
日本人と会話するなら日本語、英語圏の人と会話するなら英語。のように、データベースと対話するなら SQL といったイメージです。
SQL を使えばデータベースと会話ができて、データベースが応答してくれます。
あなた: 「あのデータをちょうだい(SELECT id, name FROM my_table ORDER BY id DESC LIMIT 100)」
データベース: 「はい、これですよ(id, mane, 1, xxx, 2 ,xxx ,...)」
あなた: 「このデータをあのテーブルにしまっておいて(INSERT my_table (id, name) VALUES (123, xxx))」
データベース: 「はい、テーブルにレコードを追加しました(Query OK, 1 row affected)」
SQL とは、Structured Query Language(構造化クエリ言語)の略称で、データベースを操作するための言語です。
SQL を使えば、データベースにデータを追加したり、データを変更したり、データを検索したりすることができます。
データベースには様々な製品があり、BigQuery もその 1 つです。代表的なものだと他には、MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server などがありますが、これらを操作するための言語のベースは全て SQL です。
データベースを操作する上で SQL は共通言語であり、その上で、各データベース製品によって若干文法が違ったりします。
つまり、SQL を覚えれば、あとは各データベース製品ごとの書き方のお約束を知るだけで、BigQuery でも MySQL でも操作できるようになります。
SQL を「言語」とするならば、各データベース製品ごとの文法の違いは「方言」のようなものだと思ってください。
SQL の文法はシンプルです。データを取得する時の基本的な文法は以下になります。
SELECT
見たい列の名前 1,
見たい列の名前 2,
見たい列の名前 3,
FROM テーブル名
;
SELECT 句は、データを取得する際の構文です。見たいカラム(行)を指定して、それらをどのテーブルから取得するのかを FROM 句で指定してあげるだけです。
SELECT
purchased_at,
store
FROM ice_cream_sales
;
上記のように、見やすいように改行しても良いし、1 行で書いても同じことです。
SELECT purchased_at, store FROM ice_cream_sales;
この構文をベースとして、あとは並び順を変えたり、条件によってデータを絞ったり、集計したりできます。この辺りは実際に BigQuery でクエリ(こういった SQL で作成した文)を実行していきながら見ていきましょう。
データを取得する(基本)
それでは実際に、BigQuery でクエリを実行しデータを取得してみましょう。
タブの右側に [+] のボタンがあるので押下してください。
「無題」というタブが作成されます。ここにクエリを書いて実行していきます。
データの確認
クエリを書く前に、再度、アイスクリームの販売履歴のテーブルのデータを確認をしましょう。
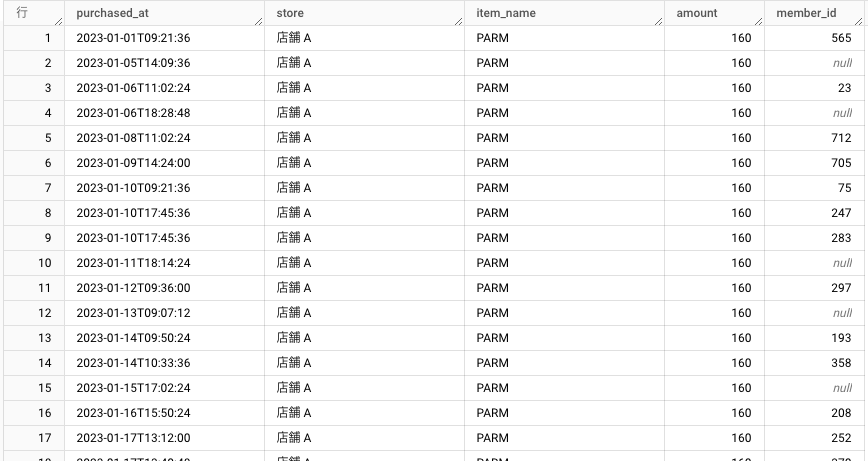
- データセット名: sample_ice_cream
- テーブル名: ice_cream_sales
それぞれのカラム(列)の意味するものは以下でしたね。
- purchased_at: 購入日時
- store: 店舗
- item_name: 品名
- amount: 金額
- member_id: ポイントメンバー会員 ID
これからこのデータを使って、見たい情報だけに絞ったり、並び順を変えたり、集計したりをしていきます。
基本の取得
まずは、条件など無しに、シンプルにデータを取得してみましょう。BigQuery での取得のお作法は以下になります。
SELECT
見たい列の名前,
FROM `プロジェクト名.データセット名.テーブル名`
FROM 句は、以下のどちらかで記述しテーブルを指定する必要があります。
プロジェクト名まで書くと長いので、`データセット名.テーブル名` で FROM 句を書く書き方でクエリを作成してみましょう。
SELECT
purchased_at,
store,
item_name,
amount,
member_id,
FROM `sample_ice_cream.ice_cream_sales`
;
これを、先程の「無題」のタブにあるエディターに記述します。
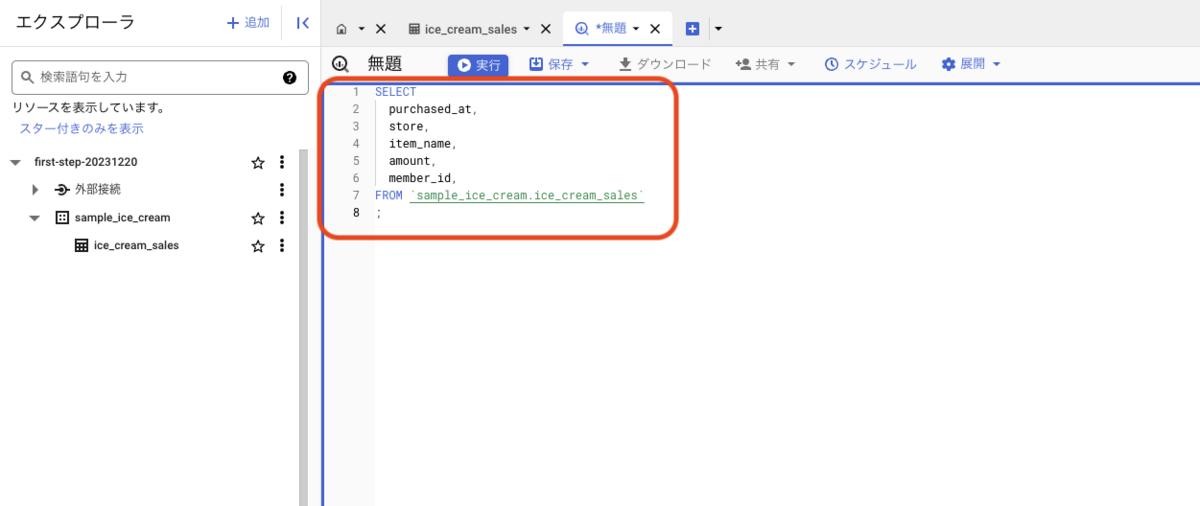
記述できたら、上にある [実行] ボタンを押下してクエリを実行してみましょう。
上手くいけば、クエリ結果としてデータが返ってくるはずです。
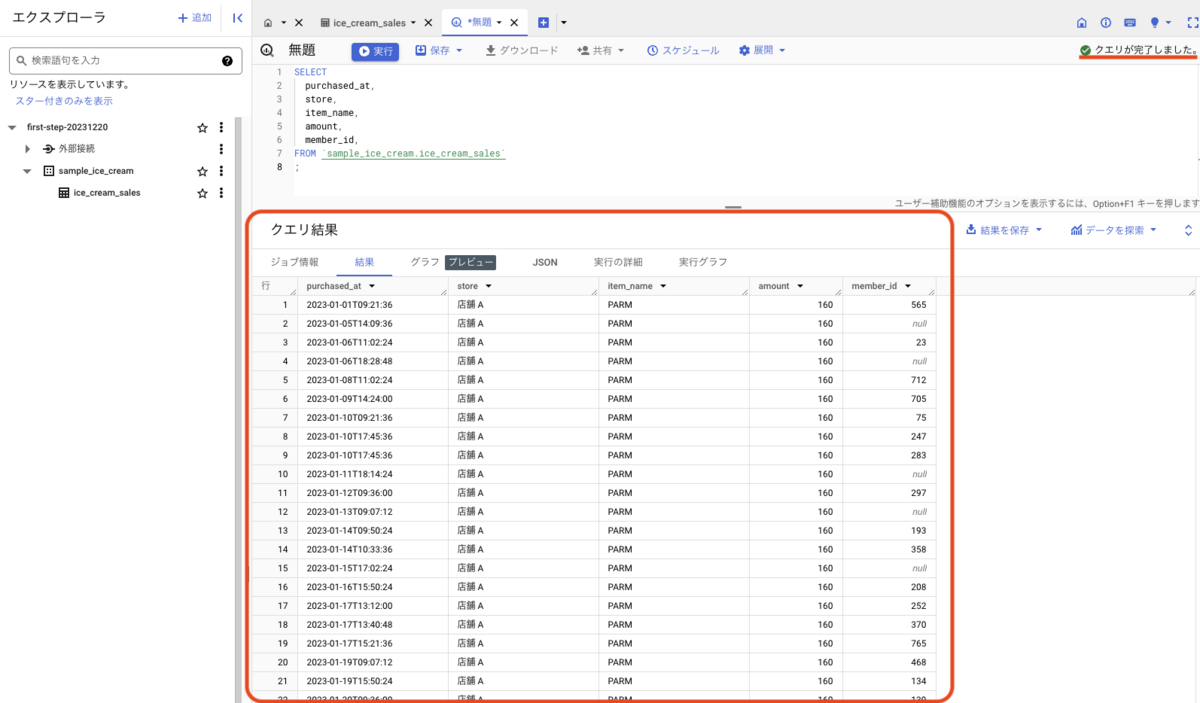
おめでとうございます。あなたは今、BigQuery でクエリを実行してデータを取得することができました。
覚えておきたいお金のこと
さて、無事に最初のクエリを実行できました。ここで一度、BigQuery での課金についておさらいしておきましょう。
BigQuery の料金体系は、大きく分けて以下の2つがあります。
- ストレージ料金
- データの保存量に対して課金されます。
- 分析料金
- クエリでスキャンされたデータに対して課金されます。
また、BigQuery には無料枠が用意されています。
- ストレージ料金
- 10GB まで無料
- 分析料金
- 毎月 1TB まで無料
つまり、10GB 以内のデータを保存し、合計 1TB 以内のクエリを実行する場合、無料枠の範囲内であれば、料金は発生しません。
(BigQuery は、デフォルトでオンデマンド分析料金が適用されます。オンデマンド分析料金は、クエリでスキャンされたデータに対して課金されます。)
先ほど行った「クエリを実行する」という行為は、上記の「分析料金: クエリでスキャンされたデータに対して課金されます。」に該当します。
そしてそれは、毎月 1TB まで無料ということになっています。
ここで、先程のエディターに記述したクエリをカットアンドペーストして貼り付け直してみてください。エディターの右上にこんな表示が出てきます。

このクエリを実行すると、461.8 KB が処理されます。
この、461.8 KB が、今回のクエリでスキャンされたデータ量です。
1TB は 1024 GBですから、1 回の実行で 461.8KB を消費する場合、このクエリを約 2200 回程度実行出来ることになります。
そしてこれは、テーブルに収録されているデータ量が増えれば、その分スキャンするデータ量も増えていくことになります。
本記事はサンドボックスモードにて、課金されない範疇で実施するので基本的には問題はありませんが、例えば自身の所属企業の BigQuery などで大量のデータを取り扱っている場合は、特にスキャン量と課金額には注意してください。(不安な場合は管理者に聞いてみましょう)
費用の見積もりと管理 - BigQuery, Google Cloud
データを取得する(色々な取得)
ではここから、アイスクリーム販売履歴データについて、色々な側面からクエリを実行しデータを取得してみましょう。
なお、ここから紹介する文法は BigQuery に限らず、他のデータベース製品でも共通で使えるものです。(BigQuery 独自の記法は随時お知らせします)
絞り込み(WHERE)
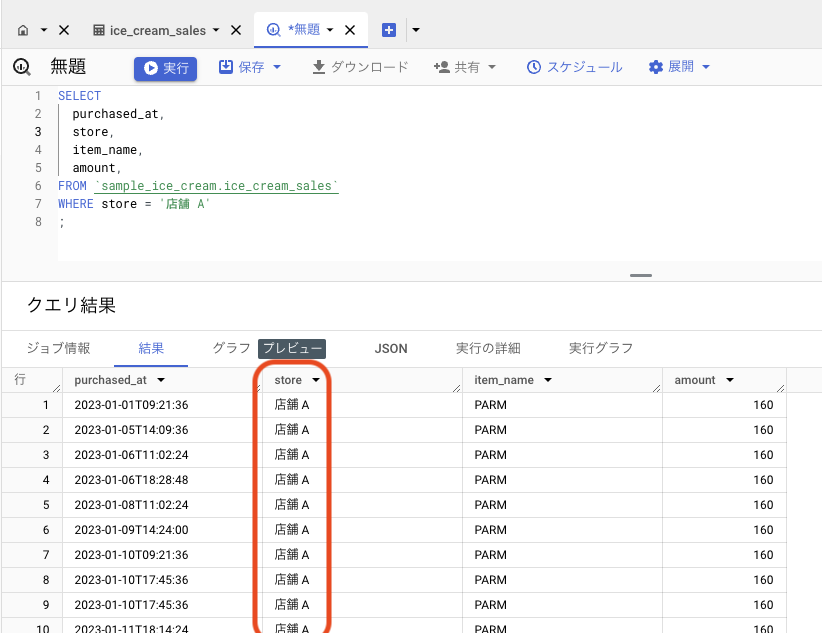
このデータは、店舗 A, B, C, D の 4 店舗分のデータが入っています。店舗 A の売上のみを見てみたい場合は WHERE 句を使ってデータを絞り込みます。
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
;
BigQuery コンソール画面のエディターに入力して実行してみましょう。店舗 A のデータのみが取得できます。
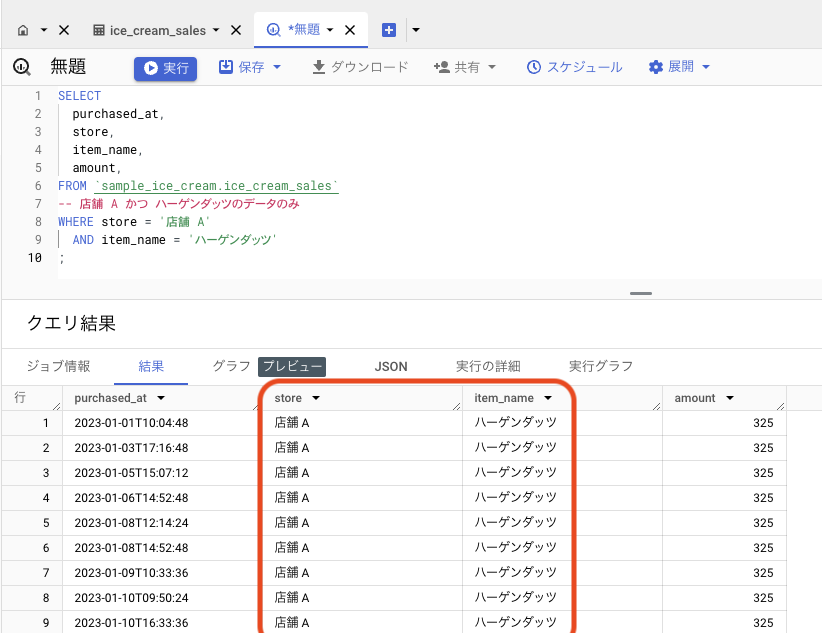
絞り込みは複数指定できます。これに、商品名「ハーゲンダッツ」も追加してみましょう。WHERE 句に AND をつけてつけて追加します。
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
AND item_name = 'ハーゲンダッツ'
;
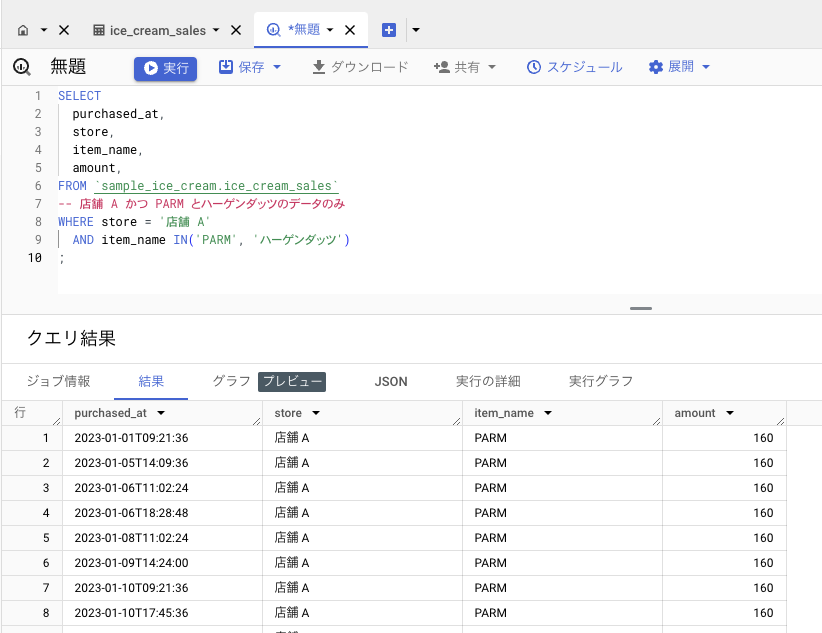
「商品は PARM とハーゲンダッツ」といった、1 つのカラムに対する複数の絞り込みには IN が使えます。
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
AND item_name IN ('PARM', 'ハーゲンダッツ')
;
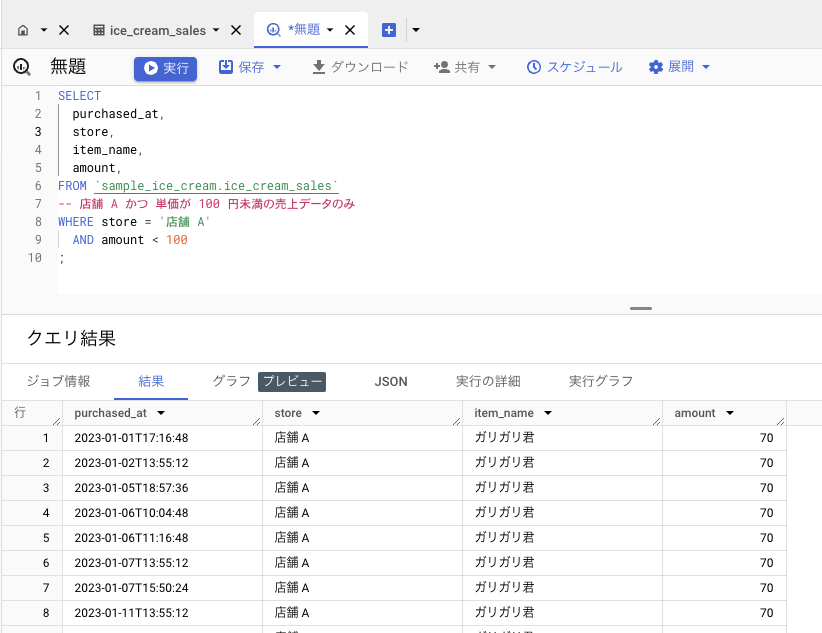
最後は、店舗 A の、単価が 100 円未満の売上データを出してみます。
「店舗 A である」は等号(=)を使うのに対して、「100 円未満である」は不等号(>, <)を用います。
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
AND amount < 100
;
このように、WHERE 句を使うと様々な絞り込みができます。(他にも WHERE を使った絞り込み方法があるので気になる場合は調べてみましょう)
並び替え(ORDER BY)
明示的に並び順を指定することで、意図した順番で結果が返ってきます。
「売り上げた日時で並べたい」「売上金額順に並べたい」などです。
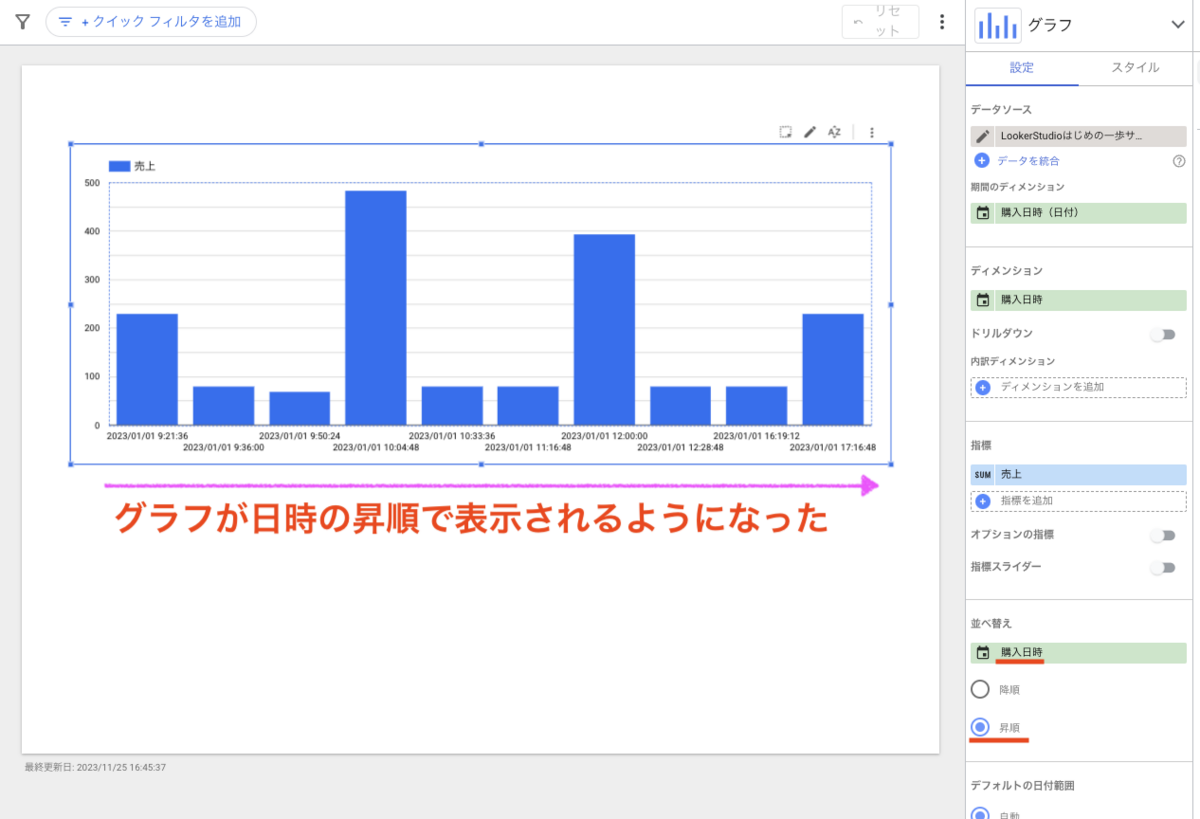
店舗 A のデータに対して、売り上げた日時で並べてみましょう。並び順の指定には、ORDER BY 句を用います。
昇順(過去->未来)で並べる場合: ASC
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
ORDER BY purchased_at ASC
;
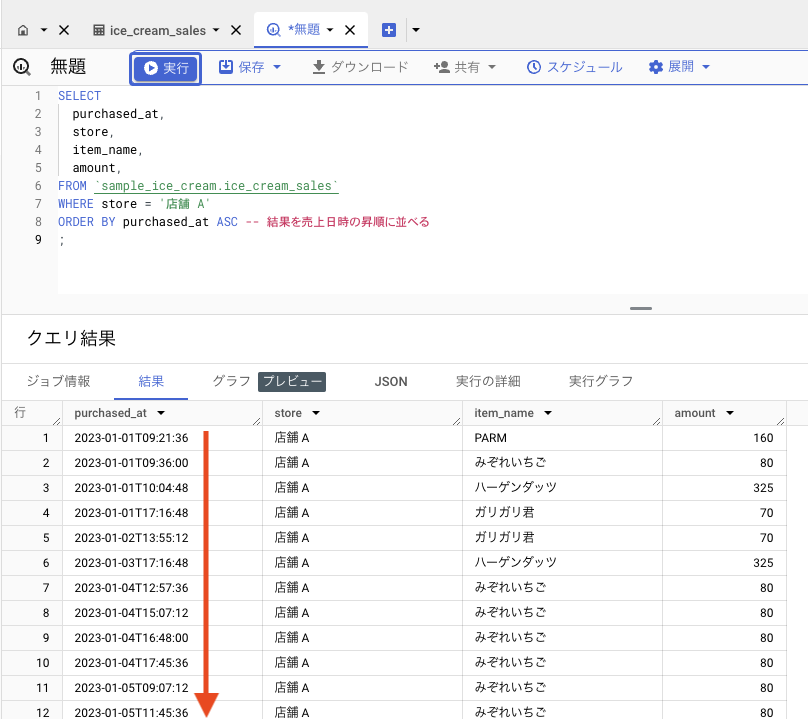
クエリ結果が売上日時の昇順で並びました。
降順(未来->過去)で並べる場合: DESC
SELECT
purchased_at,
store,
item_name,
amount,
FROM `sample_ice_cream.ice_cream_sales`
WHERE store = '店舗 A'
ORDER BY purchased_at DESC
;
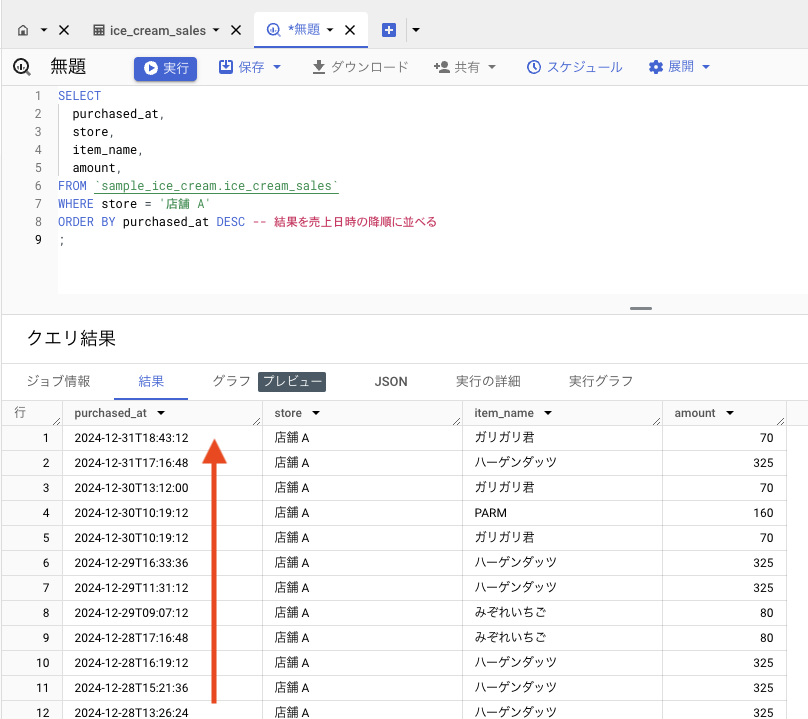
クエリ結果が売上日時の降順で並びました。
テーブル同士をつなげる
さて、データベースでは、以下のように、関連する別のデータが別のテーブルになっている状況を良く見かけます。
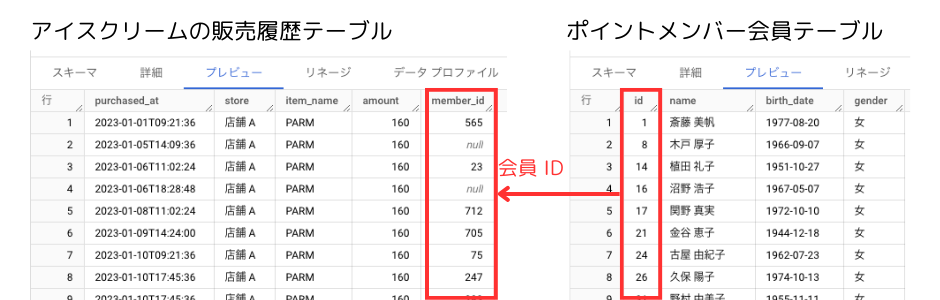
アイスクリームの販売履歴テーブル
- purchased_at: 購入日時
- store: 店舗
- item_name: 品名
- amount: 金額
- member_id: ポイントメンバー会員 ID
ポイントメンバー会員テーブル
- id: ポイントメンバー会員 ID
- name: 氏名
- birth_date: 生年月日
- gender: 性別
アイスクリームの販売履歴テーブルには、ポイントメンバー会員の ID があり、ポイントメンバー会員の情報はポイントメンバー会員テーブルで持っているような、いわゆる「リレーション(関係・関連)」の構造です。
(冒頭で出てきた「リレーショナルデータベース」の醍醐味でもあります)
これらを繋げてデータを取得してみましょう。
テーブル作成
以下の練習用データをダウンロードし、テーブル作成と同じ要領で BigQuery にインポートしテーブルを作成してください。
BigQueryはじめの一歩サンプルデータ - 2. ポイントメンバー会員(スプレッドシート)
- データセット: sample_ice_cream(アイスクリームの販売履歴テーブルと同じ)
- テーブル名: members
- スキーマ:
- id: INTEGER
- name: STRING
- birth_date: DATE
- gender: STRING
- スキップするヘッダー行: 1
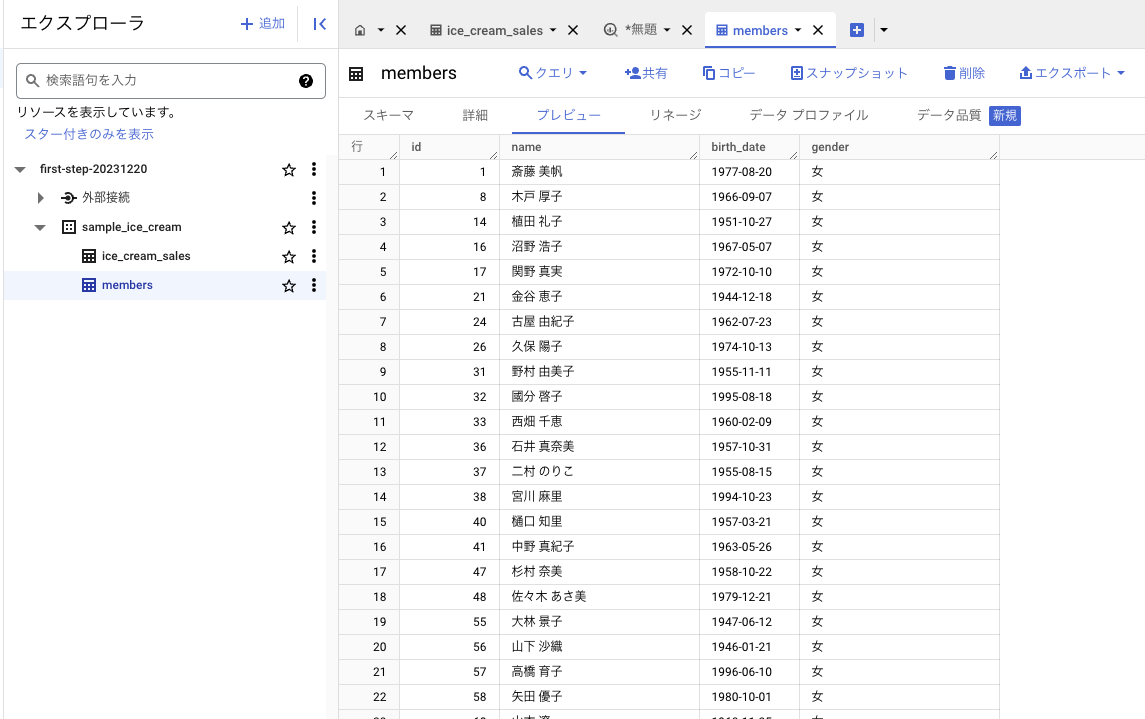
ポイントメンバー会員テーブルが作成できたら、テーブル同士をつなげてみましょう。
テーブルを結合する(JOIN)
テーブルとテーブルを繋げることを「結合」といい、クエリでは JOIN 句を用います。
SELECT
sales.purchased_at,
sales.store,
sales.item_name,
sales.amount,
sales.member_id,
members.name,
members.birth_date,
members.gender,
FROM `sample_ice_cream.ice_cream_sales` sales
INNER JOIN `sample_ice_cream.members` members ON sales.member_id = members.id
;
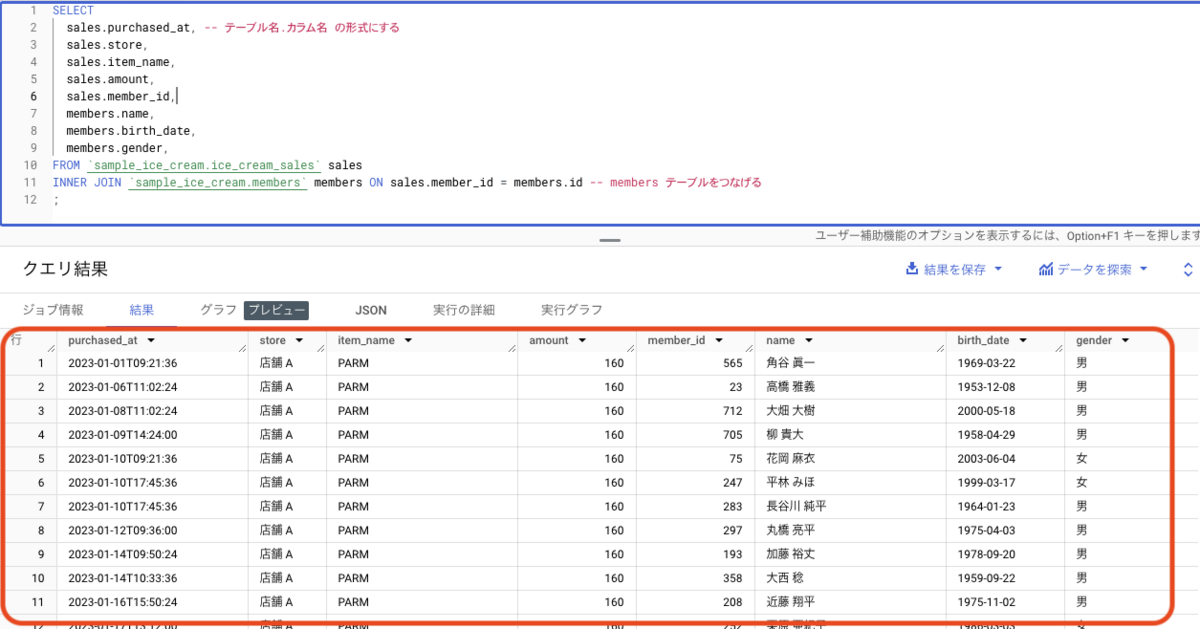
JOIN 句の文法は以下になっています
SELECT
テーブル名.カラム名,
FROM 結合元テーブル名 (エイリアス)
INNER JOIN 結合したいテーブル名 (エイリアス) ON 結合元テーブル名.結合元のメンバーID = 結合したいテーブル名.メンバーID
もう一つ違う点は、「エイリアス」という短縮名を定義して使っている点です。
FROM `sample_ice_cream.ice_cream_sales` sales
INNER JOIN `sample_ice_cream.members` members
ON sales.member_id = members.id
エイリアスを定義すると、その後のテーブル名の表記を、短くしたり分かりやすくできます。(任意の名前をつけられます)
もしもエイリアスを使わないとすると、以下のようなクエリになります。
SELECT
`sample_ice_cream.ice_cream_sales`.purchased_at,
`sample_ice_cream.ice_cream_sales`.store,
`sample_ice_cream.ice_cream_sales`.item_name,
`sample_ice_cream.ice_cream_sales`.amount,
`sample_ice_cream.ice_cream_sales`.member_id,
`sample_ice_cream.members`.name,
`sample_ice_cream.members`.birth_date,
`sample_ice_cream.members`.gender,
FROM `sample_ice_cream.ice_cream_sales`
INNER JOIN `sample_ice_cream.members` ON `sample_ice_cream.ice_cream_sales`.member_id = `sample_ice_cream.members`.id
;
冗長で、パッと見てもわかりにくいですよね。エイリアスを定義するとスッキリと書けるのでオススメです。
覚えておきたい INNER JOIN と LEFT JOIN
さて、JOIN 句にはいくつか種類があります。最低限覚えておきたいのは INNER JOIN と LEFT JOIN です。
- INNER JOIN
- 結合元テーブルのレコード(行)に対して、結合したいテーブルのレコードがマッチングしたものだけを結果として返す
- LEFT JOIN
- 結合元テーブルのレコードに対して、結合したいテーブルのレコードがマッチングしないものでも結果として返す
アイスクリームの販売履歴のデータには member_id というカラム(列)がありますが、必ずしも会員 ID が入っているわけではありません。
ポイントメンバー会員ではない人の購入データもあるということですね。会員 ID の無い場合は null と表示されています。
この時に、INNER JOIN と LEFT JOIN の違いを見てみましょう。
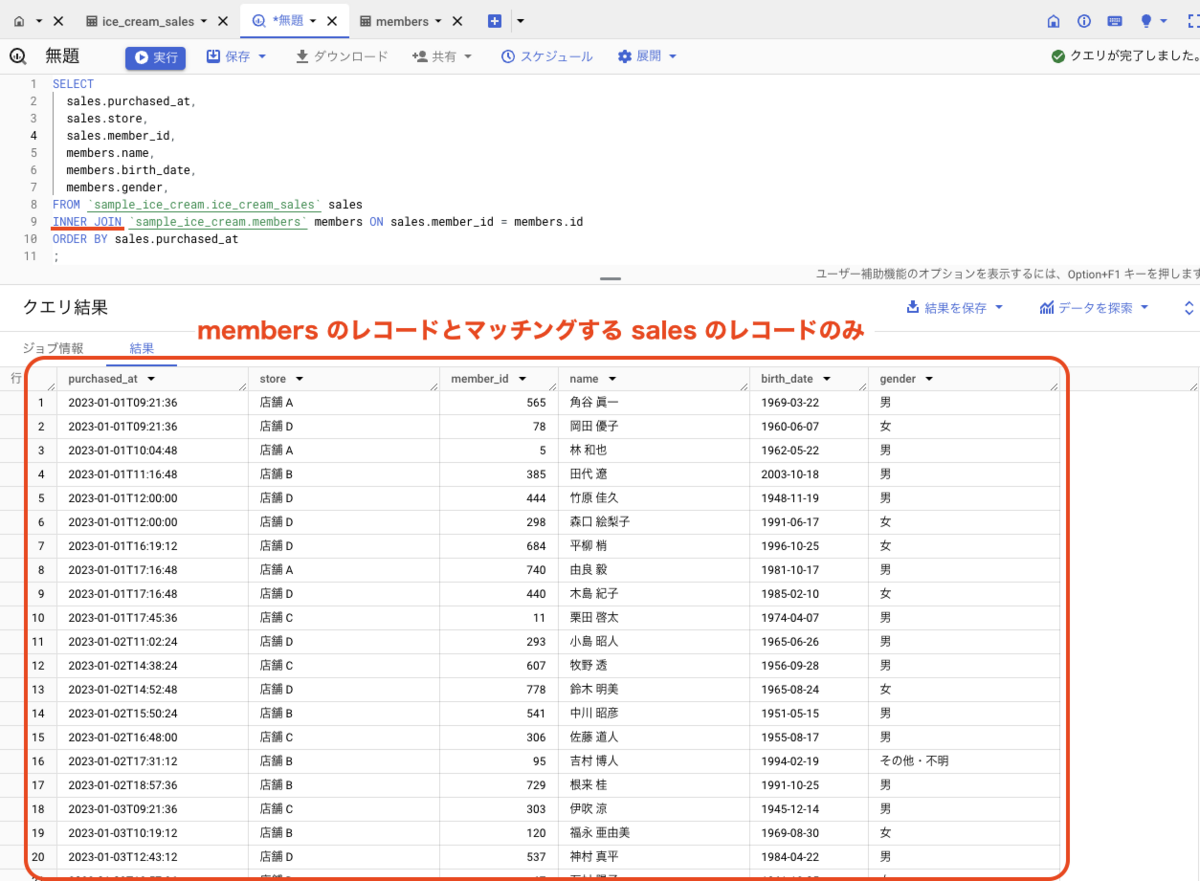
INNER JOIN
INNER JOIN を用いると、結合元テーブルのレコード(行)に対して、結合したいテーブルのレコードがマッチングしたものだけを結果として返します。
つまり、sales.member_id に値が入っていて、なおかつ members.id と合致したレコードのみが結果として返ることになります。
SELECT
sales.purchased_at,
sales.store,
sales.member_id,
members.name,
members.birth_date,
members.gender,
FROM `sample_ice_cream.ice_cream_sales` sales
INNER JOIN `sample_ice_cream.members` members ON sales.member_id = members.id
ORDER BY sales.purchased_at
;
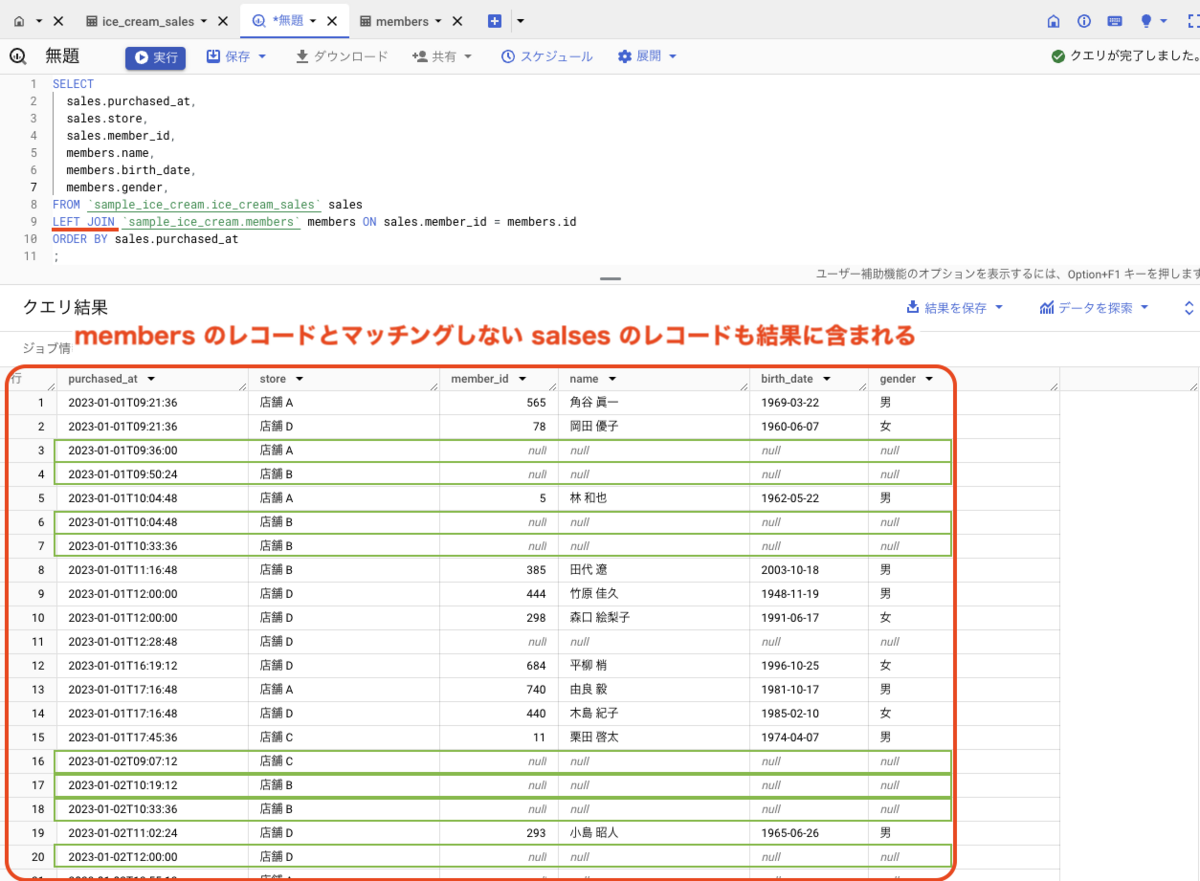
LEFT JOIN
LEFT JOIN を用いると、結合元テーブルのレコード(行)に対して、結合したいテーブルのレコードがマッチングしなかったものも結果として返します。
つまり、sales.member_id が NULL のレコードや、members.id と一致しない sales のレコードも結果として返ることになります。
SELECT
sales.purchased_at,
sales.store,
sales.member_id,
members.name,
members.birth_date,
members.gender,
FROM `sample_ice_cream.ice_cream_sales` sales
LEFT JOIN `sample_ice_cream.members` members ON sales.member_id = members.id
ORDER BY sales.purchased_at
;
INNER JOIN と LEFT JOIN のどちらを使うかは、データの特徴や得たい結果を考慮して選択しましょう。そのために、クエリを書く前にデータをしっかり目視で眺めるというのも大切です。
データを集計する
最後に、データを集計してみましょう。集計は、値を合計したり、平均を出したりなどすることです。
データをまとめて、集計する(GROUP BY)
データを集計するには GROUP BY 句を用います。
SELECT
store,
SUM(amount) as total_sales,
COUNT(amount) as number_sales,
AVG(amount) as average_sales,
MIN(amount) as max_unit_price,
MAX(amount) as min_unit_privc,
FROM `sample_ice_cream.ice_cream_sales`
GROUP BY store
ORDER BY store
;
GROUP BY store とすることで、「店舗ごとに集計する」という意味になります。
GROUP BY を指定したら、SELECT 句で「合計」や「平均」など、どんな計算をしたいかを指定すれば、店舗ごとに集計することができます。
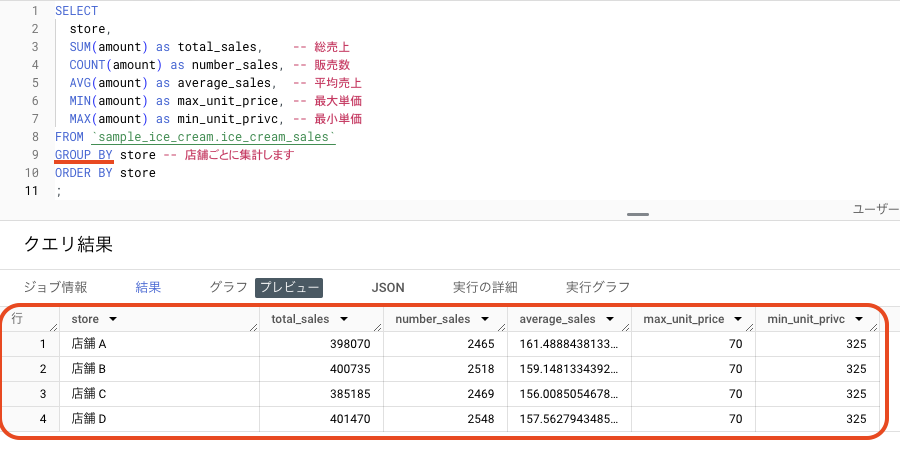
このクエリでは、店舗ごとの全期間の売上や販売数などを集計しています。
結果を見てみると、店舗 B は店舗 A よりも売上は多いですが、平均売上は低いです。つまり、店舗 B は店舗 A よりもお安めのアイスが売れていて、単価よりも販売数で稼いでいる。というのが相対的にわかります。
こんなふうに、集計するとこれまではただの履歴でしかなかったデータが意味を持ち、そこから発見が生まれます。データを分析することの醍醐味ですね。
GROUP BY についての、BigQuery における SUM や AVG などの集計関数は以下に一覧がありますので参考にしてください。
集計関数 / レガシー SQL 関数と演算子 - BigQuery, Google Cloud
データから意味や価値を引き出す
データ分析とは、データから意味や価値を引き出すことです。たくさんの情報を整理して意味を見つけ出すプロセスと言えるでしょう。
大量のパズルピースが散らばっている状態で、それらを組み合わせて全体の絵を作り上げるようなものです。
データ分析を行うことで、ビジネスや研究などの分野で重要な判断材料を得ることができます。例えば、商品の売れ行きや広告の効果を分析して、より効果的な戦略を立てることができます。
BigQuery を用いれば、大量のデータを蓄積できること、そしてそれらを分析することが可能です。
BigQuery でやれることはまだまだ沢山あり、今回紹介したことは一部に過ぎませんが、これを期に実際に生きたデータに触れることで、より理解も深められると思います。
ここまで実際に手を動かしてみて、なんとなくの使い方が理解いただけたら幸いです。
現在 back check 開発チームでは一緒に働く仲間を募集中です。
herp.careers